



一.OCR图片识别:
什么是OCR?
光学字符识别(OCR)技术使计算机能够从图像中提取文本信息。在数字识别方面,Java提供了多种库和工具,使得实现这一功能变得相对简单。文本将介绍如何使用Java进行OCR数字识别,并提供相应的代码示例。
使用Java进行OCR数字识别:
- 导入maven依赖:
<dependencies> <!--图像识别--> <dependency> <groupId>e-iceblue</groupId> <artifactId>spire.ocr</artifactId> <version>1.9.0</version> </dependency> </dependencies> <!--图像识别--> <repositories> <repository> <id>com.e-iceblue</id> <name>e-iceblue</name> <url>https://repo.e-iceblue.cn/repository/maven-public/</url> </repository> </repositories> - 下载OCR 官方文件:下载 | Spire.OCR for Java
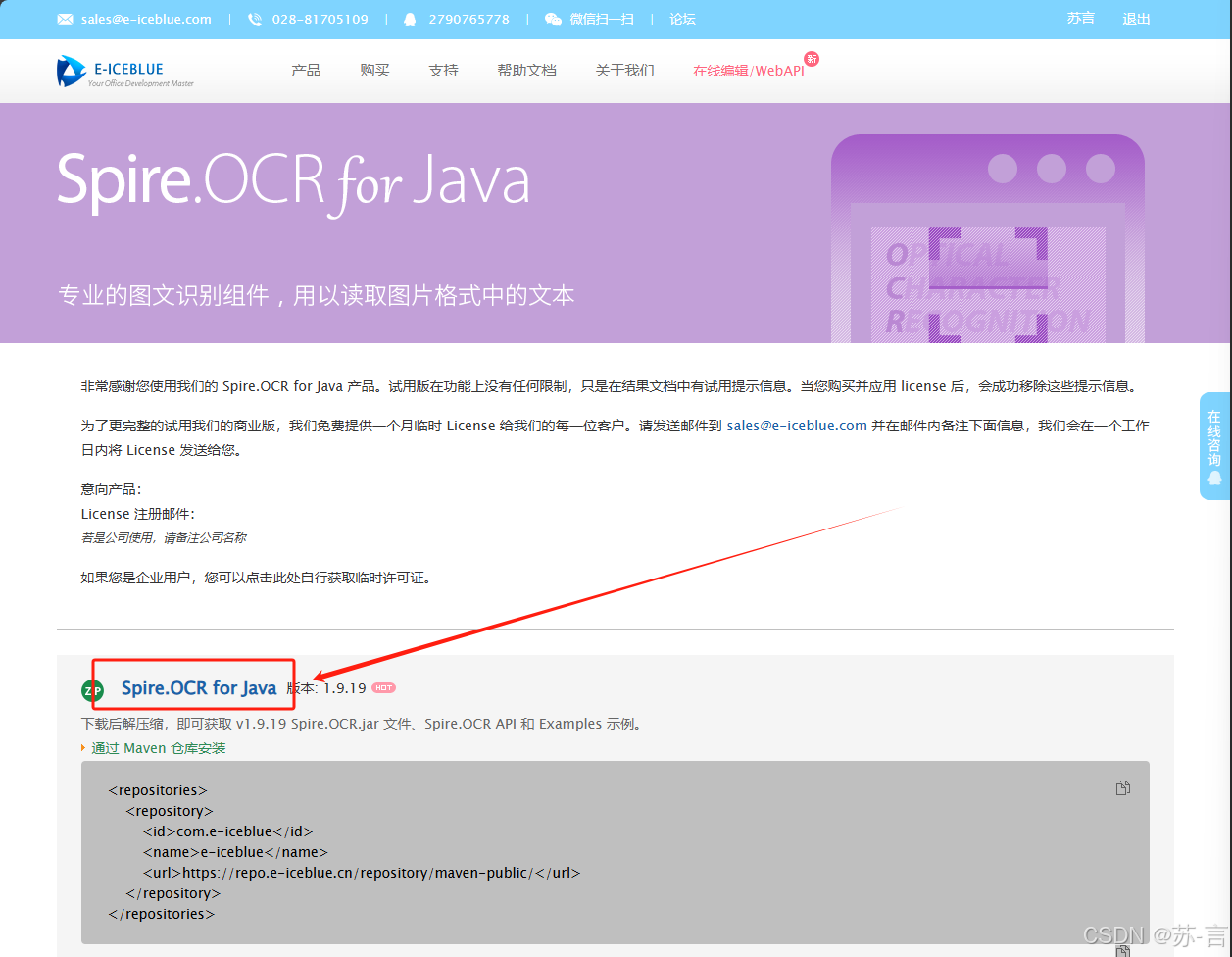
- 下载其他依赖文件:
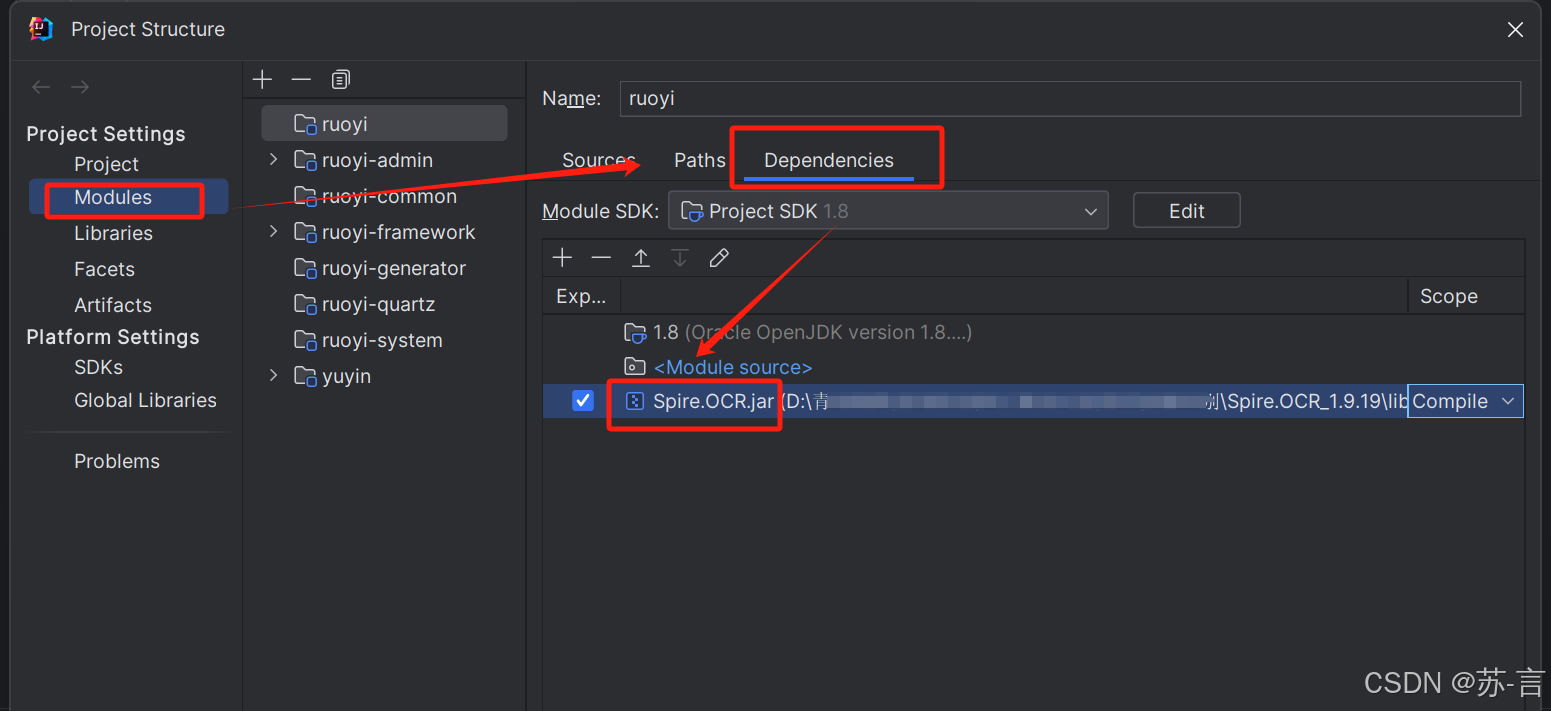
- 在IDEA中新建项目并导入Spire.OCR.jar
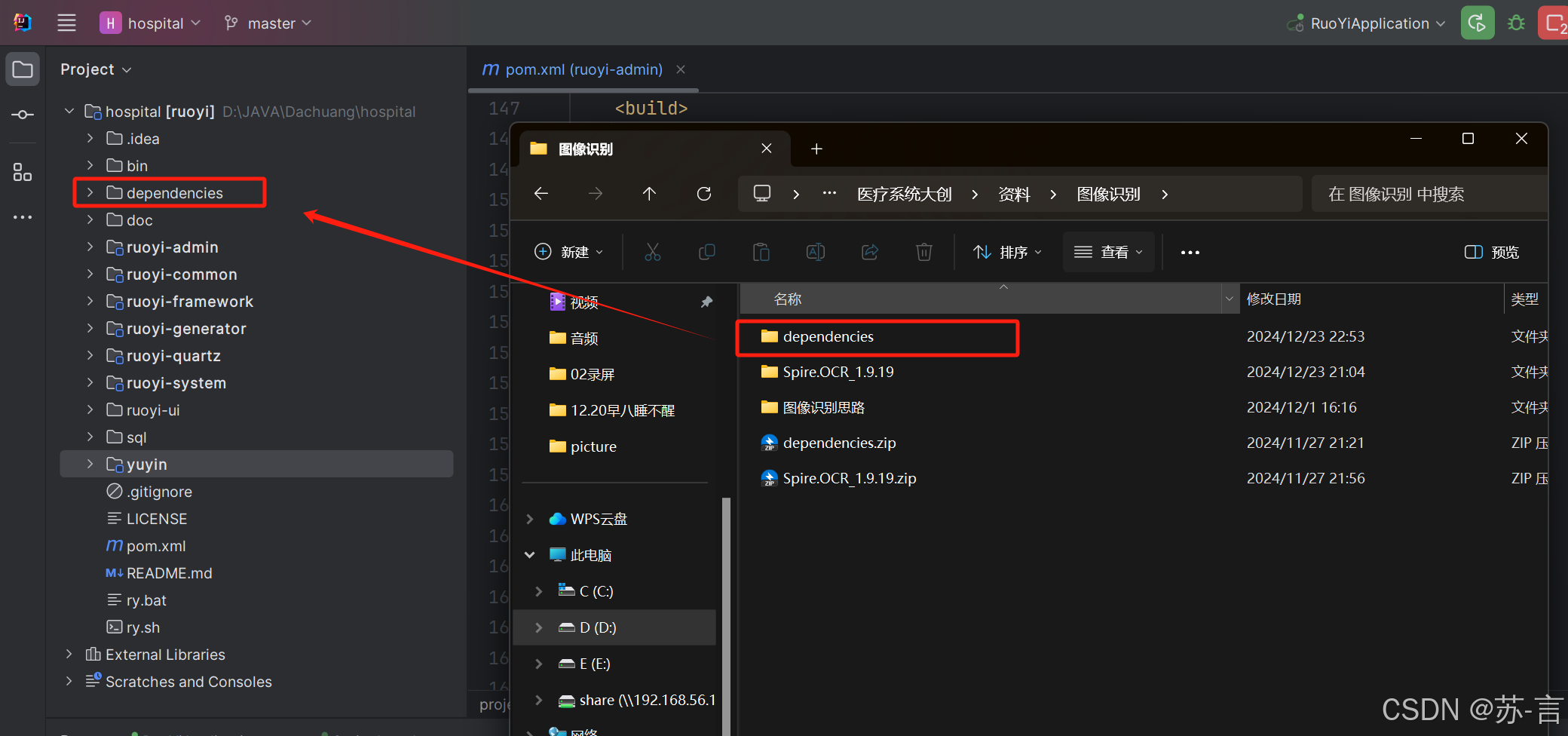
- 将刚下载的 "dependencies"文件夹复制到IDEA项目目录下:
- 确保导入上述文件以及依赖后,运行以下代码实现扫描读取图片中的文本:
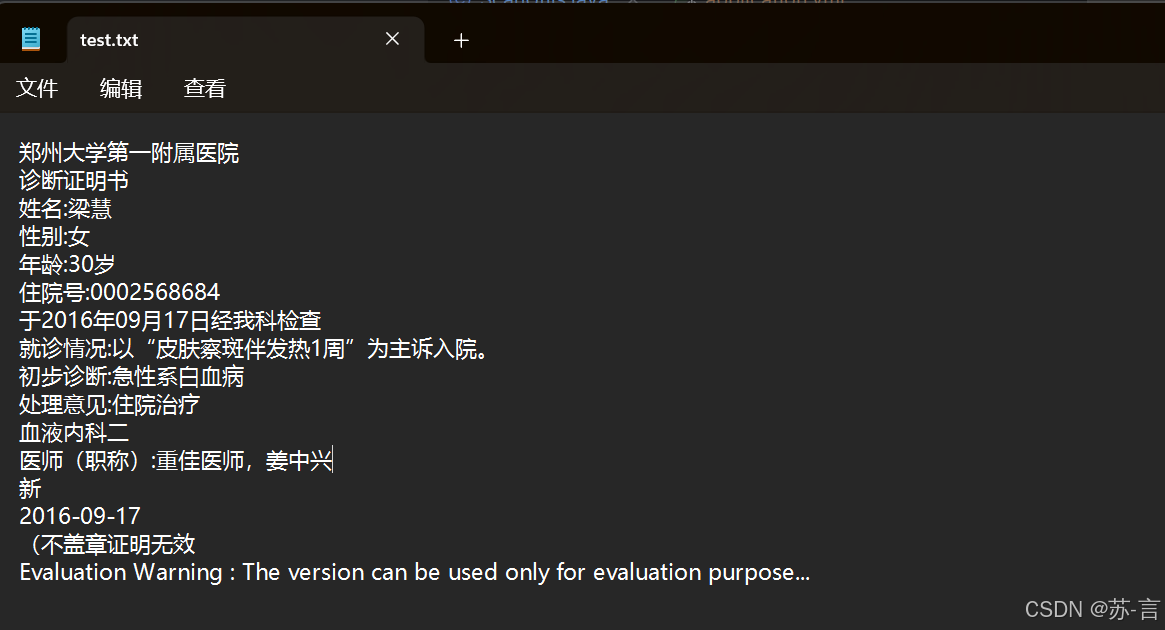
package com.ruoyi.utils; import com.spire.ocr.OcrException; import com.spire.ocr.OcrScanner; import java.util.Date; import java.util.HashMap; import java.util.Map; import java.util.regex.Matcher; import java.util.regex.Pattern; public class ScanUtils { //扫描诊断图片 public