




 本文详细介绍NonPowerAware、ThrRs、IqrMc及MadMmt四个云仿真案例,涵盖非功耗感知与功耗感知数据中心仿真、虚拟机调度策略、主机过载检测策略等内容。
本文详细介绍NonPowerAware、ThrRs、IqrMc及MadMmt四个云仿真案例,涵盖非功耗感知与功耗感知数据中心仿真、虚拟机调度策略、主机过载检测策略等内容。
文章目录
- 一、NonPowerAware案例
- 二、ThrRs案例
- 三、IqrMc案例
- 四、MadMmt案例
前言:以下仅聚焦主要和重点过程,并非完整流程,比如不含CloudSim初始化和broker对于云任务和虚机的提交等,因为几乎所有的任务都需要经历这些,也几乎无需修改这些代码。完整流程见CloudSim官网
一、NonPowerAware案例
1.1 基本概述
位置:org.cloudbus.cloudsim.examples.power.random中的NonPowerAware.java
功能:对异构非功耗感知数据中心的仿真,返回所有主机仿真过程中的最大功率
返回:所有主机仿真过程中的最大功率(最大能耗)
1.2 云任务/虚机/主机/功耗模型参数设置
位置:org.cloudbus.cloudsim.examples.power中的Constants.java
用户数量(numUser) = 1
数据中心数量 = 1
云任务时长:2500天

