




1.下载地址
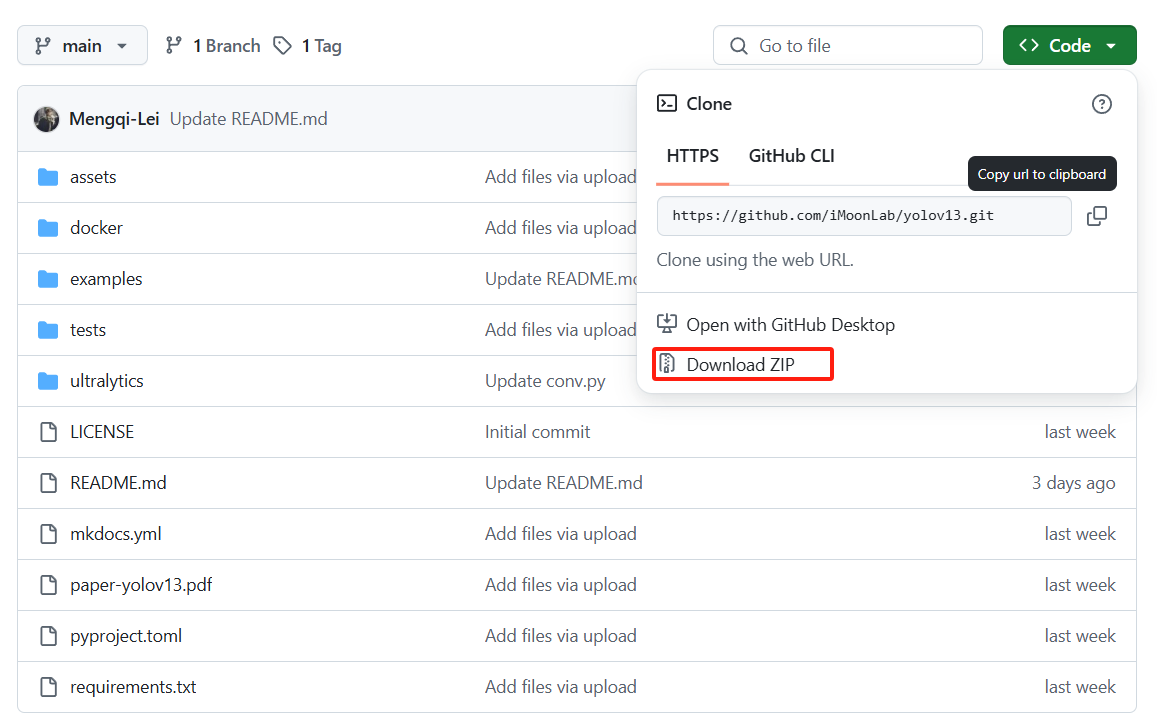
2.创建环境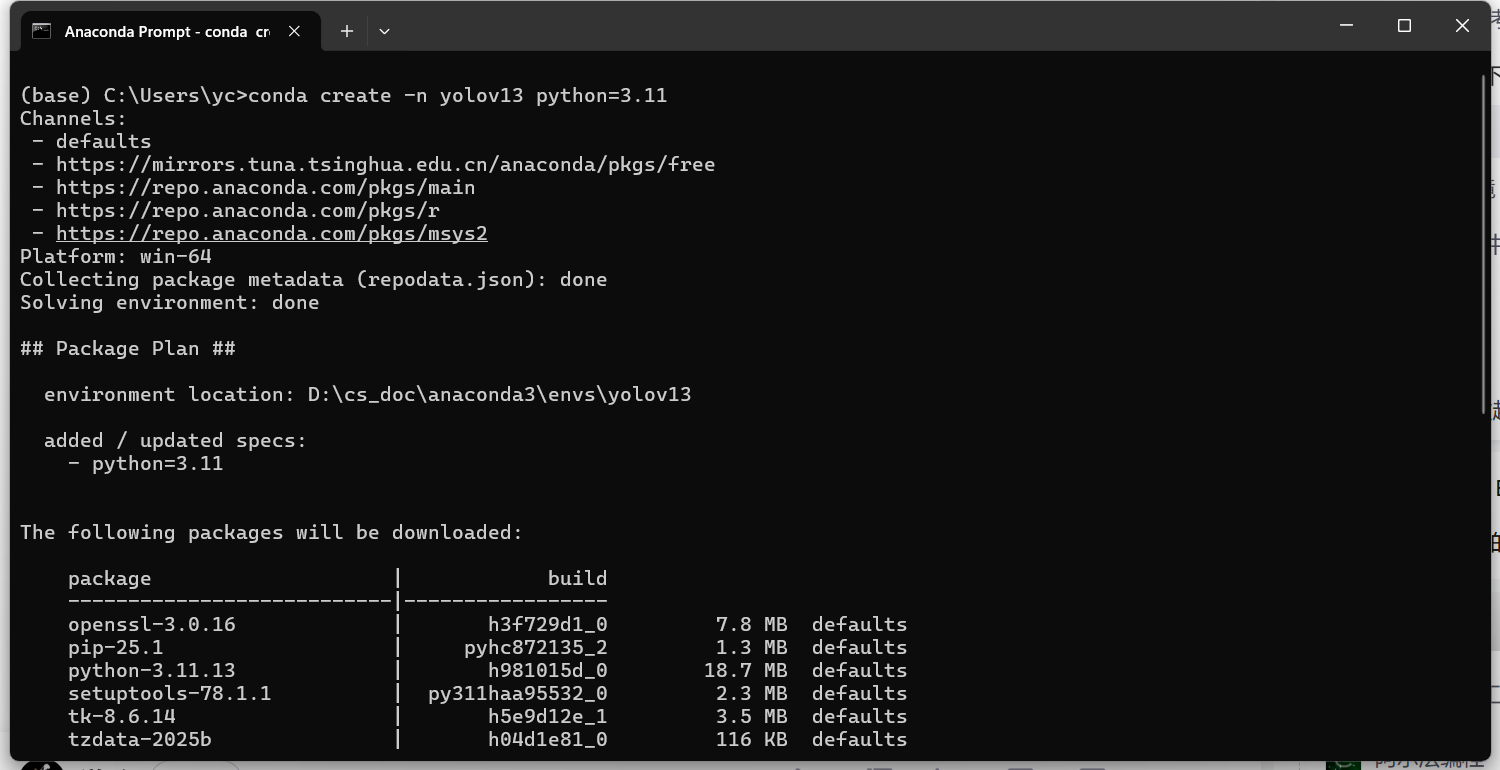
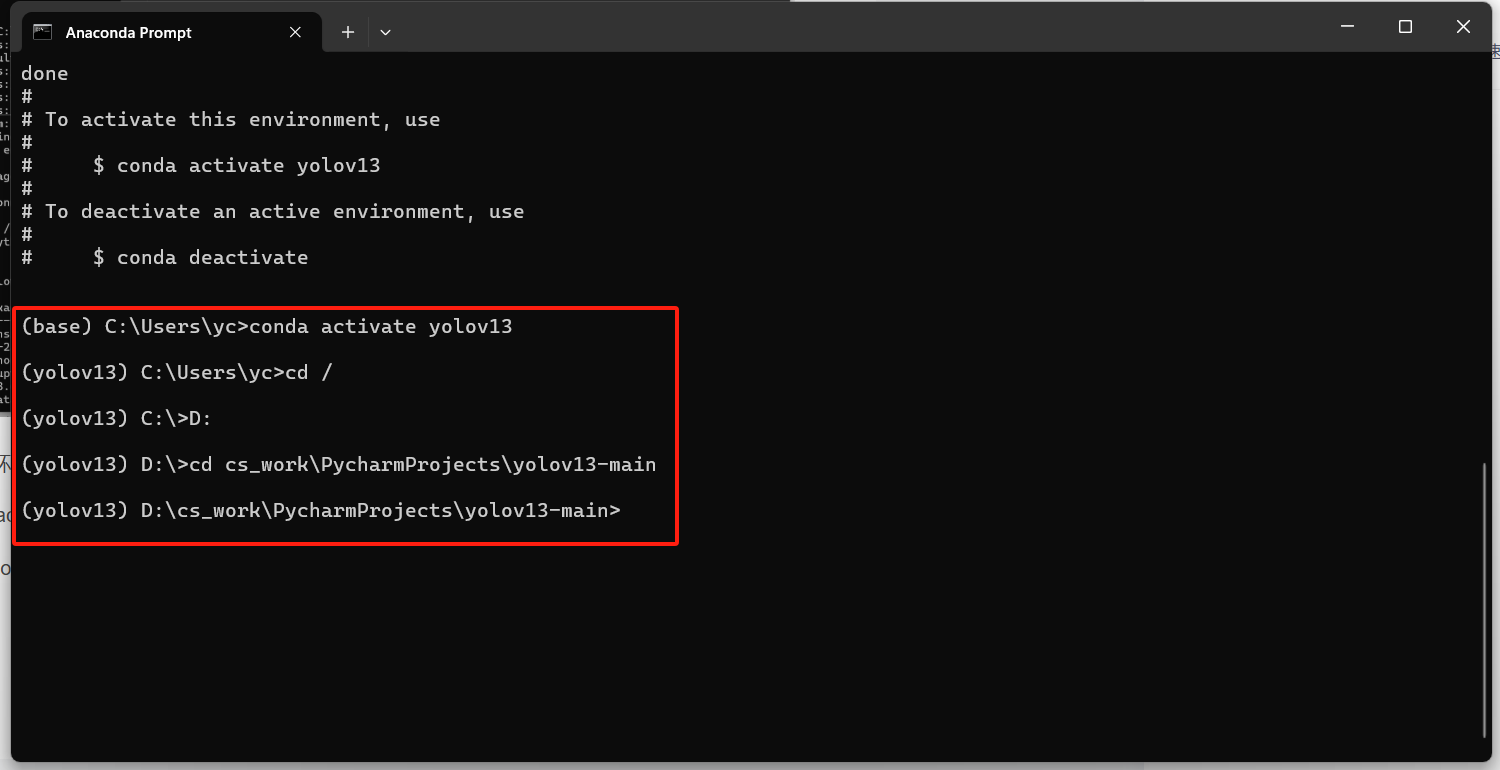
3.安装完成后激活环境
conda activate yolov13进入yolov13-main目录,我的文件在d盘,所以先切换根目录。
4.搭建环境
安装pytorch
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 -f https://mirrors.aliyun.com/pytorch-wheels/cu1215.下载flash_attn包的whl文件,将其放在yolov13-main文件夹内
