







哈喽,事实说明那两个服务器都是垃圾。我用第一个服务器就可以跑。但是调用非常慢!!!!运行起来很慢。
Epoch 00096: val_acc did not improve from 0.55416
Epoch 97/100
15285/15285 [==============================] - 14s 925us/step - loss: 0.1484 - acc: 0.9999 - val_loss: 2.1899 - val_acc: 0.5518
Epoch 00097: val_acc did not improve from 0.55416
Epoch 98/100
15285/15285 [==============================] - 14s 919us/step - loss: 0.1483 - acc: 0.9998 - val_loss: 2.1897 - val_acc: 0.5521
Epoch 00098: ReduceLROnPlateau reducing learning rate to 2.4414063659605745e-07.
Epoch 00098: val_acc did not improve from 0.55416
Epoch 99/100
15285/15285 [==============================] - 14s 918us/step - loss: 0.1484 - acc: 0.9999 - val_loss: 2.1908 - val_acc: 0.5521
Epoch 00099: val_acc did not improve from 0.55416
Epoch 100/100
15285/15285 [==============================] - 14s 919us/step - loss: 0.1483 - acc: 0.9999 - val_loss: 2.1902 - val_acc: 0.5515
Epoch 00100: val_acc did not improve from 0.55416
跑个ResNet就到55%验证集的acc,感觉有点Low。
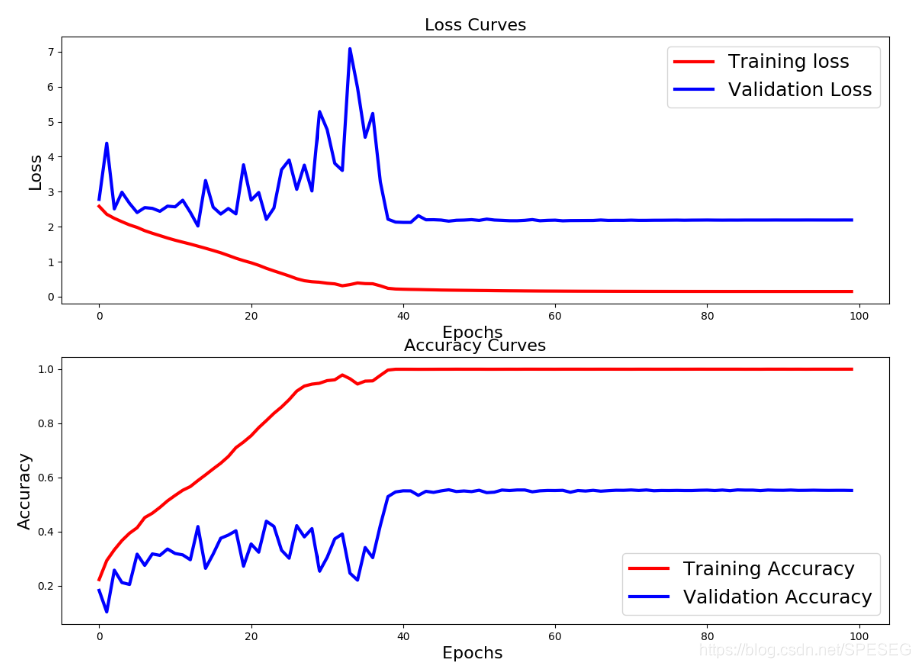
既然我有能跑的服务器为何还要折腾????