4种类型虚拟机参数设置
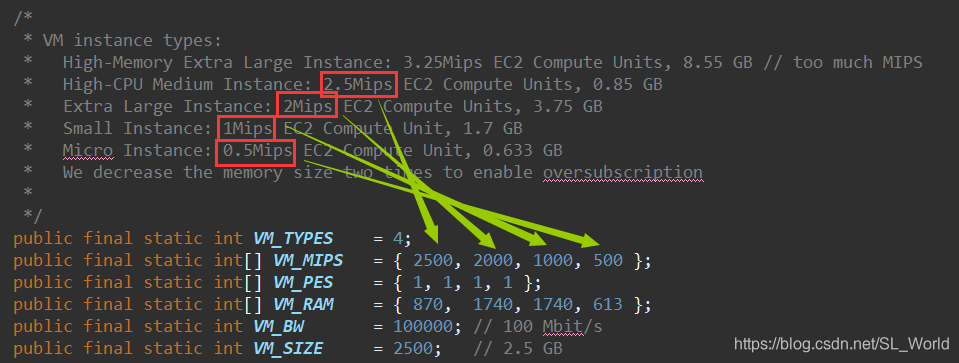
2种异构类型物理机参数设置
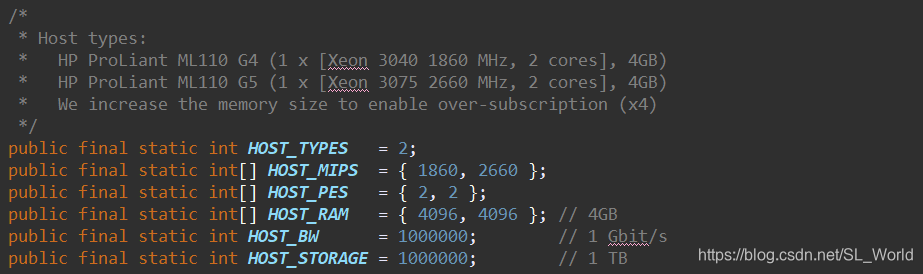
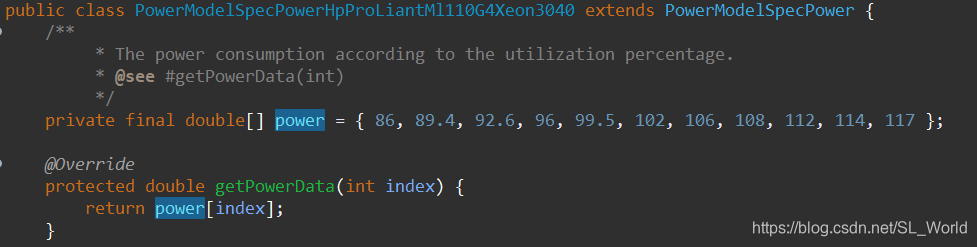
2种异构物理机(惠普G4和惠普G5)的功耗模型

在CloudSim中的仿真模型,实际编程是传入CPU利用率∈[0,1],归一化到[0,10]整数以表征[0%, 10%, 20%,…,90%,100%],通过整数索引来获取对应的能耗值(单位W),如该型号主机10%资源利用率对应能耗为89.4w
不同主机厂商功耗模型网址:http://www.spec.org/power_ssj2008/results/power_ssj2008.html
-
HP ProLiant ML110
G4型号主机为例,以说明空载状态下的主机都有一定能耗损失
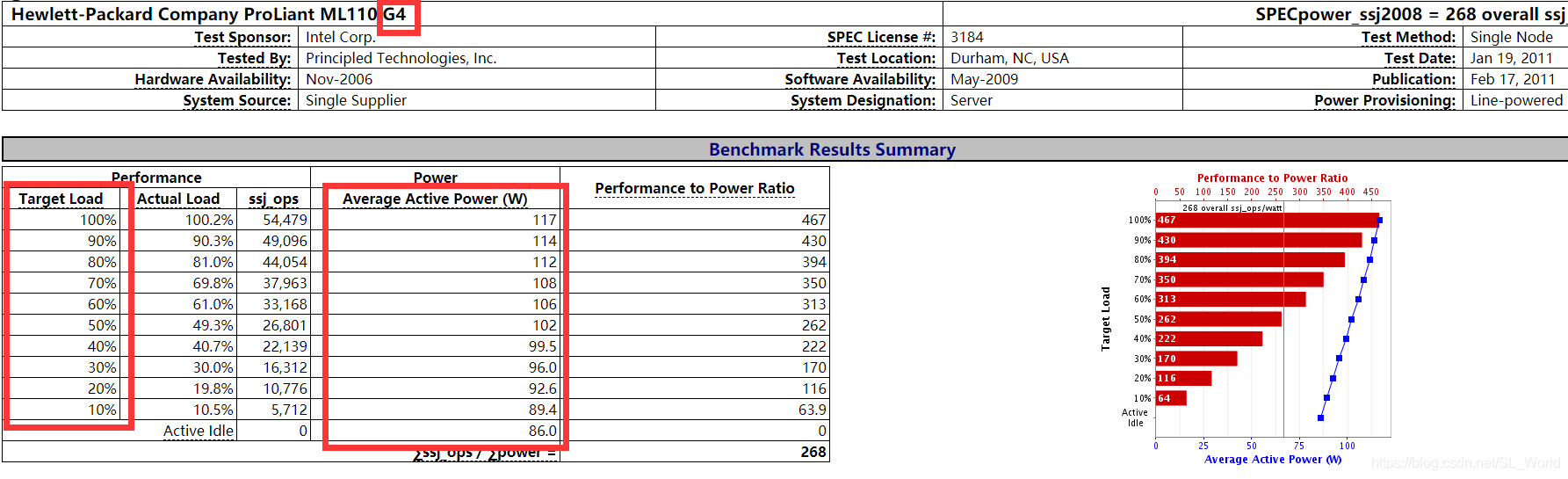
-
HP ProLiant ML110
G5型号主机为例
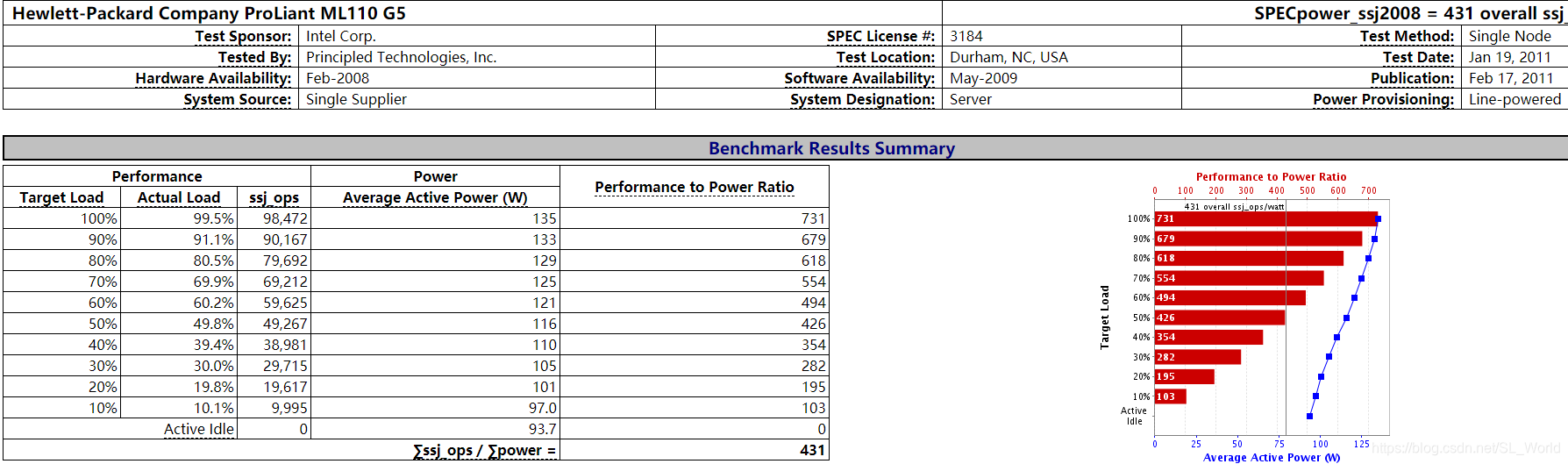
初步设想:对于空载状态下高能耗的物理机,较好的虚机的放置策略/整合策略可节能更多
1.3 初始化云任务(CloudletList)—如何载入自定义真实数据集中的CPU利用率?
