



随着人工智能(AI)技术的迅猛发展,向量化技术已成为自然语言处理、计算机视觉、文本比对等领域的核心技术之一。向量化使得我们能够以数学和计算的方式表示文本、图像等数据,从而使计算机能够理解并处理这些复杂的对象。本文将介绍基于 Redis 的向量召回技术,并探讨其在 AI 业务中的应用。
01
基本概念
1.1 向量生成的模型原理
向量化是将高维原始数据(如文本、图片、音频等)通过特定算法转换为低维数字表示的过程,通常称为"向量"。生成向量的过程依赖深度学习模型,尤其是基于神经网络的模型。例如:
Word2Vec 和 BERT 可将文本转化为向量;
ResNet 和 VGG 可将图像转化为向量。
这些向量不仅保留了原始数据的语义信息,还便于进行计算和比较。
1.2 向量相似度的使用场景
向量相似度计算的核心应用之一是寻找多个对象之间的相似性。最常见的场景包括:
推荐系统:基于用户的历史行为生成向量,通过向量相似度匹配相似用户或商品;
问答系统:计算用户提问与已有答案之间的向量相似度,快速定位最合适的答案;
图像检索:通过图像向量化,快速检索相似图片(如以图搜图、人脸匹配等);
文本检索:将查询文本与文档集中的文本向量化,并基于向量相似度进行匹配。
1.3 向量相似度常用算法
以下为部分常见的向量相似度计算方法:

不同算法适用于不同场景,选择合适的算法可以显著提高效率和准确度。
02
Redis 在向量搜索中的应用
作为一款高性能内存数据库,Redis 提供了毫秒级的检索速度,非常适合实时应用场景。通过 RedisSearch 模块,Redis 引入了强大的向量搜索能力。
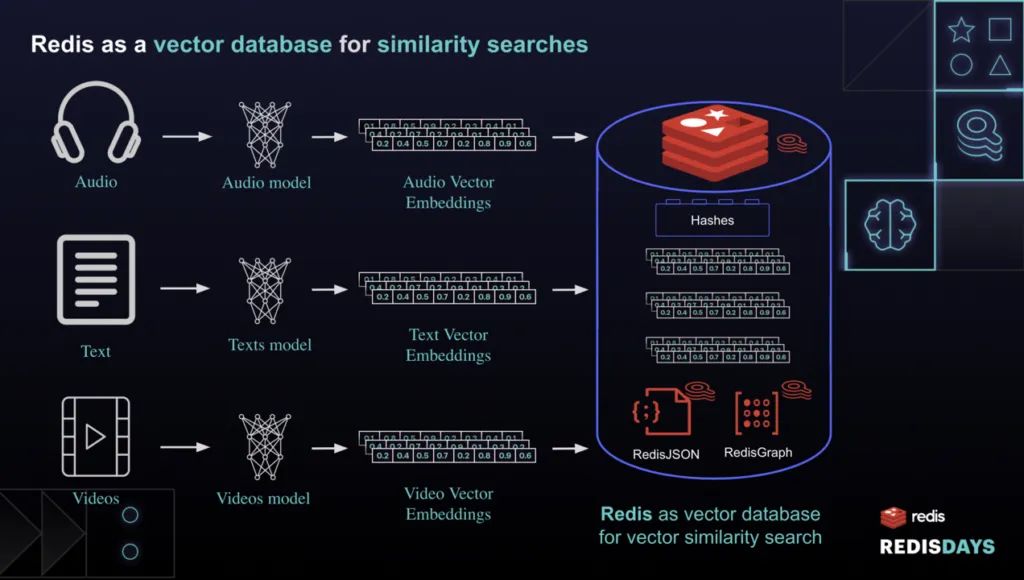
2.1 RedisSearch 支持的数据类型
RedisSearch 模块提供强大的全文检索和数据索引功能,借助 Redis 的内存存储和高效数据结构,可以高效地进行向量检索。支持的主要数据类型包括:
Hash 数据结构;
在集成 ReJSON 模块后支持 JSON 数据格式。
2.2 支持的向量精度与搜索算法
RedisSearch 支持多种向量精度,包括:
FLOAT32 和 FLOAT64:高精度数据;
BFLOAT16 和 FLOAT16:更低内存占用,适合轻量级场景。
支持的搜索算法:
1、FLAT(Brute Force):暴力搜索,通过逐一比较所有向量来计算相似度。
优点:精确度高,简单易用;
缺点:计算量随数据量线性增长,效率低,适用于小规模数据集;
适用场景:小规模数据集的精确搜索。
2、HNSW(Hierarchical Navigable Small World):基于小世界网络理论构建图结构,进行高效的近邻搜索。
优点:快速搜索,良好的近似度和扩展性;
缺点:内存开销大,构建过程复杂且耗时;
适用场景:大规模数据集的近似搜索,支持高维向量搜索。
HNSW 参数解读
HNSW算法,将所有向量构建成一张图,根据这张图,搜索某个顶点附近Top K节点数据。索引构建时间慢,查询速度快。
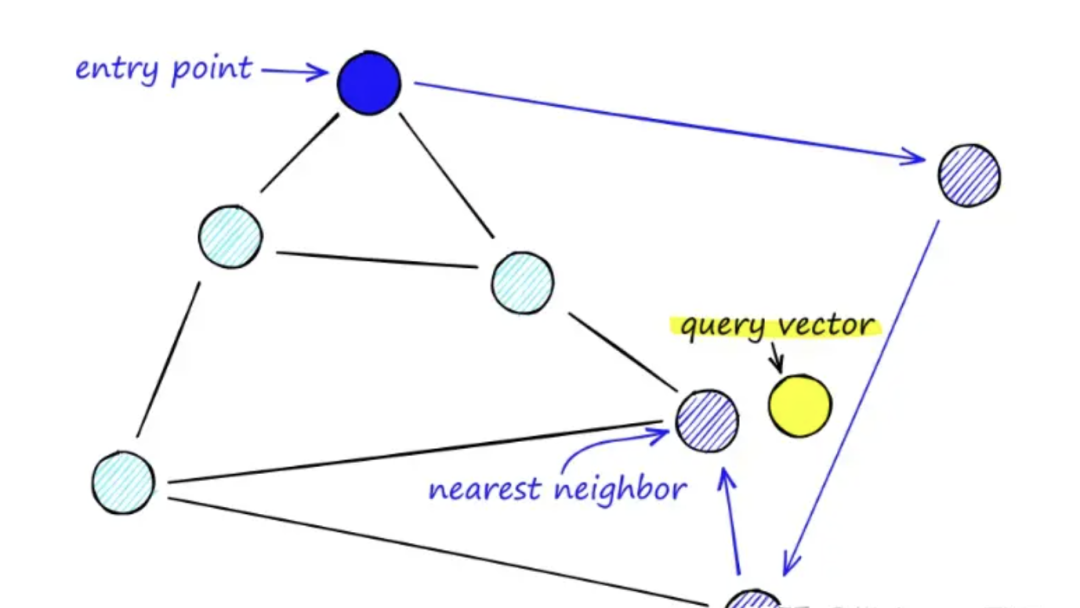
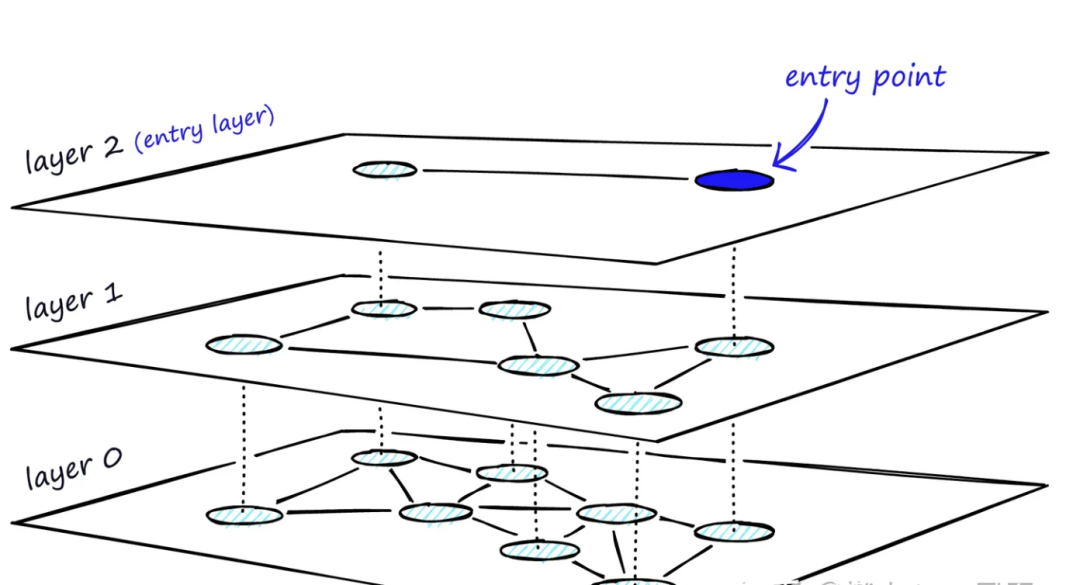
HNSW 算法的一些参数及解读:
M:每层图中每个节点允许的最大出边(outgoing edge)数,第零层最大边的个数是2M。默认值为 16;
EF_CONSTRUCTION:图构建过程中,每个节点允许最大出边数量,默认值为 200;
