




 文章介绍了如何在Elasticsearch中利用Painless脚本语言处理keyword类型的时间字段,以便在DateHistogramAggregation中进行日期直方图统计。Painless是Elasticsearch5.0引入的安全、高性能的脚本语言,允许在DSL中进行复杂的逻辑处理。文中提供了具体的DSL示例和SpringDataRestTemplate的实现方式,展示了如何转换时间格式并进行范围查询以获取订单趋势图。
文章介绍了如何在Elasticsearch中利用Painless脚本语言处理keyword类型的时间字段,以便在DateHistogramAggregation中进行日期直方图统计。Painless是Elasticsearch5.0引入的安全、高性能的脚本语言,允许在DSL中进行复杂的逻辑处理。文中提供了具体的DSL示例和SpringDataRestTemplate的实现方式,展示了如何转换时间格式并进行范围查询以获取订单趋势图。
Elasticsearch 在 Date Histogram Aggregation 中使用 pipeline 教程
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
最近工作中一直在使用Elasticsearch 的 [agg] 相关操作,一直在做大数据量的统计和报表工作。然后碰到一个比较棘手的问题,就是还在统计过程发现一个年代比久远的索引,其中索引的时间类型是以keyword类型进行录入的,就导致如果通过时间进行聚合的时候就会有很多的ES的高级特性无法使用比如说,笔者一下要将的 Date Histogram Aggregation 日期直方图 ,这时候就需要用到ES为我们提供的一个很不错的高级特性,叫做 Script 和 painless
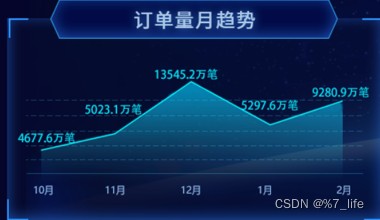
大致需求的样子要做出这样的数据进行
一、painless 是什么?
ElasticStack在升级到5.0版本之后,带来了一个新的脚本语言,painless。
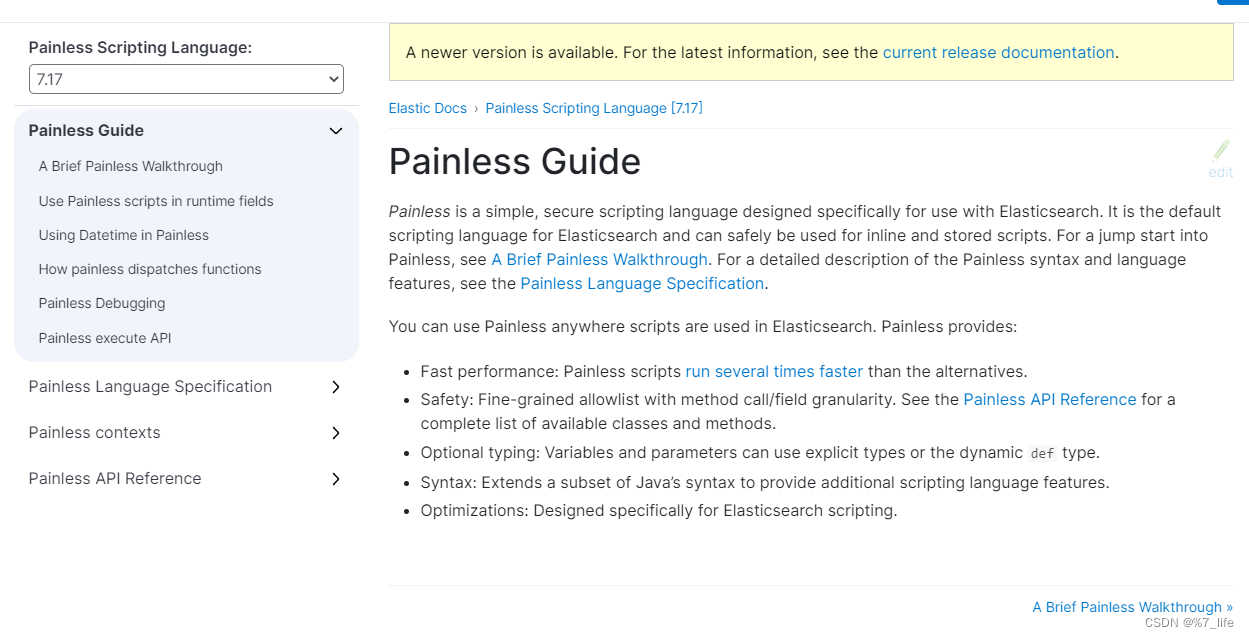
在7.17的最新文档以及给出了解释:
大致意思是:
**Painless是一种简单、安全的脚本语言,专为与 Elasticsearch 一起使用而设计。它是 Elasticsearch 的默认脚本语言,可以安全地用于内联和存储脚本。 **
- 高性能。painless在es的运行速度是其他语言的数倍。
- 安全。使用白名单来限制函数与字段的访问,避免了可能的安全隐患
- 可选类型。你可以在脚本当中使用强类型的编程方式或者动态类型的编程方式。
- 语法。扩展了java的基本语法以兼容groove风格的脚本语言特性,使得plainless易读易写
- 有针对的优化。这门语言是为elasticsearch专门定制的。
二、使用步骤
1.DSL
GET /你的索引名字/_search
{
"aggs": {
"avg_per_day": {
"date_histogram": {
"field": "order_date",
"interval": "day",
"script": {
"source": "return ZonedDateTime.from(ZonedDateTime.of(LocalDateTime.parse(doc['createTime'], DateTimeFormatte 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









