



在数字化服务时代,企业普遍通过FAQ文档和帮助中心来提升客户自助服务效率。
但现实却令人尴尬:大量用户反馈FAQ文档“找不到答案”,点击率和转化率持续低迷。这不仅浪费企业资源,还可能间接导致用户流失。
为何精心整理的FAQ文档沦为“摆设”?问题的核心在于:内容未精准匹配用户需求。
用户需要的是“快速定位问题-理解解决方案-立即应用”的一站式体验,而传统FAQ文档往往因结构混乱、搜索低效、内容陈旧等问题,与用户真实需求脱节。
本文将深入分析FAQ文档被忽视的根源,并提供一套低成本、高转化的优化策略,助力企业打造真正“以用户为中心”的帮助中心。
一、为什么FAQ文档没人看?
❌1.搜索体验差,找不到想要的答案
❌2.结构混乱,难以快速定位问题
❌3.界面不友好,阅读体验差
❌4.缺乏实时更新,内容过时

二、如何构建精准匹配用户需求的FAQ文档?
工欲善其事,必先利其器。 面对FAQ文档的优化难题,企业无需从零开始“造轮子”——借助智能知识库工具HelpLook,即可快速搭建零代码、高适配的帮助中心。
HelpLook不仅支持FAQ文档的模板化创建和智能管理,更通过四大核心策略直击用户痛点:搜索精准化、场景化分类、多端无缝适配、数据驱动优化,让FAQ文档真正“活起来”。
🌟策略1:优化搜索与智能推荐——打造“问答机器人”体验
-
AI智能搜索:HelpLook的AI智能搜索功能通过自然语言处理(NLP)和主流AI大模型(如DeepSeek、文心一言、ChatGPT、豆包等)的结合,能够快速理解用户意图并提供精准的搜索结果。用户只需输入关键词或问题,AI即可基于知识库内容,自动整理出相关答案和内容索引,显著提高检索效率。
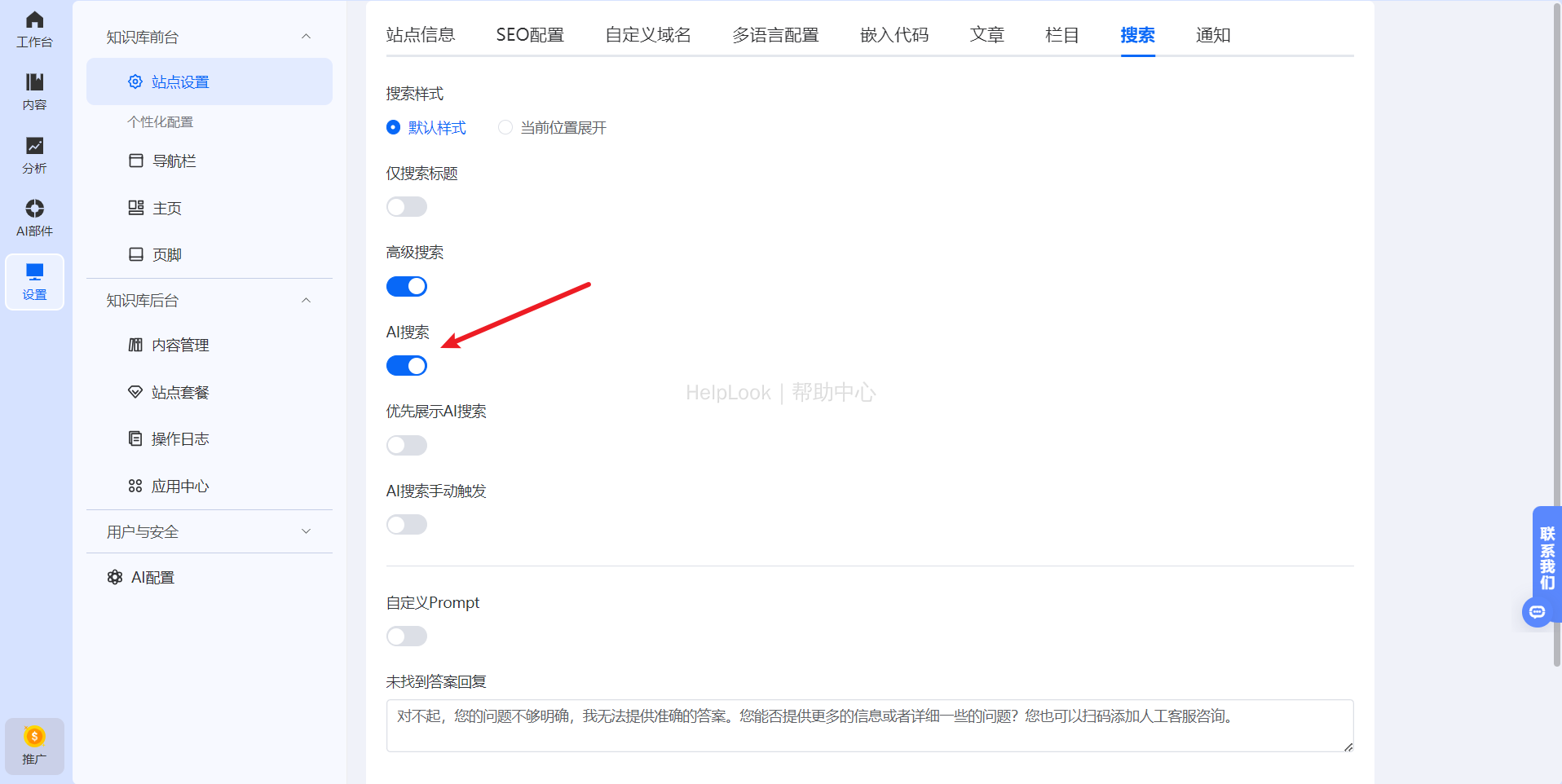
-