EF_RUNTIME:KNN 搜索范围的候选对象数,较高值提高精确度但增加耗时,默认值为 10;
EPSILON:影响范围查询边界的参数,默认值为 0.01。
参数解读:
M:每个新增的entry point 连接到最近节点的双向连接的数量,合理的范围 M 是 2-100。对于具有高内在维度和/或高召回率的数据集,较高 M 的效果更好,而对于具有低内在维度和/或低召回率的数据集,则较小 M 更好。该参数还确定算法的内存消耗,大约 M * 8-10 是每个存储元素的字节数;
EF_CONSTRUCTION:新加节点时,确定建立连接的动态候选节点列表的大小。更高的 efConstruction 值意味着建立连接的过程更彻底,尽管速度较慢。此参数有助于平衡连接密度,从而影响搜索的效率和准确性;
EF_RUNTIME:搜索最高候选的对象数量。
说明:合理的参数设置可以显著影响搜索性能与资源占用。
2.3 支持的相似度计算算法
RedisSearch 提供以下常见相似度计算算法:
L2(Euclidean Distance)欧氏距离:适用于图像或其他连续数据;
IP(Inner Distance)内积距离:常用于深度学习中的相似度计算;
COSINE(Cosine Distance)余弦距离:适用于文本、推荐等领域。
在创建 RedisSearch 向量索引时,可以根据应用场景灵活配置向量精度和算法。
03
使用 Redis 实现向量召回
3.1 创建索引
在 Redis 中创建向量索引时,首先需要明确以下信息:
向量数据的精度;
向量的维度;
使用的算法。
确保精度、维度和存储的向量数据一致,否则可能导致创建失败或检索不准确。
假设我们有一组文档,每个文档包含以下字段:
| 字段 | 说明 | 类型 |
|---|---|---|
id | 文档 ID | 数字 |
name | 名称 | 文本 |
type | 类型 | 标签 |
description | 描述 | 文本 |
desc_vector | 描述的向量 | 向量 |
创建索引的 Redis 命令如下:
# 基于 Hash 数据结构创建索引
FT.CREATE hashIdx ON HASH PREFIX 1 doc: SCHEMA
id NUMERIC
name TEXT
type TAG SEPARATOR ,
description TEXT
desc_vector VECTOR FLAT 6 TYPE FLOAT32 DIM 512 DISTANCE_METRIC COSINE
# 基于 JSON 数据结构创建索引
FT.CREATE jsonIdx ON JSON PREFIX 1 jsonDoc: SCHEMA
$.id AS id NUMERIC
$.name AS name TEXT
$.type AS type TAG SEPARATOR ,
$.description AS description TEXT
$.desc_vector AS desc_vector VECTOR HNSW 6 TYPE FLOAT32 DIM 512 DISTANCE_METRIC COSINE基于 Hash 的索引:
键的前缀为
doc:,索引名为hashIdx;包含普通字段(
id、name、type和description)以及一个向量字段desc_vector;使用 FLAT 算法进行索引。
