







接上一篇,果然不出我所料,都是错的
因为我采用的训练集中的非跳舞数据都不是vlog那种形式的,类型也与跳舞的差得很远,所以根据视频风格就区分出来结果了,因而是错误的,所以必须用统一的vlog形式的【尽管按道理说与视频格式形式无关,但是为了消除这种影响还是统一为好】
鉴于我分割了800多个dance视频,而nodance视频不够,所以还是将其中的有女人的视频放入nodance
一时半会也不好找0视频,人生艰难不是因为本就如此,而是每个人的路不一样。
早上一看磁盘满了,woc,一共都没有100G,这也太小了。我想要一个T的。。。。。
费劲删除了一点视频,重新将视频分成帧,其实作者这样的意图在于【视频读起来很慢,而图像较快】
训练结果如下:也不知好坏。
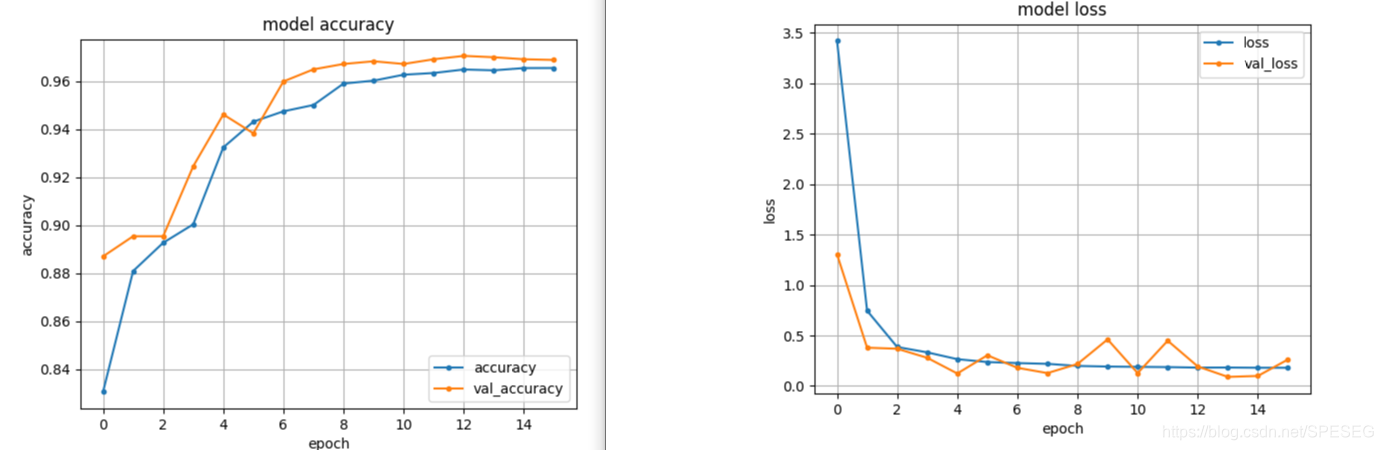
效果并不好啊,不是跳舞的仍旧有部分帧识别为跳舞,尽管这是根据一系列连续帧的推断。
如图下:prob都不到90%

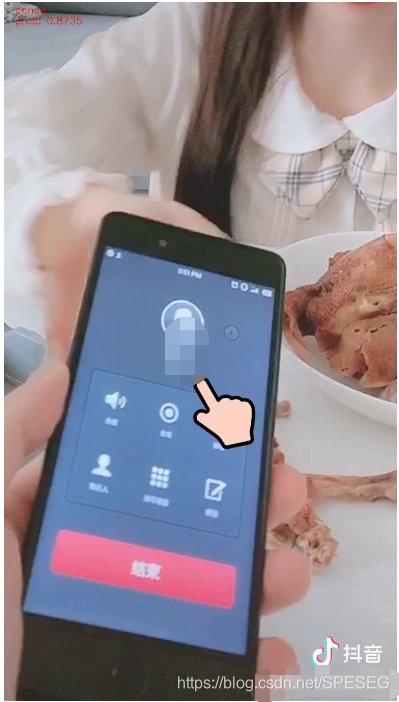
一共400帧出现了9帧类似的误识别,2.25%看起来也不错,但这只是个例,还没有大规模视频测试,所以我觉得仍旧不好。
针对这种复杂的行为【跳舞】其实并不容易,别看仅仅是二分类,0数据很难收集足够多,当然我们也可采取另一种方法,限制这种结果输出,这种trick可以加群交流。
我先吃个饭,再说。
另外有相关问题可以加入QQ群讨论,不设微信群
QQ群:868373192
语音图像深-度-学-习群



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