| 参数 | 参数值 |
|---|---|
| 云任务数量 | 50个 |
| 云任务长度 | 2500天 |
初始化云任务序列时,{CPU利用率,RAM, Bw}设置为{Random, null, null}

进入到RandomHelper.createCloudletList()方法中,可见其对每个云任务中的{CPU利用率,RAM, Bw}设置方式
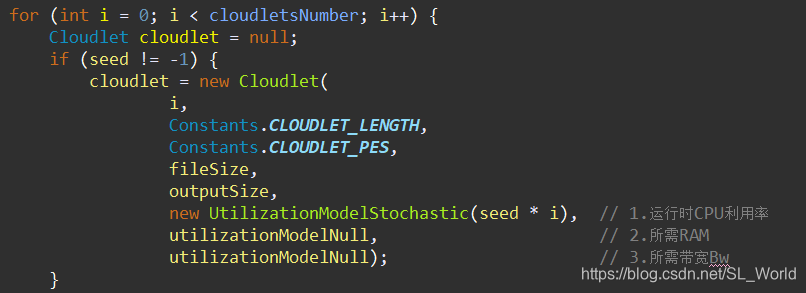
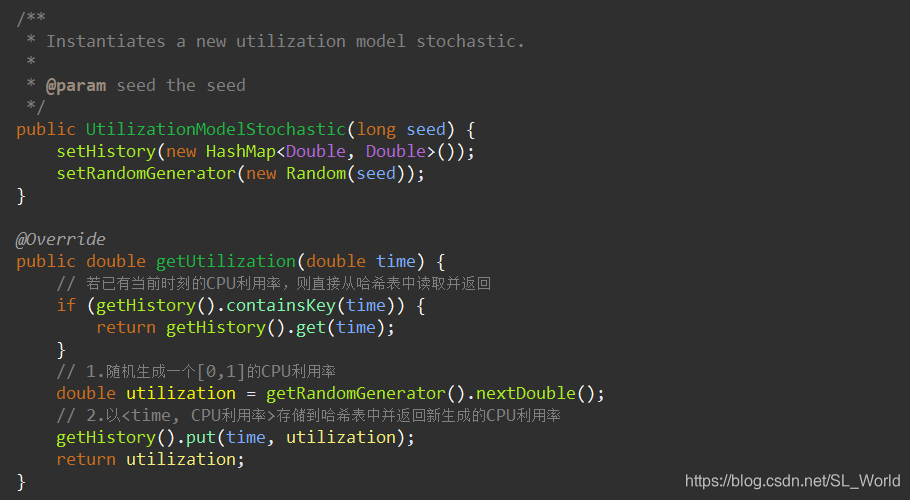
随机化的过程是
- 随机生成一个[0,1]的CPU利用率
- 以
<time, CPU利用率>存储到哈希表中并返回新生成的CPU利用率
如果想载入真实数据如PlanetLab,Alibaba Trace,GWA-T-12 faseStorage则可自定义此for循环中的UtilizationModelStochastic(),以下给出载入PlanetLab数据集的案例
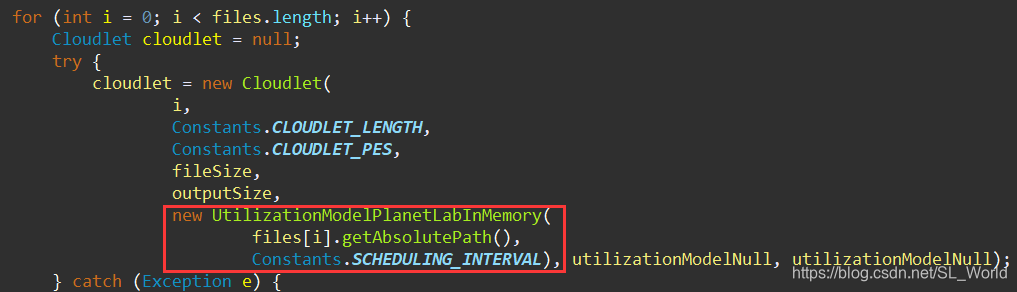
具体实现过程如下
- 定义1个data数组用来存储每个时刻的CPU利用率,1天按5分钟分割,则总长需存储288个时刻的CPU利用率