基于 JSON 的索引:
键的前缀为
jsonDoc:,索引名为jsonIdx;字段采用 JSONPath,如
$.字段名;使用 HNSW 算法进行索引。
字段类型说明:
NUMERIC:数字类型,可进行范围搜索;
TEXT:文本类型,可进行全文搜索(分词);
TAG:标签类型,可进行标签搜索(在不需要分词,且标签数量可控的情况下,推荐使用)。
注: Hash 数据结构,字段名为 field;而 JSON 数据结构,需采用JsonPath方式,如 $.字段名 获取。
3.2 进行召回
向量召回通过计算查询向量与索引中存储向量的相似度,选取最相似的文档。
KNN 向量检索:
FT.SEARCH jsonIdx "*=>[KNN 10 @desc_vector $vec AS score]" PARAMS 2 vec [0.1, 0.2, ..., 0.5]范围检索:
FT.SEARCH jsonIdx "@desc_vector:[VECTOR_RANGE $distance_limit $vec]" PARAMS 4 distance_limit 0.2 vec [0.1, 0.2, ..., 0.5] LIMIT 0 10 DIALECT 4说明:
KNN 10:返回与查询向量最相似的前 10 个结果;distance_limit:允许的最大向量距离(语义距离);vec:比对的查询向量。
3.3 检索优化
为提高检索性能和准确性,可采用以下优化措施:
调整索引算法:
推荐优先使用 HNSW 算法;
要求绝对精准匹配,且数据集较小时(如少于 100 万条数据),可考虑使用 FLAT 算法。
调整索引配置:
针对 HNSW 算法,可根据数据集,及检索需求,调节索引算法的配置参数,如
M、EF_CONSTRUCTION和EF_RUNTIME。
限制返回结果的数量:
控制返回结果的数量以减少计算开销。
限制索引和返回字段:
根据实际需求对字段建立索引,并在检索时仅返回必要字段(指定返回哪些字段)。
分片和分布式存储:
对于大规模数据集,采用 Redis 集群模式进行分片和分布式存储以提升检索效率。
04
拓展
4.1 向量检索的应用案例
智能客服是现代企业提升客户服务效率的重要工具,它通过人工智能技术实现了自动化问题解答,显著降低了人力成本。然而,智能客服的关键在于能够快速、准确地理解用户的问题,并提供有效的解决方案,而这背后离不开强大的问答库支持。
问答库是智能客服系统的知识基础,涵盖了常见问题及其对应的解答。传统的问答库多以关键词匹配为核心,但面对复杂的用户表达和多样化的问题场景,单纯的关键词匹配显得无能为力,给用户笨拙低效的体验。这时,向量搜索技术作为一种先进的检索方式,展现出了其强大的潜力。
我们可将问答库中的文本,利用向量大模型转化为向量并存储。当用户输入问题时,将问题也转换为向量,并通过向量相似度计算,召回匹配的问答数据,实现对用户问题的精准匹配。
相比传统方法,向量搜索能够理解问题中的语义含义,识别出用户隐含的意图,即使用户的问题表述与问答库中的内容不完全一致,也能提供相关性较高的答案。
以智能客服系统(问答库匹配子系统)为例,展示了向量检索的应用案例及优化过程:
4.1.1 创建索引和数据类型选择
在创建索引时,可根据数据的特性选择合适的数据类型。
注意事项:
NUMERIC字段索引: 如果误存入字符串且不可解析为数字,会导致该条文档索引失败;
数字类型字段为TAG类型: 如果需要将数字字段设置为TAG类型,建议将数字转换为字符串后存储,否则可能导致文档索引失败;