因为这个是tf1.12.0的版本,不能升级,升级需要cudnn及cuda的相应升级,否则不行。
因为我需要tf1.14.0的版本,这是落地必须的,不行的话没法玩。
因为项目多,不只跑一个,这个只有两个一般卡,虽说目前也没有更多卡的。
我想要256个卡,或者给我100个能用GPU的服务器。不能用GPU的服务器一分钱不值,没一点屁用。
下面试试减少add。[2,1],我用的是RGB的,灰度的话应该对动作影响不是太大。
只有53%,有点低了。。。。微笑。
Epoch 00097: val_acc did not improve from 0.53218
Epoch 98/100
15285/15285 [==============================] - 14s 887us/step - loss: 0.1340 - acc: 0.9999 - val_loss: 2.4703 - val_acc: 0.5288
Epoch 00098: val_acc did not improve from 0.53218
Epoch 99/100
15285/15285 [==============================] - 13s 881us/step - loss: 0.1340 - acc: 0.9998 - val_loss: 2.4732 - val_acc: 0.5293
Epoch 00099: val_acc did not improve from 0.53218
Epoch 100/100
15285/15285 [==============================] - 14s 885us/step - loss: 0.1338 - acc: 0.9998 - val_loss: 2.4735 - val_acc: 0.5301
Epoch 00100: val_acc did not improve from 0.53218

要不试试ResNet18吧,尽管不太想巨无霸的模型。
Epoch 00096: val_acc did not improve from 0.48325
Epoch 97/100
15285/15285 [==============================] - 20s 1ms/step - loss: 0.2240 - acc: 1.0000 - val_loss: 3.4173 - val_acc: 0.4686
Epoch 00097: val_acc did not improve from 0.48325
Epoch 98/100
15285/15285 [==============================] - 20s 1ms/step - loss: 0.2239 - acc: 0.9998 - val_loss: 3.4182 - val_acc: 0.4689
Epoch 00098: ReduceLROnPlateau reducing learning rate to 2.4414063659605745e-07.
Epoch 00098: val_acc did not improve from 0.48325
Epoch 99/100
15285/15285 [==============================] - 20s 1ms/step - loss: 0.2237 - acc: 0.9999 - val_loss: 3.4192 - val_acc: 0.4689
Epoch 00099: val_acc did not improve from 0.48325
Epoch 100/100
15285/15285 [==============================] - 20s 1ms/step - loss: 0.2237 - acc: 0.9998 - val_loss: 3.4194 - val_acc: 0.4686
Epoch 00100: val_acc did not improve from 0.48325
结果惨不忍睹啊,这就是18层,这是18层地狱吧
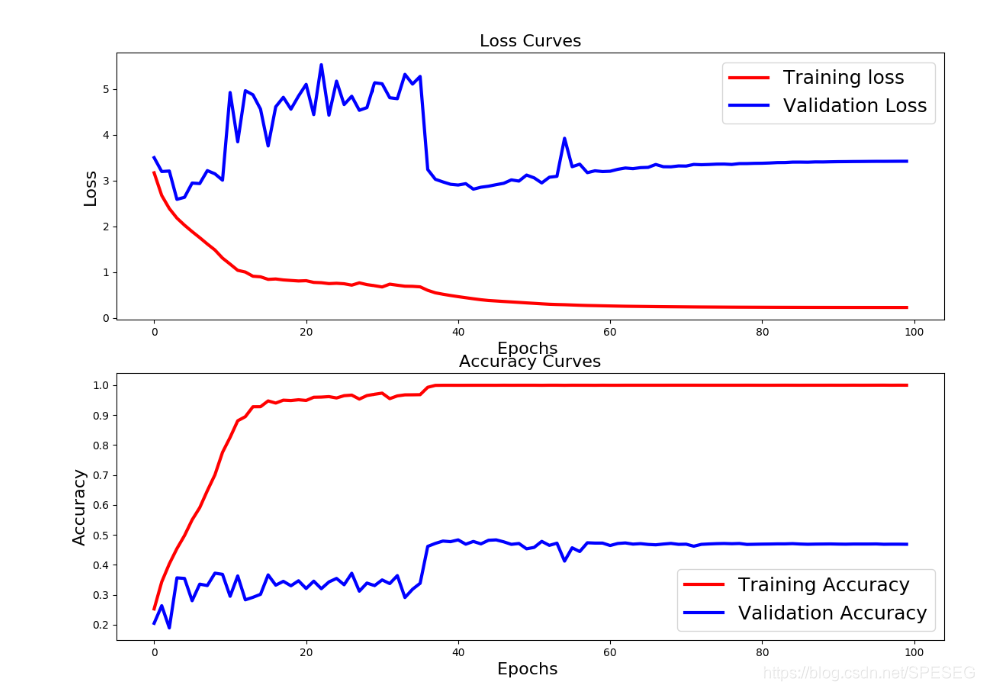
下面试试34层。可能会有奇迹吧,想想加勒比海盗中,海底即天堂。
我能说效果不行吗?也没进展。看来要用bottleneck了啊。
Epoch 00097: val_acc did not improve from 0.51622
Epoch 98/100
15285/15285 [==============================] - 30s 2ms/step - loss: 0.2098 - acc: 0.9999 - val_loss: 3.2552 - val_acc: 0.5118
Epoch 00098: ReduceLROnPlateau reducing learning rate to 2.4414063659605745e-07.