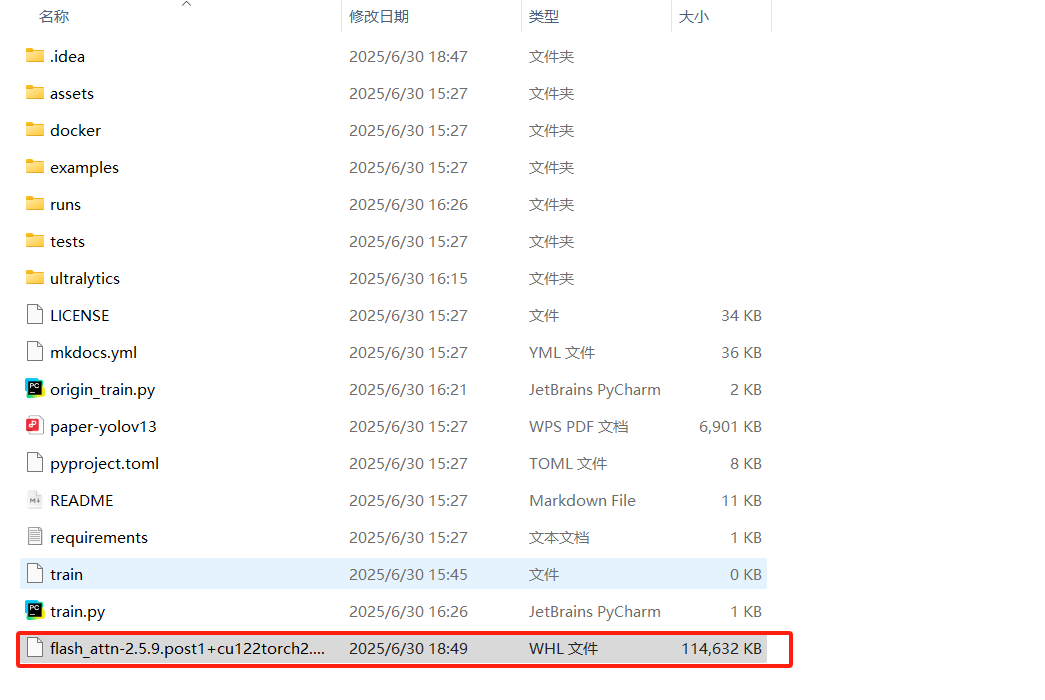
6.安装flash_attn包的whl文件
pip install flash_attn-2.5.9.post1+cu122torch2.3.1cxx11abiFALSE-cp311-cp311-win_amd64.whl7.安装requirements.txt文件的环境
pip install -r requirements.txt8.编译文件
pip install -e .编译成功就会像下面这样
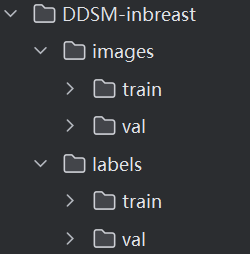
9.数据集设计就是常规的yolo数据集,目录结构如下
10.数据集配置文件如下