static Map<String,String> scanImage(String path) throws Exception { //指定依赖文件的路径 String dependencies = "dependencies\\"; //指定要需要扫描的图片的路径 String imageFile = path; //创建OcrScanner对象,并设置其依赖文件路径 OcrScanner scanner = new OcrScanner(); scanner.setDependencies(dependencies); //扫描指定的图像文件 scanner.scan(imageFile); //获取扫描的文本内容 String scannedText = scanner.getText().toString(); scannedText = scannedText.replace(":",":"); // System.out.println(scannedText); // 使用正则表达式匹配每一对键值 Pattern pattern = Pattern.compile("(\\S+?):(\\S+)"); Matcher matcher = pattern.matcher(scannedText); Map<String, String> result = new HashMap<>(); while (matcher.find()) { String key = matcher.group(1).trim(); String value = matcher.group(2).trim(); result.put(key, value); } return result; } public static Map scanMedicineImage(String path) throws OcrException { //指定依赖文件的路径 String dependencies = "dependencies\\"; //指定要需要扫描的图片的路径 String imageFile = path; //指定输出文件的路径 // String outputFile = "D:/青城博雅/实训阶段/医疗系统大创/upload/picture/读取图片.txt"; //创建OcrScanner对象,并设置其依赖文件路径 OcrScanner scanner = new