- 从Trace文件中逐个读取每个时刻的CPU利用率并存入data数组中
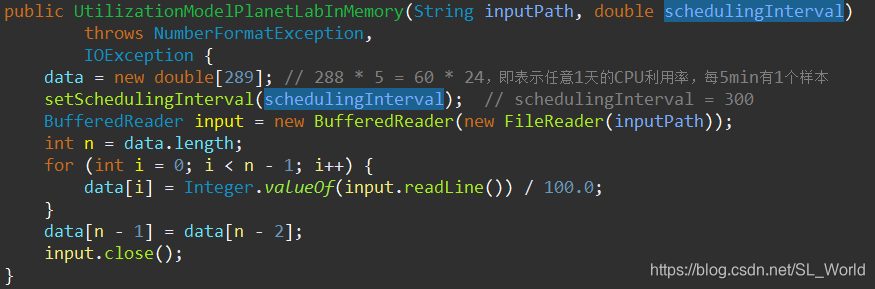
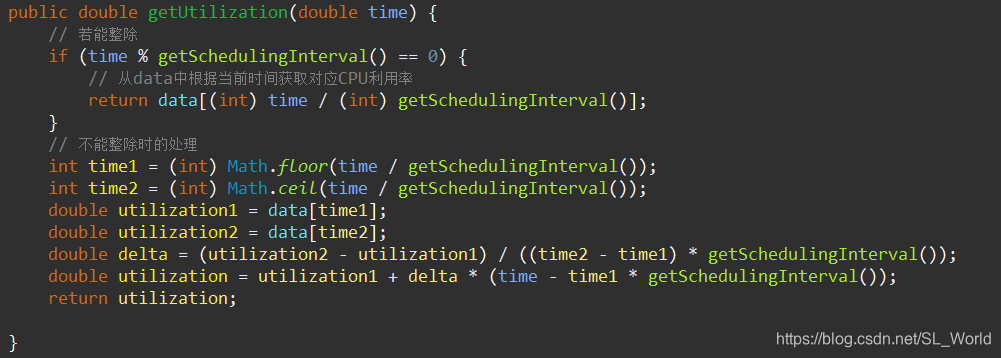
然后根据不同时刻,作为索引可直接从data中获取对应CPU利用率,此处仅需简单处理下时间不能整除时的情况
1.4 初始化虚拟机(vmList)—虚机调度算法默认时间共享
本例中为每个云任务创建1台虚机,因此共创建50台虚机
List<Vm> vmList = Helper.createVmList(brokerId, cloudletList.size());
虚机中对于云任务所需CPU资源的调度策略默认为时间共享,从该方法继承自CloudletSchedulerTimeShared可见
public class CloudletSchedulerDynamicWorkload extends CloudletSchedulerTimeShared {...}
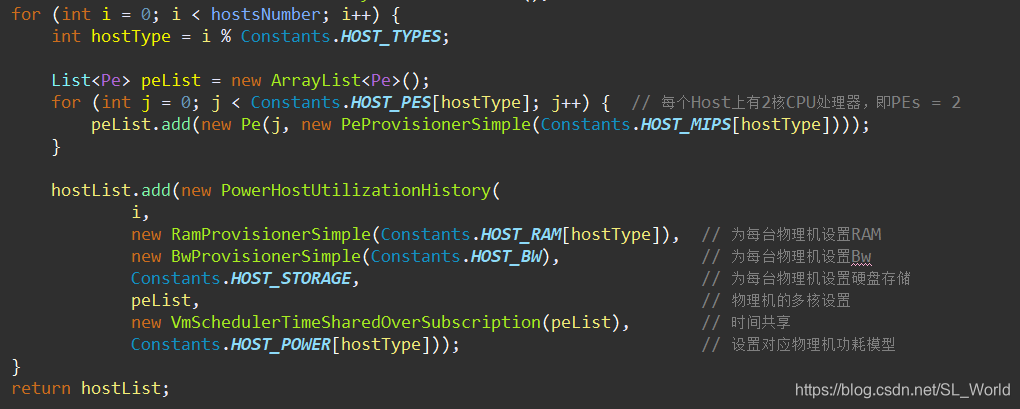
1.5 初始化物理机(hostList)——如何自定义不同型号物理机配置?
