







识别即是分类,分类的hello world自然是二分类了。哈哈哈
真考虑人体骨架什么的真的太复杂,因为人定义的概念是很宽泛的,比如说跳舞,简单的俩字,人体动作有什么???好几百种甚至上千种组合都有可能,比如韩舞,我可能被这玩意洗脑了,寡人女一号的戏准备找个会跳舞的妹子【咳咳,十八线见习导演】
几年前脸书发了3维卷积视频分类的一个东西,不说benchmark或landmark,或state of the art,但至少具有参考意义。
孤正是按这个的keras版本来的,原谅我不能喝咖啡【caffe】,虽有tf,但预处理我都没搞通,朕的打开方式总是与别人不一样。
经过老子深思熟虑才搞懂为啥子了,数据预处理始终是关键,这一步直接关系能不能用别人的东西,这一步没通,直接就game over了,与其费劲搞不定,不如再换一个,何必吊死一棵树。
视频分类我看源码还是根据图像来做的,每16个图像为一个batch,只不过是多了一个维度而已,例如:
input_shape=[16,112,112,3]当然16的位置也有放在3前面的,大同小异。与VGG网络的构建是类似的,卷积池化,卷积池化,还能有什么花样??CNN不就是如此吗?话说这里面如果用了RNN是不是效果会好一点??时间尺度上的信息会不会也很重要??
寡人的结果如下:简单的二分类,先就这样子吧,测试下试试效果如何。
寡人甚为郁闷,为何模型大小不一样??woc??
不亏是孤打下的江山,看起来效果好的一批【谁知道实际如何呢??】
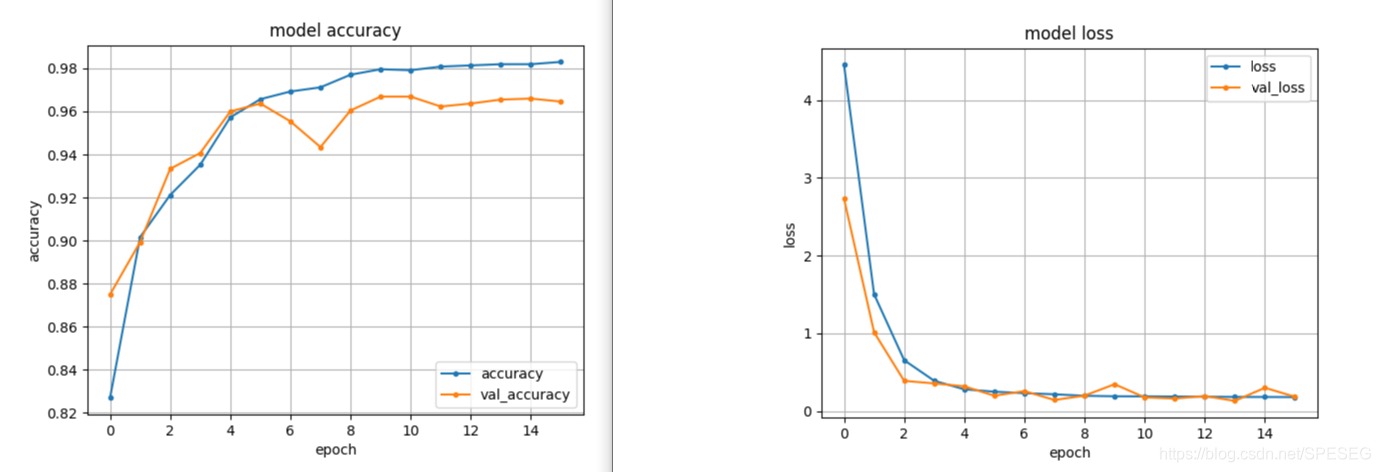
容我先用训练集或者测试集中的一个做下测试,虽说这是作弊,我看下作弊的效果,如果作弊都不行,那模型真的很垃圾。
我能说直接没有结果吗?哪怕是错误的结果显示出来也好啊,我太难了。。人生还是挺艰难的。

可能刚才那个视频太大了,读不出来,我先这么自我安慰下,先不考虑啥幺蛾子。
【我先开心开心,不管其他的,也不管是不是幻觉,回家选我的女一号去,哈哈】
另外有相关问题可以加入QQ群讨论,不设微信群
QQ群:868373192
语音深度学习群


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