索引结果: Redis 在添加文档时不会返回文档索引结果。如果索引配置错误,可能导致后续数据检索不到结果,并且排查较为困难,尤其是非专业人员。
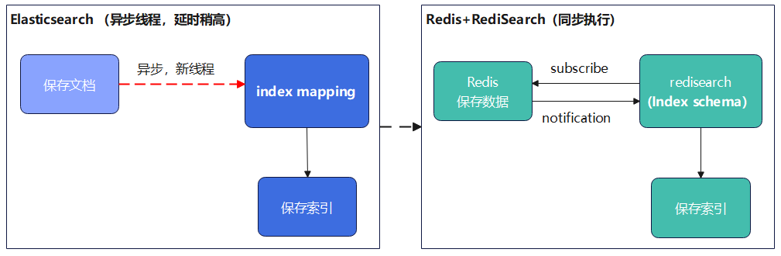
创建索引示例说明:添加文档后,RediSearch 创建索引的过程是通过回调函数触发。如下图所示:
以下为Java代码示例,创建一个名为
qnaIdx的索引,基于以下字段:id(问答库ID);question(问答库标准问题);answer(问答库标准答复);type(问答库问题类型);embedding(问答库文本向量)。
public void createIndex() { IndexDefinition definition = new IndexDefinition(IndexDefinition.Type.JSON) .setPrefixes("jsonDoc:"); Map<String, Object> attr = new HashMap<>(); attr.put("TYPE", "FLOAT32"); attr.put("DIM", 512); attr.put("DISTANCE_METRIC", "COSINE"); Schema schema = new Schema() .addNumericField("$.id").as("id") .addTextField("$.question", 1).as("question") .addTextField("$.answer", 1).as("answer") .addTagField("$.type", 1).as("type") .addHNSWVectorField("$.embedding", attr).as("vector"); jedisSentineled.ftCreate("qnaIdx", IndexOptions.defaultOptions() .setDefinition(definition), schema); }4.1.2 索引的文档需注意规避特殊字符
TEXT字段处理:
默认会进行英文分词,包括词干、停用词等处理;
所有标点符号和空格(除下划线
_)也会被分词。
建议: 在
TEXT类型字段的数据保存和查询时,尽量避免使用以下符号:,.<>{}[]"':;!@#$%^&*()-+=~符号转义: 如果必须使用上述符号,需要在文档保存和查询时进行转义。在符号前添加反斜线
\。示例:
存储文档
# question是TEXT类型 # 存储值为buy-book的文档,需按buy\-book存储 json.set jsonDoc:1 $ '{"id":1, "question": "buy\\-book", "type":1}'查询文档
# 查询name字段值为buy-book的文档,需按buy\\-book查询 FT.SEARCH qnaIdx "@question:buy\\-book"
TAG字段处理:
不会进行分词,直接存储;
但查询时,同样需要对上述符号进行转义。
示例:
# type 是TAG类型,存储值是1-1,则需按照1\-1进行查询 FT.SEARCH qnaIdx "@type:{1\\-1}"注: 下划线
_不需要转义,可以直接存储和查询。如果业务允许,建议使用下划线代替其他特殊符号。4.1.3 问答库向量召回