同上,此处物理机的CPU调度策略依然默认时间共享
List<PowerHost> hostList = Helper.createHostList(RandomConstants.NUMBER_OF_HOSTS);
进入到Helper.createHostList()方法中,可以发现此处for循环中的hostList.add方法可以通过自定义参数和函数以自定义不同型号物理机配置
比如案例中的不同主机硬盘存储均为同一定值,可以依照RamProvisionerSimple自定义StorageProvisionerSimple实现不同主机拥有不同硬盘存储
1.6 初始化数据中心(datacenter)——在哪修改虚拟机分配策略?(默认First Fit)

我们先来看看数据中心的构造方法
- 初始化数据中心特征
characteristics - 根据数据中心特征 + 虚拟机分配策略构造数据中心
datacenter
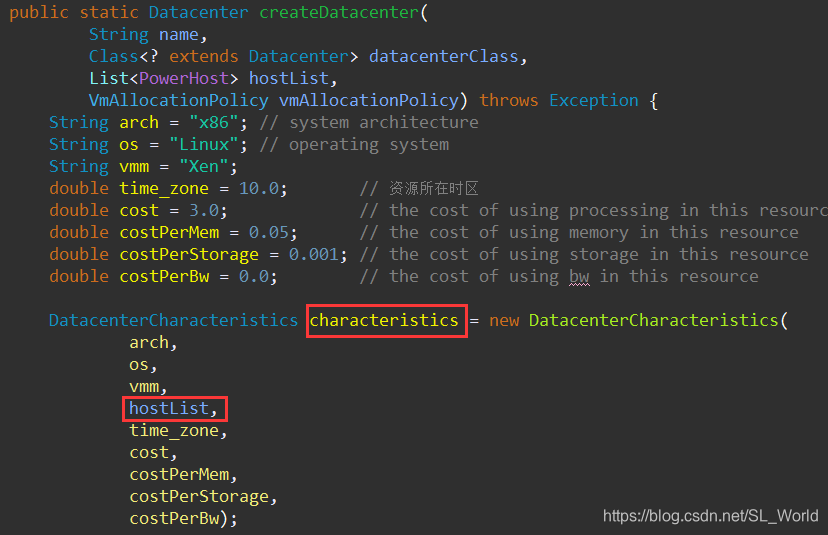
接下来,我们看看传入的虚拟机分配策略是什么?这里能耗虚机分配策略继承原始VmAllocationPolicy方法
public abstract class PowerVmAllocationPolicyAbstract extends VmAllocationPolicy {...}
继续进入VmAllocationPolicy方法,可见其用First Fit策略进行虚拟机到主机的映射,因此想要修改或对比其他如Best Fit策略,则可到PowerVmAllocationPolicyAbstract.java文件中修改findHostForVm()中的算法即可实现
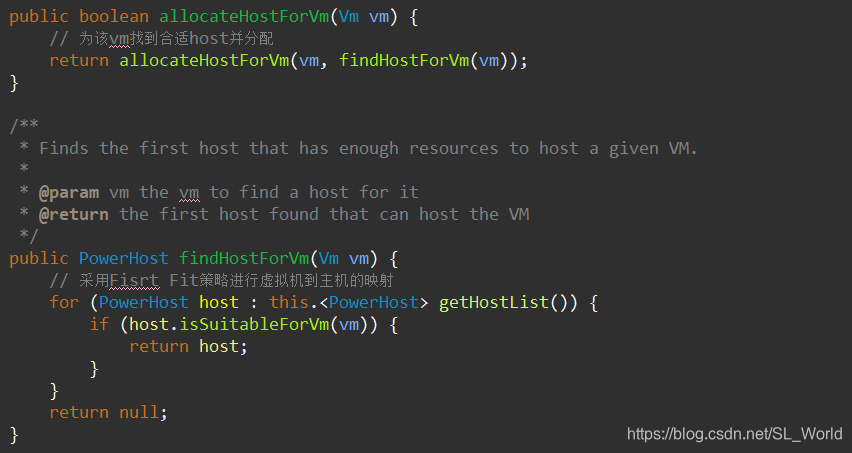
1.7 仿真结果——能耗、虚机迁移数、SLAV、当前DC开机主机数等
最后一步,broker提交用户的虚机和云任务需求到数据中心,执行仿真

进入printResults可发现,结束后从当前数据中心状态获取以下等指标
- 能耗(kw/h)——依据数据中心不同异构主机的功耗模型累计得到
- 虚机迁移数
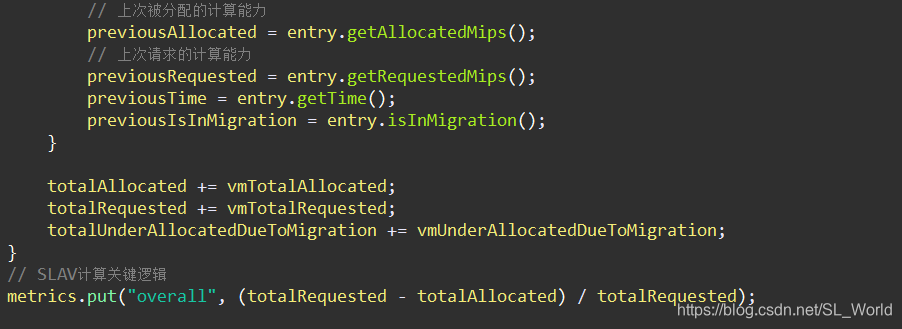
- SLAV服务违反率—— S L A V = 请 求 计 算 能 力 − 实 际 分 配 计 算 能 力 请 求 计 算 能 力 SLAV=\frac{请求计算能力 - 实际分配计算能力}{请求计算能力} SLAV=请求计算能力请求计算能力−实际分配计算能力
- 开机激活态主机数

运行程序,部分结果如下
Experiment name: random_npa
Number of hosts: 50
Number of VMs: 50
Total simulation time: 86400.00 sec
Energy consumption: 150.68 kWh // 实验需要的结果——能耗
Number of VM migrations: 0 // 因为之前设置了禁止迁移,所以此处为0
Overall SLA violation: 0.12% // 总SLA违反率
Average SLA violation: 9.78% // 平均每台虚机的SLA违反率
Number of host shutdowns: 29 // 当前数据中心关机主机数量为29台,实际开机21台
Mean time before a host shutdown: 300.10 sec
- SLAV计算逻辑代码如下
1.8 非功耗感知和功耗感知有啥区别?