OcrScanner(); scanner.setDependencies(dependencies); //扫描指定的图像文件 scanner.scan(imageFile); //获取扫描的文本内容 String scannedText = scanner.getText().toString(); scannedText = scannedText.replace("【","").replace("】" ,":").replace(":",":").replace("药品名称:","").replace("\n"," ").replace("\r"," "); // 使用正则表达式匹配每一对键值 Pattern pattern = Pattern.compile(" (\\S+?):(.+?)(?=\\s*\\S+:|$) "); Matcher matcher = pattern.matcher(scannedText); Map<String, String> result = new HashMap<>(); while (matcher.find()) { String key = matcher.group(1).trim(); String value = matcher.group(2).trim(); result.put(key, value); } return result; } } - 示例图片:

- OCR 识别扫描结果:
二.二维码识别
简介:
二维码就是一种编码技术,只是这种编码技术用在了图片上,将给的一些文字,数字转换为一张经过特定编码的图片,而解析二维码相反,就是将一张经过编码的图片解析为数字或文字。
解码步骤:
- 导入依赖:
<dependency> <groupId>com.google.zxing</groupId> <artifactId>core</artifactId> <version>3.4.1</version> </dependency> - 添加工具类:
package com.ruoyi.utils; import com.google.zxing.*; import com.google.zxing.client.j2se.BufferedImageLuminanceSource; import com.google.zxing.common.HybridBinarizer; import com.google.zxing.NotFoundException; import