//question to vector public List<Float> text2Vector(String text) { return EmbeddingModel.text2Vector(text); } //knn query public List<Doc> knnQuery(byte[] vectorBytes) { List<Doc> totalList = new ArrayList<>(); Query query = new Query("*=>[KNN $numDoc @embedding $BLOB AS score]") .returnFields("question", "answer") .setSortBy("score", true) .dialect(2) .addParam("numDoc", 10) .addParam("BLOB", vectorBytes) .limit(0, 10); SearchResult searchResult = jedisSentineled.ftSearch("jsonIdx", query); List<Document> documents = searchResult.getDocuments(); for(Document doc : documents){ Doc Doc = parseDocumentToDoc(doc); totalList.add(Doc); } return totalList; } //range query public List<Doc> rangeQuery(byte[] vectorBytes) { List<Doc> totalList = new ArrayList<>(); Query query = new Query("@embedding: [VECTOR_RANGE $radius $BLOB]") .returnFields("question", "answer") .setSortBy("score", true) .dialect(2) .addParam("$radius", 0.2) .addParam("BLOB", vectorBytes) .limit(0, 10); SearchResult searchResult = jedisSentineled.ftSearch("jsonIdx", query); List<Document> documents = searchResult.getDocuments(); for(Document doc : documents){ Doc Doc = parseDocumentToDoc(doc); totalList.add(Doc); } return totalList; }通过上述代码,我们即可实现对问答库的向量召回,找到与用户问题最相似的答案。并可在此基础上,基于Rerank模型,对召回的结果进行二次排序,提高召回的准确性。此内容不在本文讨论的范围内,读者可自行查找。
4.2 扩展——混合检索场景适配及RediSearch的能力边界
向量召回在许多场景中表现优秀,但在某些复杂场景下,其结果可能不够准确。例如:
文本较长,语义跨度较大;
存在大量相关语义的文档,导致召回结果离散。
在这些情况下,依靠关键词反而可能获得更准确的结果。因此,业内提出了混合检索的方式。
4.2.1 什么是混合检索?