| 功耗计算方式 | 数据中心类别 | |
|---|---|---|
| 非功耗感知 | 使用该物理机CPU利用率为100%下的功耗作为实时功耗 | PowerDatacenterNonPowerAware |
| 功耗感知 | 使用该物理机当前CPU利用率下的功耗作为实时功耗 | PowerDatacenter |
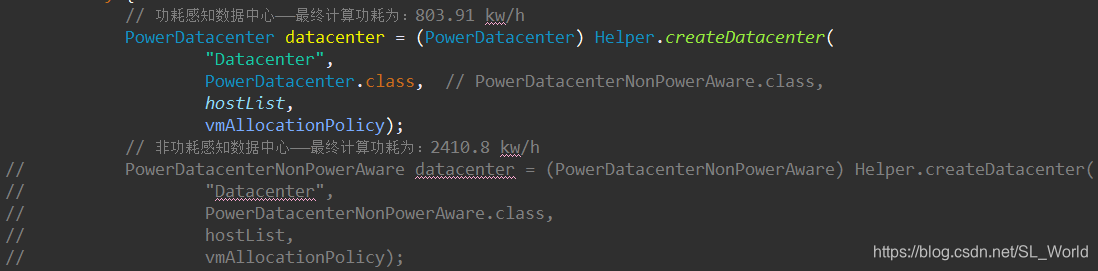
1.8.1 非功耗感知数据中心(PowerDatacenterNonPowerAware)
通过进入datacenter.getPower()方法,我们进入PowerDatacenterNonPowerAware.java类中,这里它继承了功耗感知数据中心并重写了相关方法
public class PowerDatacenterNonPowerAware extends PowerDatacenter {...}

这里的具体实现,即传入100%的CPU利用率,获取最大功耗
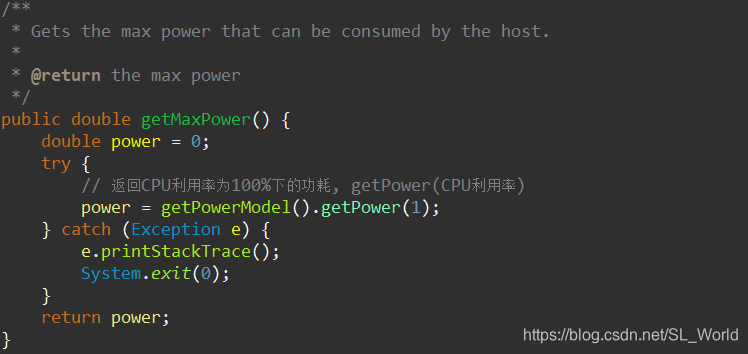
完整实现如下
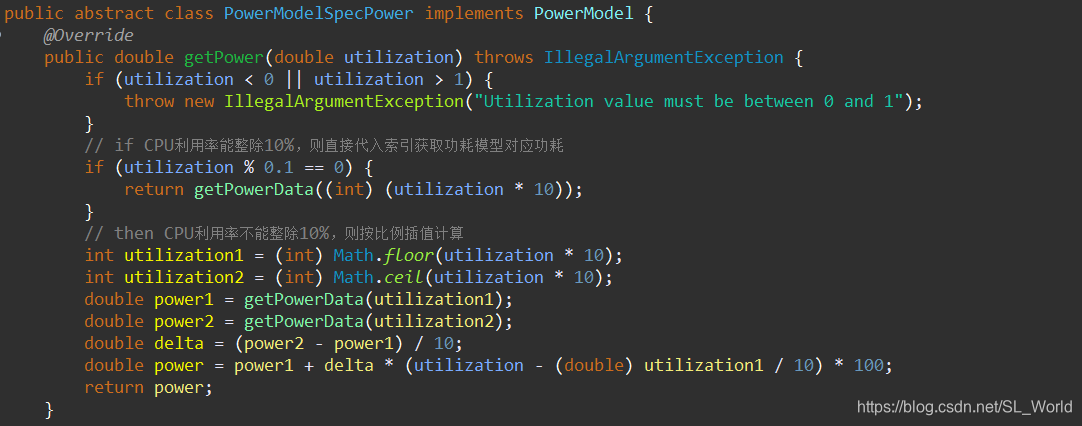
1.8.2 功耗感知数据中心(PowerDatacenter)
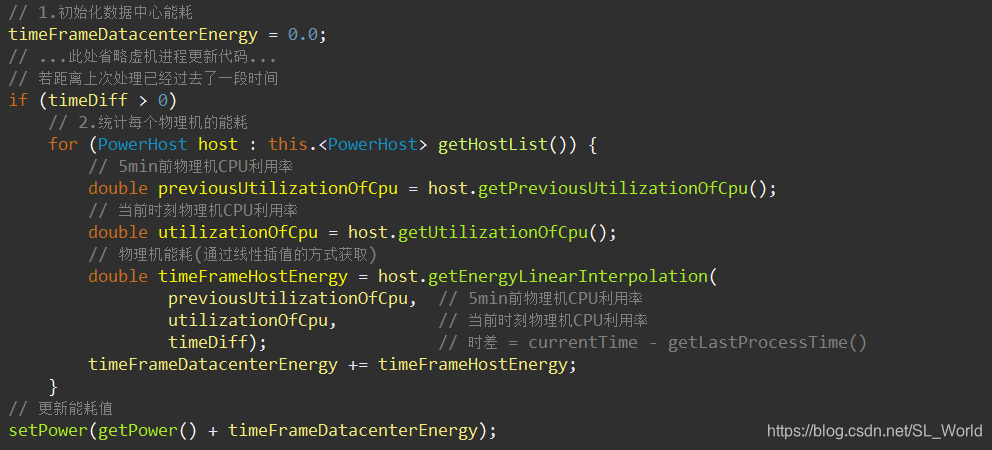
通过进入datacenter.getPower()方法,我们进入PowerDatacenter.java类中,在updateCloudetProcessingWithoutSchedulingFutureEventsForce()我们最终找到,获取数据中心能耗的流程。
- 初始化当前数据中心能耗 = 0
- 统计该数据中心的每个物理机的能耗
- 每个物理机的能耗通过,对5min前和当前时刻两物理机CPU利用率间进行
线性插值的方式计算得到 - 累计所有物理机能耗最终得到该数据中心总能耗