热门推荐:HelpLook可以通过设置热门搜索和热门内容置顶功能,帮助用户更高效地获取所需FAQ文档。
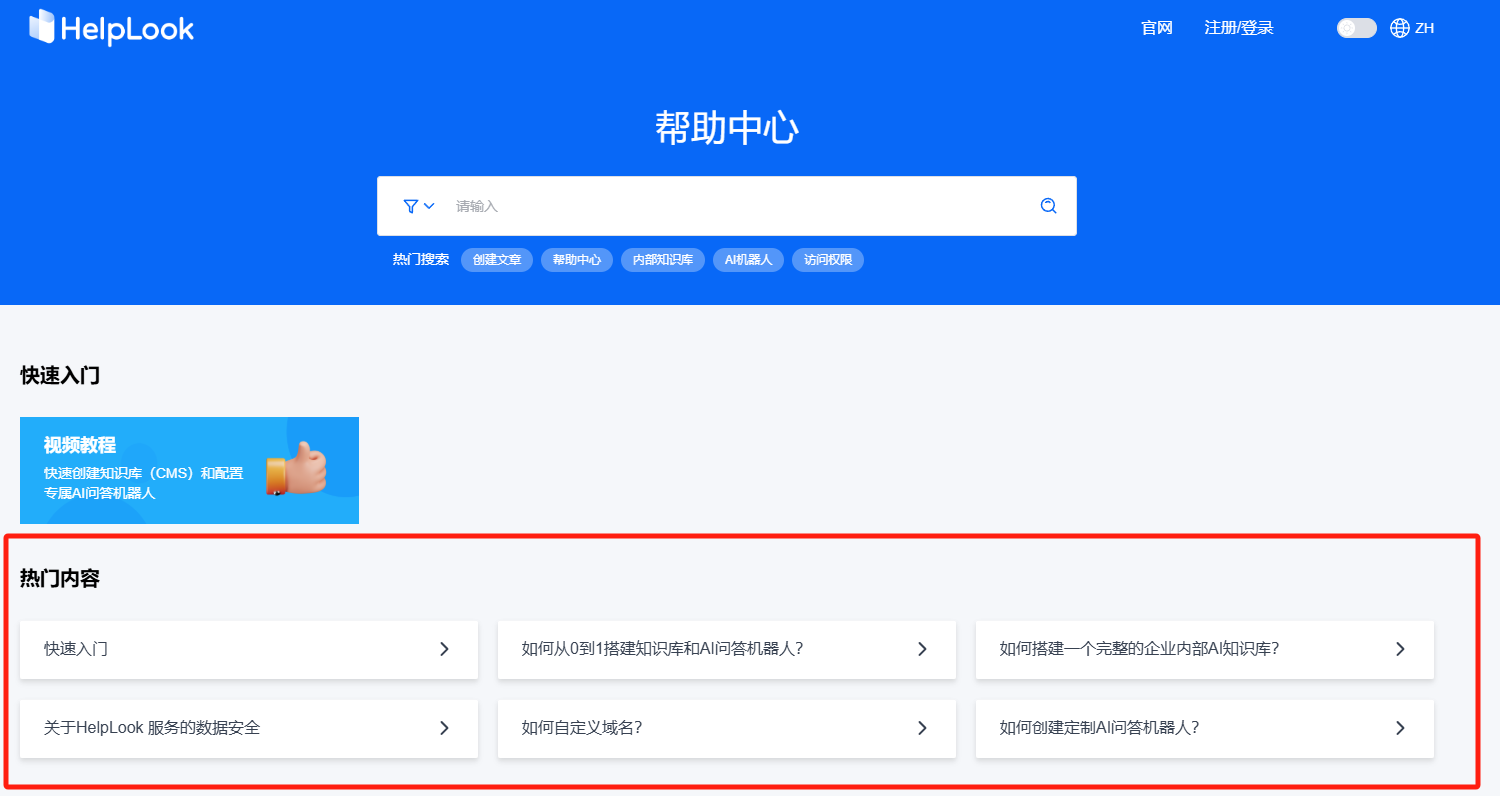
🌟策略2:文档分类与标签管理——让结构“场景化”
-
标签精细化:通过HelpLooK的标签管理功能,可以帮助用户更好地组织和分类内容,提升知识库的管理效率。通过标签,让用户可以快速定位和检索相关文档,确保信息的有序性和可访问性。
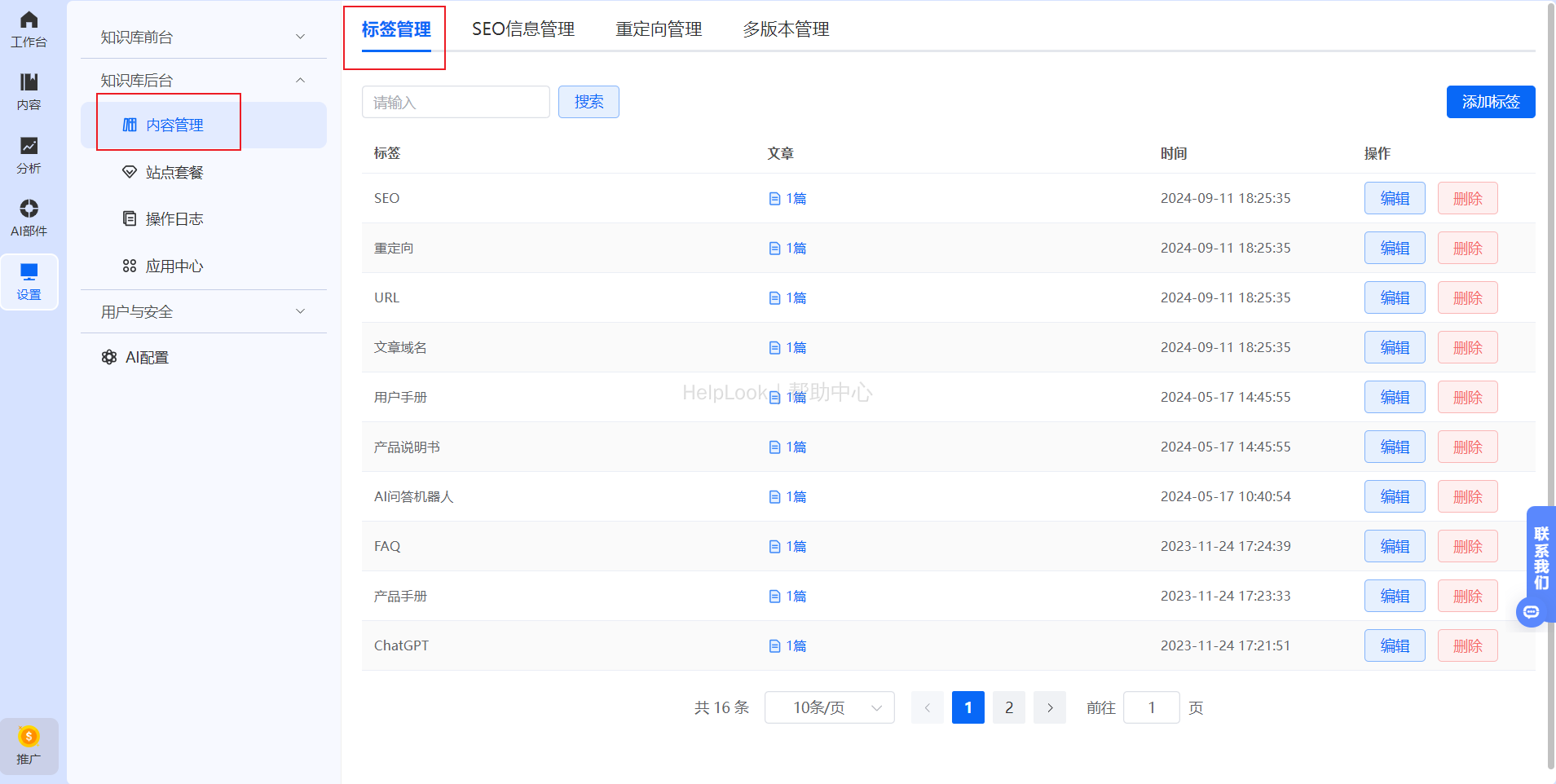
-
多格式辅助理解:HelpLook支持批量导入各种格式的文档,并按主题或功能分类。在文本基础上,您还可以插入图片、视频、GIF等多种格式的内容,丰富FAQ文档的内容。针对复杂流程嵌入流程图、GIF动图或短视频(如“5秒看懂权限设置”),降低用户理解成本。
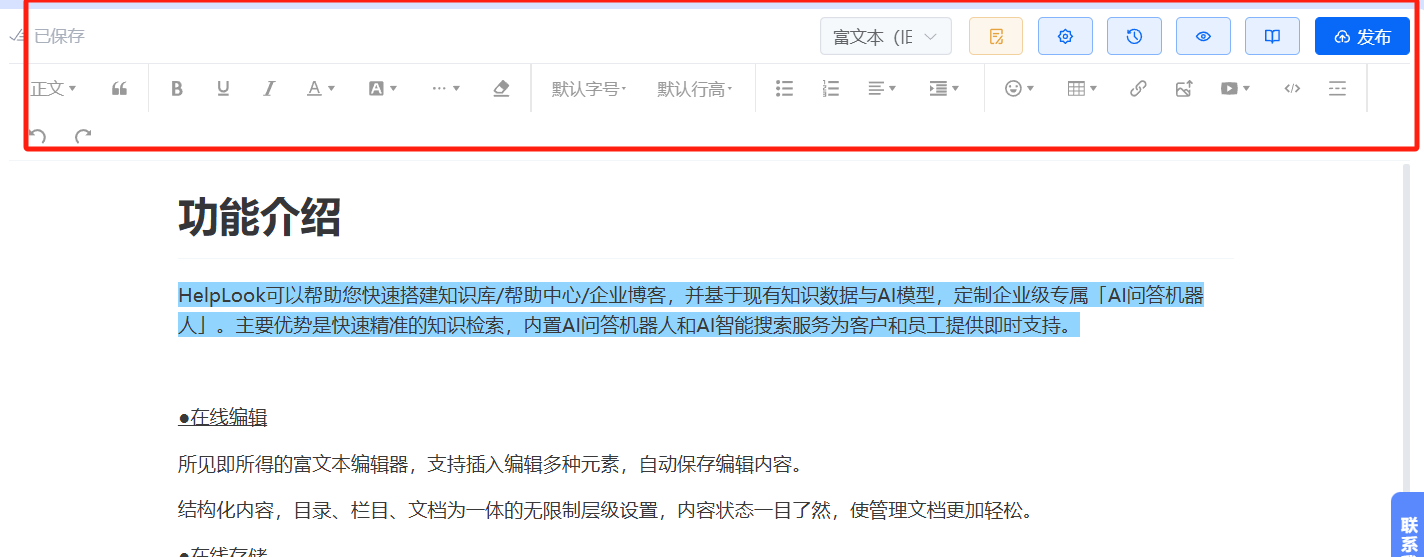
