




本篇论文来自2022年的WSDM会议,主要聚焦了利用语言模型来进行流量预测问题,通过将流量预测问题转换为类似prompt的操作,提升流量预测问题建模的可拓展性和通用性。虽然目前在LLM的快速发展下,各个领域类似的工作已经较多地涌现出来,但该论文应该是较早探索这种范式的工作之一,部分方法依然值得参考借鉴。
Translating Human Mobility Forecasting through Natural Language Generation
1.Introduction
人的移动预测,如下一个位置预测任务和客流预测任务是许多领域的重要组成部分,包括人的移动理解和智慧城市应用。在文献中,人类移动预测总是通过时间序列预测框架来解决。在这个预测框架中,模型将数值移动数据(例如,每个兴趣点的访问次数)作为输入,并产生未来某个时间段的预测值。
在过去的几年里,移动预测模型的深度学习技术取得了重大进展。为了更好地捕捉人类的移动模式并预测未来的移动,这些模型考虑了历史移动记录之外的不同类型的上下文信息。例如,与兴趣点(poi)相关的语义类别被纳入人类移动预测模型,外部信息,如当地天气条件、星期几和时间,被纳入交通流量预测模型。
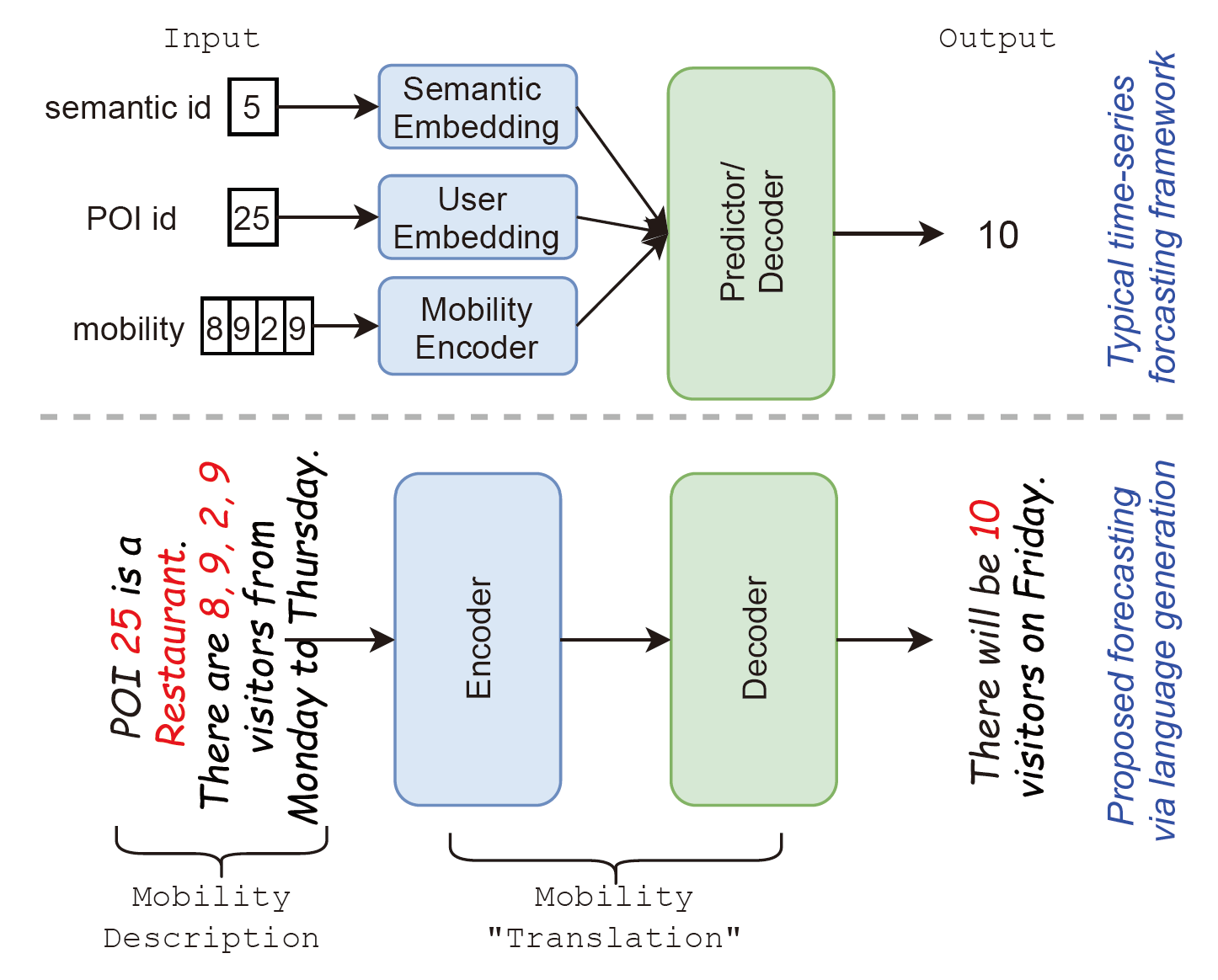
图1
图1的上半部分对这个预测工作流进行了简化和总结。多个数据源提供不同的信息(如POI id、语义信息和历史移动性),首先通过多个编码器或嵌入层来提取特征向量。在编码过程之后,提取/嵌入的上下文特征被连接起来,作为预测器/解码器的输入,从而得到预测结果(例如,图中示例中的10)。这个框架有两个主要的限制:(a)当有多个上下文时,连接操作可能不是合并不同数据源的最佳方式。当多个特征被添加到一起时,可能很难学习或捕获多个上下文的潜在相关性。(b)考虑到不同上下文的内在特性,预测模型需要多个不同的特征编码器或嵌入层来学习这些上下文的影响。这可能会显著增加预测模型的复杂性,使模型更难训练。
受自然语言处理模型发展的启发,神经网络翻译结构可能是解决上述限制的合适解决方案。假设所有类型的上下文信息和数据源都可以在一个自然语言句子中描述,那么预测模型只需要将句子作为输入,而无需使用不同的编码器或考虑如何组合不同的上下文。论文试图回答这个研究问题:能否以自然语言翻译的方式预测人类的移动性,同时保持较高的移动性预测性能?
与现有的人类移动预测方法不同,论文为移动性的“翻译”创建了一个非常规的流程,本质上是从历史移动到未来移动的转化。如图1的下半部分所示,论文提出通过语言生成管道进行预测的方法是序列到序列结构。通过移动描述,将移动数据和其他上下文信息转化为自然语言句子。然后,在移动翻译步骤中,将这些描述性句子作为输入,并生成一个表示预测结果的自然语言句子作为输出。
具体而言,论文提出了一种新的双分支架构SHIFT (translation Human Mobility Forecasting),用于上述通过语言生成流水线进行人类移动预测的核心移动“翻译”部分。该架构由一个主要的自然语言分支(NL)和一个辅助的移动分支(Mob)组成。NL分支被实现为一个序列到序列的结构来"翻译"移动描述,而Mob分支专注于学习移动模式。辅助分支的目的是进一步提高主分支生成移动预测的能力。论文主要创新点如下:
1)论文通过语言生成管道探索和开发了一种新的移动预测方法。这是第一项从自然语
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1016
1016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