线性插值的方式很简单,两点中取中间点即可
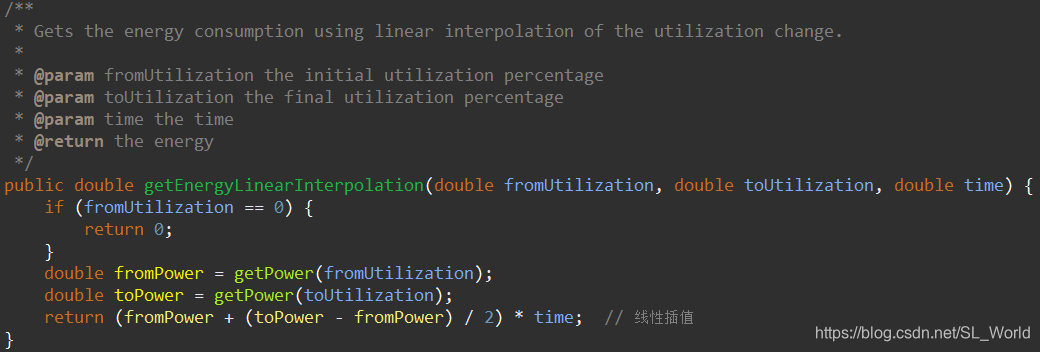
此处的getPower(利用率)即是使用该物理机功耗模型,输入利用率,获取对应的能耗值得到
1.9 载入PlanetLab 2011/3/3一天的CPU利用率数据进行实验
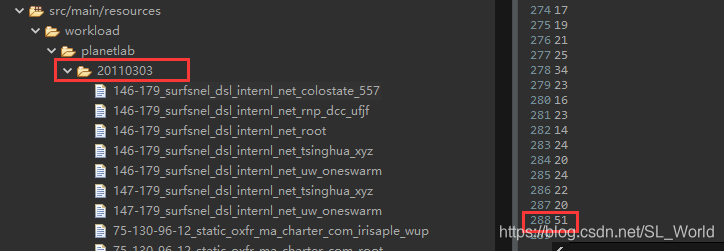
1.9.1 数据特征
2011/3/3当天有约1052个不同虚拟机CPU利用率数据文件,每个数据文件表示对应型号物理机当天的CPU利用率变换,采样频率为5min一次,1天共288个样本
1.9.2 具体修改
- 加载PlanetLab当天数据文件
String inputFolder = NonPowerAware.class.getClassLoader().getResource("workload/planetlab/20110303").getPath();
这里可以把不同虚拟机在不同时刻的CPU利用率当做该虚拟机在不同时刻的负载,依然和上面相同,假设每个虚机上只运行1个云任务
此处仅修改云任务创建方法即可,其余方法无需改动

进入到createCloudletListPlanetLab()方法,我们重点看for循环中的云任务创建过程,这里我们将某虚机1天的CPU利用率数据载入到该云任务中
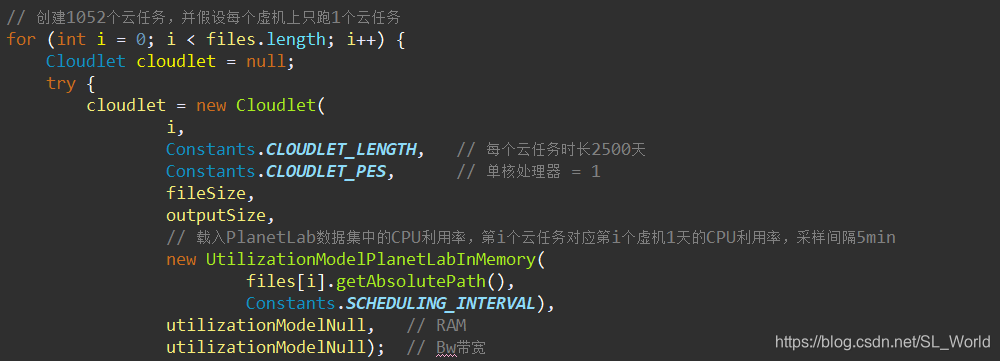
关于载入真实数据的方法,在1.3 初始化云任务(CloudletList)—如何载入自定义真实数据集中的CPU利用率?中介绍过,此处不予赘述。
以下给出基于功耗感知和非功耗感知在PlanetLab数据集同一天同样参数设置下的结果,在没有任何策略优化的情况下,功耗感知对功耗的实际计算更为贴切
| PlanetLab数据 | 主机数 | VM数 | 云任务数 | VM放置策略 | 虚机调度策略 | 主机调度策略 | 关机主机数 | 耗能(kw/h) |