javax.imageio.ImageIO; import java.awt.image.BufferedImage; import java.io.File; import java.io.IOException; import java.util.HashMap; import java.util.Map; /** * 基于google zxing的二维码识别 * * @author wlp * @date 2022/8/26 9:16 */ public class QRCodeUtils { /** * 解析二维码,此方法解析一个路径的二维码图片 * path:图片路径 */ public static String deEncodeByPath(String path) { String content = null; BufferedImage image; //存储读取的图片 try { image = ImageIO.read(new File(path)); LuminanceSource source = new BufferedImageLuminanceSource(image); //从 image 中提取亮度信息 Binarizer binarizer = new HybridBinarizer(source); //将亮度信息转换为二值图像 BinaryBitmap binaryBitmap = new BinaryBitmap(binarizer); //存储二值图像 Map<DecodeHintType, Object> hints = new HashMap<>(1); hints.put(DecodeHintType.CHARACTER_SET, "UTF-8"); //设置字符集 // 解码 // Result result = new MultiFormatReader().decode(binaryBitmap, hints); Result result = new MultiFormatReader().decode(binaryBitmap,hints); System.out.println("图片中内容: "); System.out.println("content: " + result.getText()); content = result.getText(); } catch (IOException e) { e.printStackTrace(); } catch (NotFoundException e) { // 这里判断如果识别不了带LOGO的图片,重新添加上一个属性 try { image = ImageIO.read(new File(path)); LuminanceSource source = new BufferedImageLuminanceSource(image); Binarizer binarizer = new HybridBinarizer(source); BinaryBitmap binaryBitmap = new BinaryBitmap(binarizer); Map<DecodeHintType, Object> hints = new HashMap<>(3); // 设置编码格式 hints.put(DecodeHintType.CHARACTER_SET, "UTF-8"); // 设置优化精度 hints.put(DecodeHintType.TRY_HARDER, Boolean.TRUE); // 设置复杂模式开启(我使用这种方式就可以识别微信的二维码了) hints.put(DecodeHintType.PURE_BARCODE, Boolean.TYPE); // 解码 Result result = new MultiFormatReader().decode(binaryBitmap, hints); System.out.println("图片中内容: "); System.out.println("content: " + result.getText()); content = result.getText(); } catch (IOException e1) { e1.printStackTrace(); } catch (NotFoundException e1) { e1.printStackTrace(); } } return content; } public static void main(String[] args) { deEncodeByPath("D:/二维码生成/药品二维码.png"); } } - 示例图片:

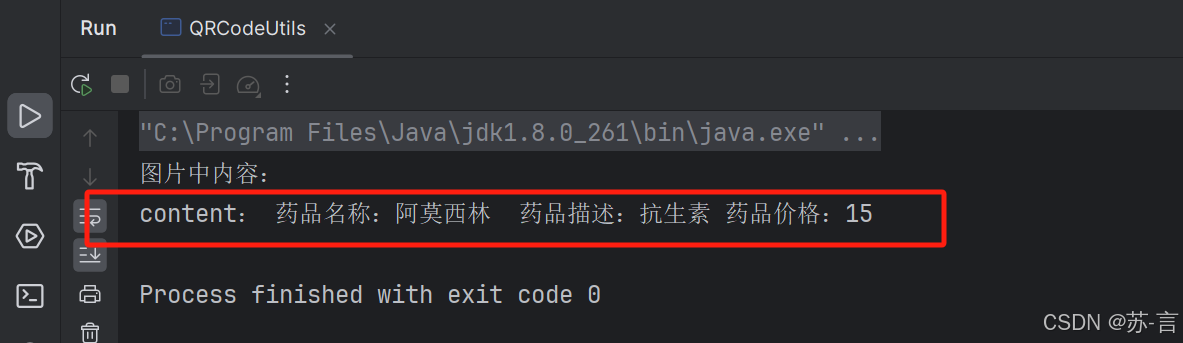
- 输出结果:

















 4159
4159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