🌟策略3:多场景适配——覆盖全渠道用户
-
多端适配:增加手机端和电脑端多端适配。HelpLook支持将帮助中心嵌入网站、内嵌到APP、小程序等平台。用户可以随时随地获取所需的信息。
-
多语言支持:HelpLook支持创建和管理多语言站点,满足全球用户的需求。并且支持根据用户浏览器语言自动跳转至对应的语言站点,提升用户的访问体验。
🌟策略4:持续更新与数据分析——用数据驱动优化
-
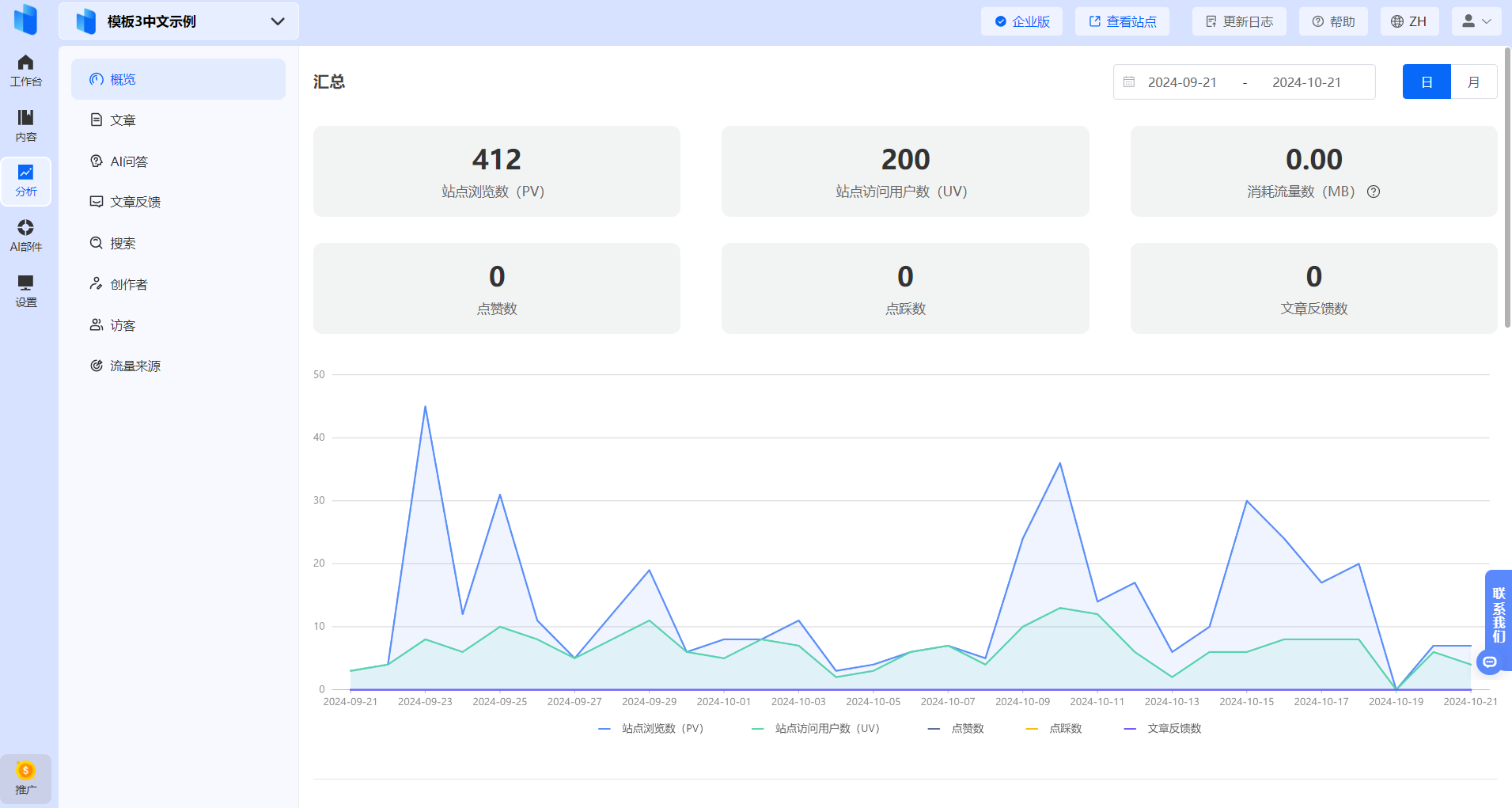
数据分析支持:HelpLook可以分析数据概览,包括站点浏览数、访问用户数等关键指标。通过每日或每月的站点数据追踪,可以掌握站点浏览数、访问用户数以及文章反馈数等关键指标。这些数据帮助了解用户的阅读习惯,优化内容策略。
-
持续改进优化:HelpLook可以根据知识库使用情况和客户行为的数据和反馈,了解客户需求,进行持续改进和优化。通过查看用户的搜索词和点击的文章,可以洞察用户的需求和关注点。如果用户搜索但未找到答案,可以及时补充相关内容,确保知识库的全面性和准确性。
三、总结与建议
一份高效的帮助中心,本质是“用户需求”与“企业服务”的精准对接。它需要:
👉🏻找得到:通过场景化分类与智能搜索,精准定位用户需求;
👉🏻看得懂:借助简洁排版与图文结合,直观呈现解决方案;
👉🏻用得上:依托AI智能搜索与动态优化,即时匹配最佳答案。
选择HelpLook等智能知识库工具,帮助企业快速搭建高效的FAQ文档,让知识管理和用户自助服务变得更加简单、高效。与其让FAQ无人问津,不如用科技的力量让它真正发挥价值!

















 207
207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