Epoch 00098: val_acc did not improve from 0.51622
Epoch 99/100
15285/15285 [==============================] - 30s 2ms/step - loss: 0.2097 - acc: 1.0000 - val_loss: 3.2569 - val_acc: 0.5123
Epoch 00099: val_acc did not improve from 0.51622
Epoch 100/100
15285/15285 [==============================] - 30s 2ms/step - loss: 0.2096 - acc: 0.9999 - val_loss: 3.2612 - val_acc: 0.5113
Epoch 00100: val_acc did not improve from 0.51622
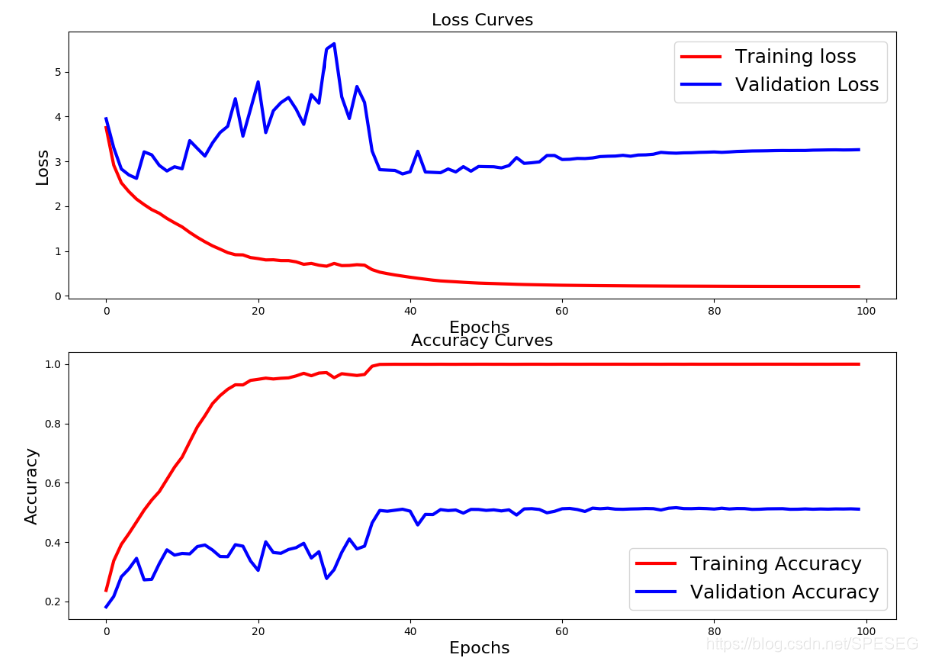
上50层的bottleneck。不行啊,服务器直接死了。
只能改小,bottleneck[2323],效果很差劲。垃圾玩意。验证集36%acc