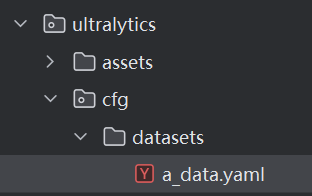
path: D:\cs_work\PycharmProjects\dataHandle\data\raw_breast_data\split_dataset\DDSM-inbreast
train:
- images/train
val:
- images/val
names:
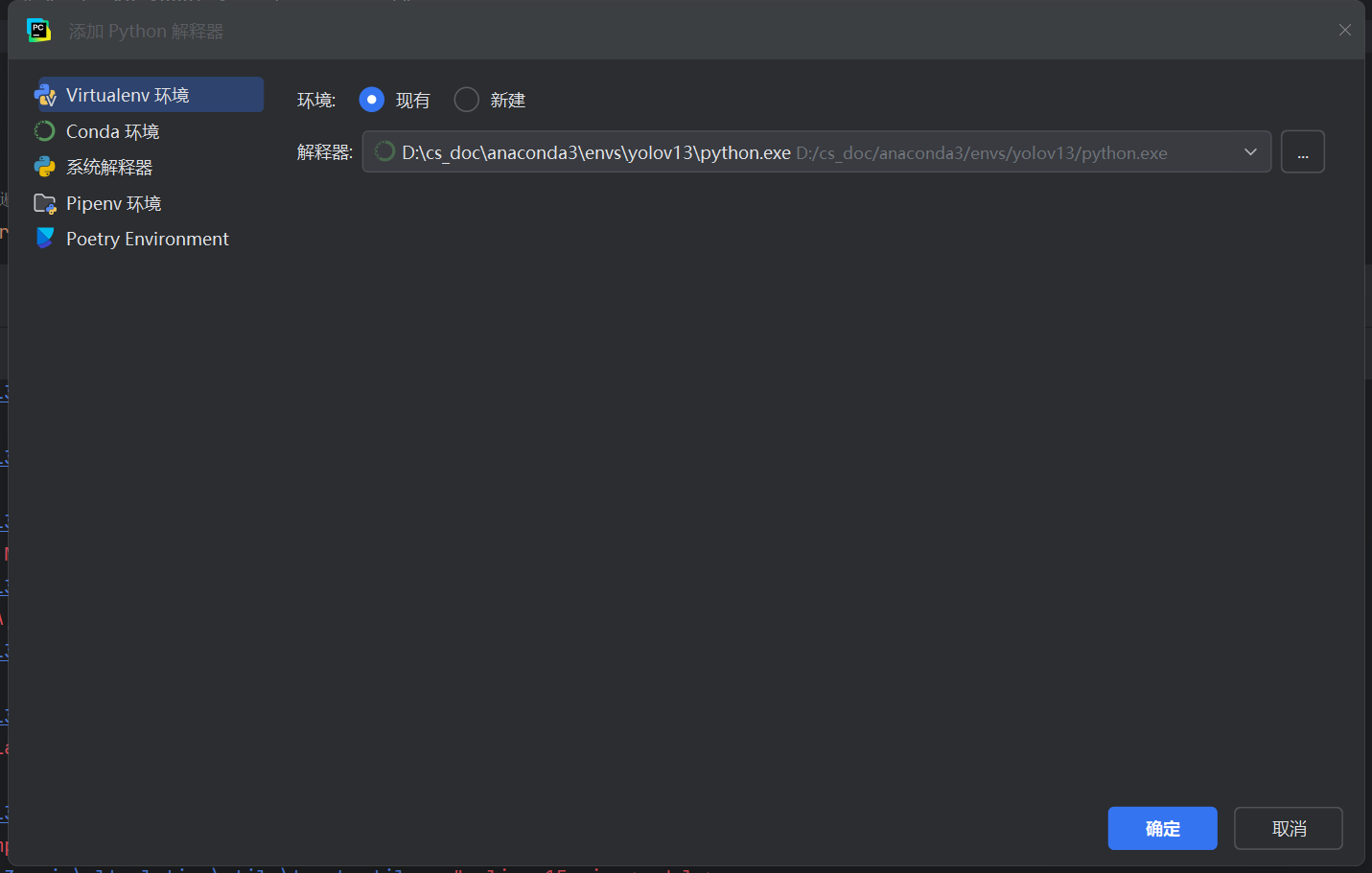
0: tumour11.为编译器增加我们创建好的yolov13解释器
12.在运行程序之前,先打开requirements.txt,如果有缺少的依赖或者版本存在问题的就按照pycharm的指示进行安装或更新。