混合检索指同时使用稀疏检索和密集检索两种方法:
稀疏检索:如 BM25,通过关键词的精确匹配,适合直接查询词的匹配场景,但语义理解能力有限;
密集检索:基于向量的语义检索,可以找到语义相关但不包含查询关键词的内容。
通过结合两种方式,混合检索可以:
弥补单一检索方式的不足;
同时找到关键词匹配和语义相关的内容;
提升信息检索的全面性和准确性。
下面将介绍两种向量数据库的混合检索方式,并对比展示 RediSearch 的能力边界。
在仅基于向量召回的场景中,与 ElasticSearch 相比,Redis 在性能上具有明显优势。因此,对于实时性要求高的 AI 应用,Redis 常常是更优选择。
4.2.2 文本匹配 & 语义匹配
在混合检索中,常常需要两种检索条件之间为“或”的关系,而不是简单的“与”关系。
对此,两种数据库,均需要通过两次查询,然后再将结果进行组合,并重新计算文档匹配分值。
4.2.2.1 Redis 实现混合检索示例
以下代码展示了如何在 Redis 中实现文本查询、向量查询以及混合查询。
// 混合查询 public List<Doc> hybridQuery(List<String> keywords, List<Float> vector, float textWeight, float vectorWeight) { List<Doc> textResults = textQuery(keywords); List<Doc> vectorResults = vectorQuery(vector); Map<String, Doc> docMap = new HashMap<>(); textResults.forEach(doc -> { doc.setScore(1 * textWeight); docMap.put(doc.getId(), doc); }); vectorResults.forEach(doc -> { doc.setScore(doc.getScore() * vectorWeight); docMap.merge(doc.getId(), doc, (oldDoc, newDoc) -> { oldDoc.setScore(oldDoc.getScore() + newDoc.getScore()); return oldDoc; }); }); return docMap.values().stream() .sorted(Comparator.comparingDouble(Doc::getScore).reversed()) .collect(Collectors.toList()); } // 向量查询 public List<Doc> vectorQuery(List<Float> vector) { // ignore, just like redis knnQuery return docs; } // 文本查询, keywords 为关键词列表 public List<Doc> textQuery(List<String> keywords) { String keyWord = keyWords.stream().collect(Collectors.joining(" | "); String redisQuery = String.format("@question:%s", keyword); SearchResult result = redisClient.ftSearch("indexName", redisQuery); List<Doc> docs = new ArrayList<>(); result.getDocuments().forEach(doc -> { docs.add(new Doc(doc.getId(), doc.getScore())); }); return docs; }4.2.2.2 ElasticSearch 实现混合检索示例
以下代码展示了在 ElasticSearch 中如何实现向量检索、关键词检索及混合检索。
// combined query public List<Doc> combinedQuery(String question, List<Float> vector, float textWeight, float vectorWeight) { List<Doc> matchDocs = elasticsearchService.matchQuery(question); List<Doc> knnDocs = elasticsearchService.knnQuery(vector); // Normalize scores float maxScore = matchDocs.stream().map(Doc::getScore).max(Float::compareTo).orElse(0f); float minScore = matchDocs.stream().map(Doc::getScore).min(Float::compareTo).orElse(0f); Map<Long, Doc> docMap = new HashMap<>(); matchDocs.forEach(doc -> { float score = doc.getScore(); if (maxScore - minScore != 0) { score = (score - minScore) / (maxScore - minScore); } doc.setScore(score * textWeight); docMap.put(doc.getId(), doc); }); for (Doc doc : vectorResults) { doc.setScore(doc.getScore() * vectorWeight); docMap.merge(doc.getId(), doc, (oldDoc, newDoc) -> { oldDoc.setScore(oldDoc.getScore() + newDoc.getScore()); return oldDoc; }); } return docs.stream().sorted(Comparator.comparingDouble(Doc::getScore).reversed()).collect(Collectors.toList()); } // knn query public List<Doc> knnQuery(List<Float> vector) throws IOException { List<Doc> result = new ArrayList<>(); SearchRequest request = new SearchRequest.Builder() .index("indexName") .knn(q -> q .field("vector") .queryVector(vector) .numCandidates(50) .k(20) ) .source(source -> source.filter(sf -> sf.excludes("vector"))) .size(20) .build(); SearchResponse<Doc> response = client.search(request, Doc.class); response.hits().hits().forEach(hit -> { Doc doc = hit.source(); doc.setScore(doc.score().floatValue()); result.add(doc); }); return result; } // match query public List<Doc> matchQuery(String text) throws IOException { List<Doc> result = new ArrayList<>(); SearchResponse<Doc> response = client.search(s -> s .index("indexName") .query(q -> q .match(m -> m .field("description") .query(text) ) ) .source(source -> source.filter(sf -> sf.excludes("embedding"))) .size(20), Doc.class ); response.hits().hits().forEach(hit -> { Doc doc = hit.source(); doc.setScore(hit.score().floatValue()); result.add(doc); }); return result; }通过上述代码,我们从以下角度对比 Redis 和 ElasticSearch:
对比项 Redis ElasticSearch 实现方式 通过 RedisSearch 模块,实现文本检索和向量检索
本身支持文本检索,通过插件实现向量检索
性能 检索速度快,毫秒级响应
检索速度较慢,响应时间在毫秒级到秒级
适用场景 适用于实时性要求高的场景
适用于数据量大、复杂查询的场景
分词 基于 RediSearch 分词,分词插件有限
有很多分词插件,非常成熟
文本检索 依赖外部工具进行分词或关键词提取,未提供相关性得分,文本匹配算法较不灵活
本身支持字段分词,无需额外处理,且提供相关性得分
向量检索扩展 局限于 RediSearch,灵活性较差
有多种扩展插件,支持性和灵活性更好
RedisSearch 的文本检索能力较为一般,尤其在分词和灵活性方面存在局限。如果需要更灵活的分词和文本检索能力,请慎重考虑。对于其他大多数场景,如对性能要求较高的场景中,Redis 是一个不可忽视的选择。
05
Redis向量召回,使用注意事项总结
版本选择
RediSearch在不断迭代,如需使用 BFLOAT 请使用2.10+版本,一些新特性或功能,可参考 Release Notes。
算法选择
创建索引时,优先选用 HNSW 算法,避免使用性能较差的 FLAT 算法。
文本存储与索引
RediSearch 会对文本中的符号进行分词。文本中使用符号时需谨慎(下划线除外)。
索引字段类型选择
根据字段格式、分词需求及字段值范围,选择合适的字段索引类型以优化性能。
06
总结
Redis 作为高性能内存数据库,通过 RedisSearch 模块为向量召回提供了强大的支持。结合其高效的存储和检索能力,开发者可以在 AI 业务中快速实现大规模的向量召回系统。无论是推荐系统、图像检索,还是语义匹配,Redis 都能提供灵活且高效的解决方案,支撑 AI 业务的需求。


















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