改成[2,3],只有50%。哎[2,2]也是差不多。
改到[1,1]也不到50%,失败,纯ResNet根本不行啊,我看有个达到70%多。
也试试VGG,参考了一个keras版本的,发现卷积池化不一起用,而是卷积BN,卷积BN池化,这样参数很多,跑不起来。只好将每层都加池化。用了个最简单的,200多万参数的。验证集55%acc,比ResNet要好,可能我用的ResNet也是假的。卧槽
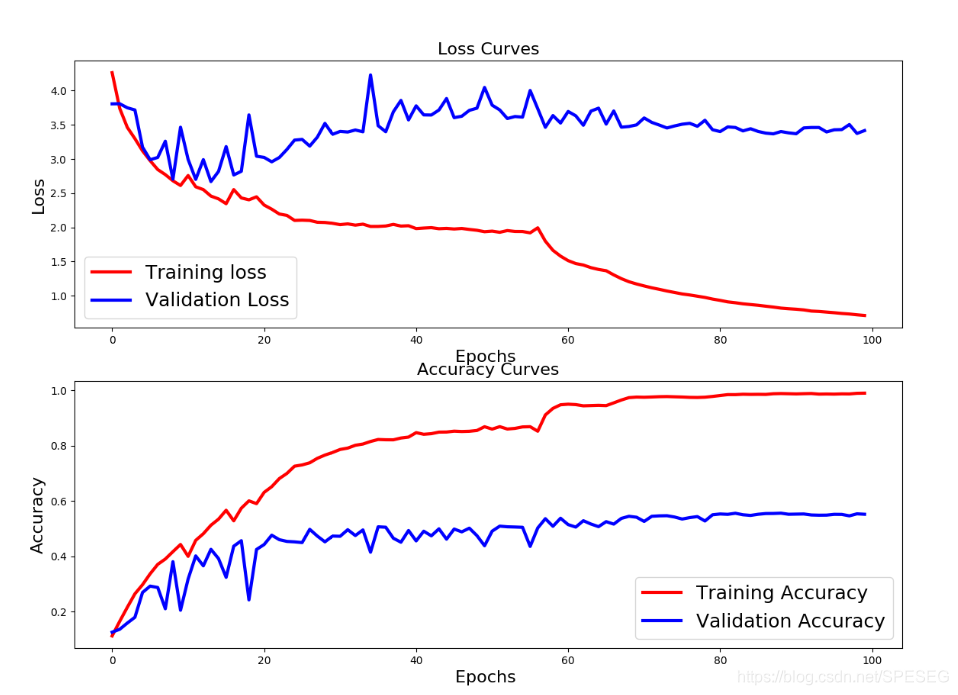
再次修改了VGG,可以到60%了,看图,难道我的epoch还不够??200次??
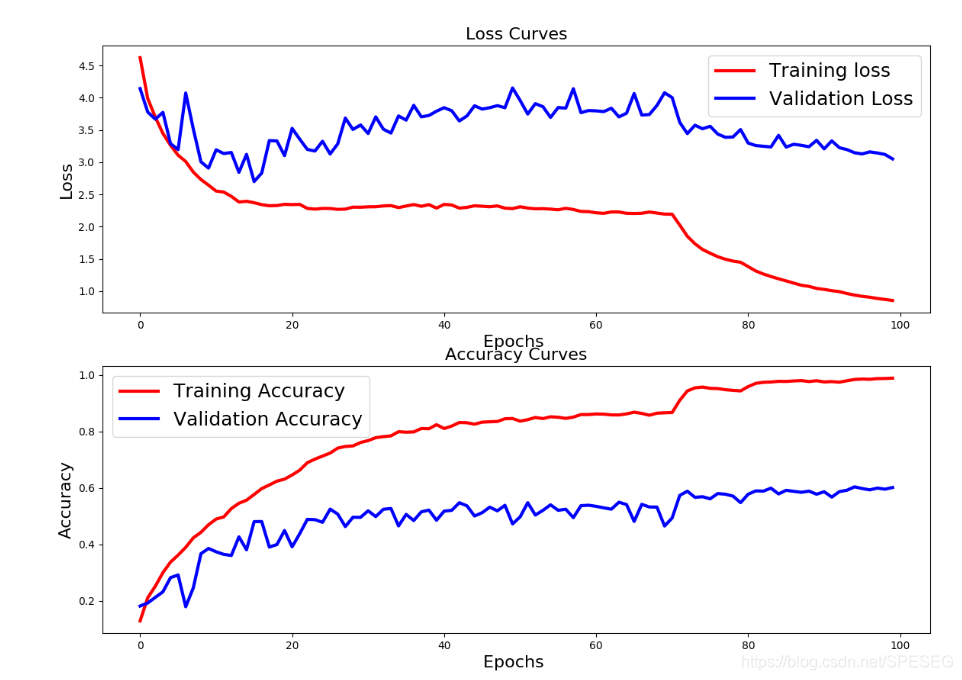
use tf-org's model ,pls see the blog https://blog.youkuaiyun.com/SPESEG/article/details/103079746
另外有相关问题可以加入QQ群讨论,不设微信群
QQ群:868373192
语音深度学习群


















 4546
4546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