13.训练文件代码如下,仅供参考!值得注意的是我是没有加载预训练模型的!这部分根据个人需求来设计。
from torch.optim import AdamW
from ultralytics import YOLO
# 定义要测试的模型版本
yolo_versions = [
# "yolo12.yaml"
# "yolo12_ddsm_vindr-MCAM.yaml",
# "yolo12_ddsm_vindr-A2C2f_MCAM.yaml"
# "yolo12_ddsm_vindr-SPDConv.yaml"
# "yolov12-BiFormer.yaml",
# "yolov12-A2C2f_BiFormer.yaml"
# "yolov12-A2C2f_AssemFormer.yaml"
# "yolo12-PConv.yaml"
# "yolo12-AsymFusion.yaml"
"yolov13.yaml"
]
# 遍历每个模型版本,进行训练
for version in yolo_versions:
print(f"正在训练模型:{version}")
# 加载 YOLO 模型,不加载预训练权重
model = YOLO(version)
# 训练模型
results = model.train(
data="a_data.yaml",
epochs=300,
imgsz=640,
batch = 4,
device=[0], # 使用 GPU 0
workers=0,
cache=True,
lr0 = 0.001,
lrf = 0.1,
optimizer='AdamW',
close_mosaic=0,
rect=True,
save_period=1,
pretrained=False, # ⚠ 这里不加载预训练模型
project='results/train/origin', # 设定保存结果的文件夹路径
name=f'{version.split(".")[0]}', # 每个版本单独存储
)
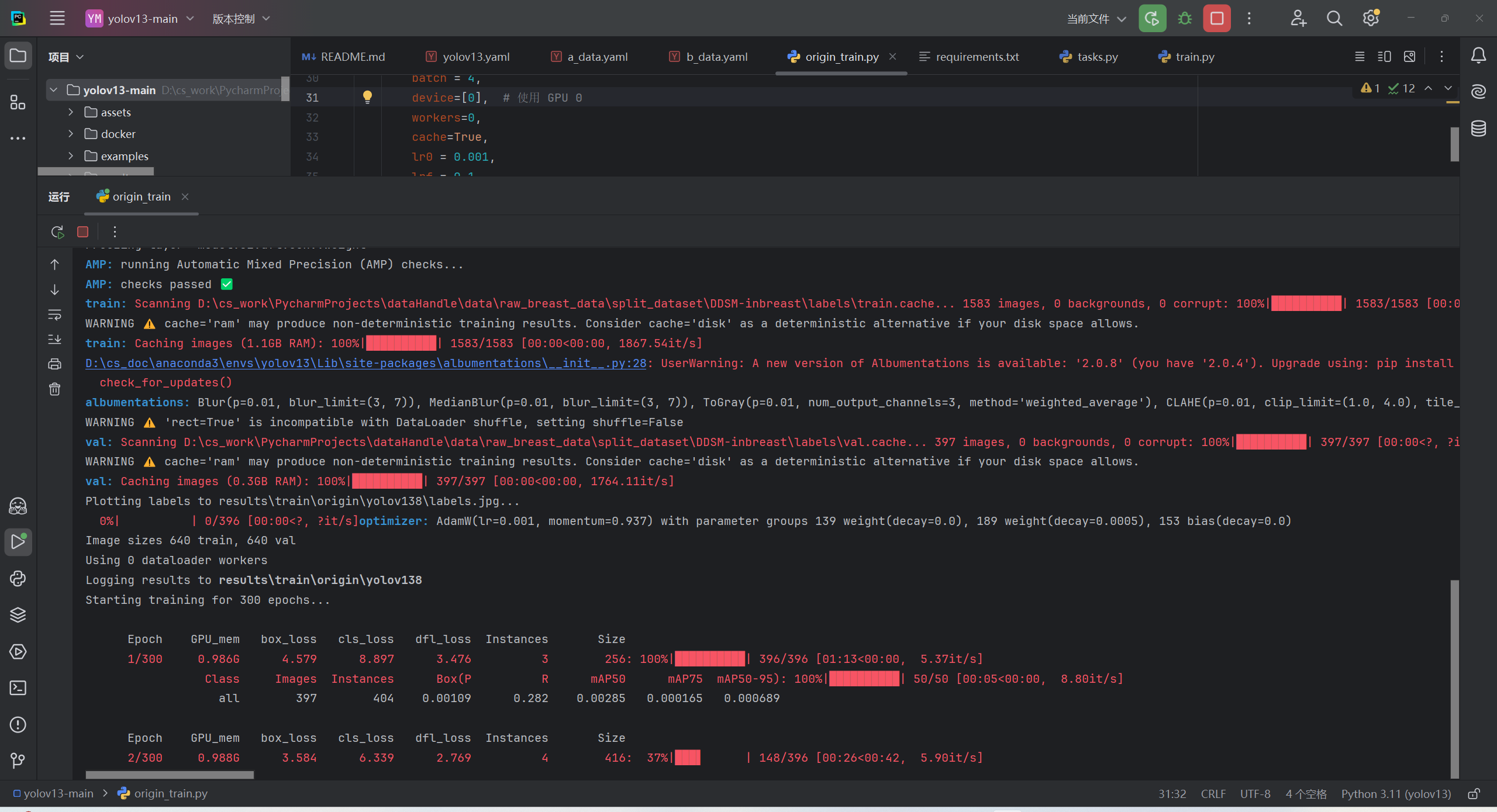
print(f"✅ 模型 {version} 训练完成,结果已保存!\n\n")14.训练过程展示


















 3097
3097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