|---|---|---|---|---|---|---|---|---|
| 功耗感知 | 800 | 1052 | 1052 | First Fit | 时间共享 | 时间共享 | 457 | 803.91 |
| 非功耗感知 | 800 | 1052 | 1052 | First Fit | 时间共享 | 时间共享 | 457 | 2410.8 |
只需修改数据中心类别即可切换以上两种数据中心的不同功耗结果
二、ThrRs案例
2.1 基本概述
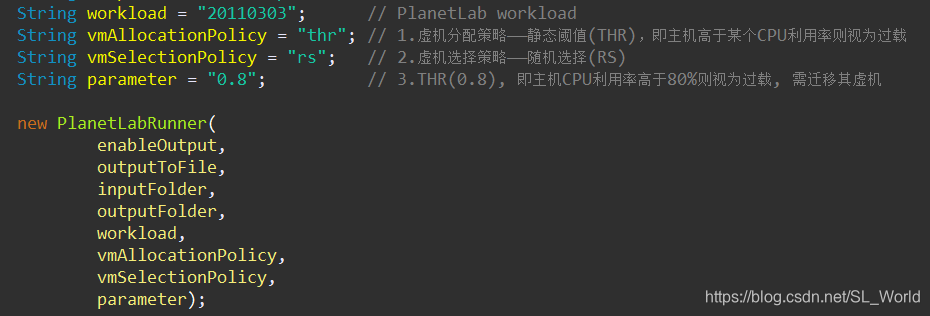
位置:org.cloudbus.cloudsim.examples.power.planetlab中的ThrRs.java
功能:对异构功耗感知数据中心的仿真,该数据中心应用静态阈值THR虚拟机分配策略 + 随机RS虚拟机选择策略
| 主机过载检测法 | 虚拟机选择法 | 虚拟机分配法 | |
|---|---|---|---|
| ThrRs | Thr(0.8) | Random Selection, RS | First-Fit-Decrease, FFD |
2.2 参数设置 + 云任务/虚机/主机初始化
有了第一个案例的讲解,后面基本差不太多,只要知道核心流程即可,具体代码见源码
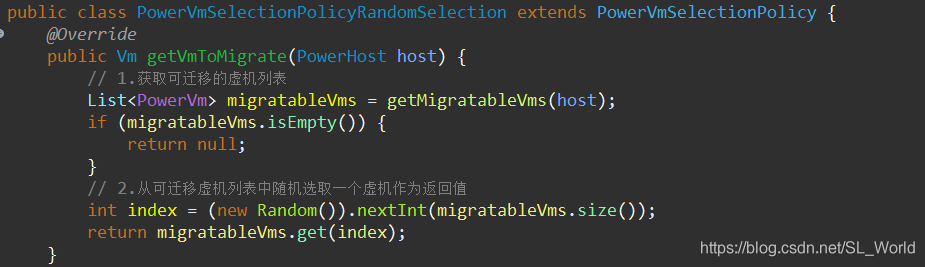
2.3 获取选择虚机策略(返回选择的虚机Vm)


- 先获取可迁移虚机列表
- 再从中随机选取一个虚机作为返回值
2.4 代入已选择要迁移的虚机,设置虚机(重)分配策略



进一步发现只是设置接口中的vmSelectionPolicy全局参数而已,具体在哪里会用到?以及是怎么用的呢?答案就在该接口对应的optimizeAllocation方法中,由于核心分配逻辑在该函数中,接下来,我们重点剖析optimizeAllocation方法
2.5 虚机迁移策略optimizeAllocation源码剖析
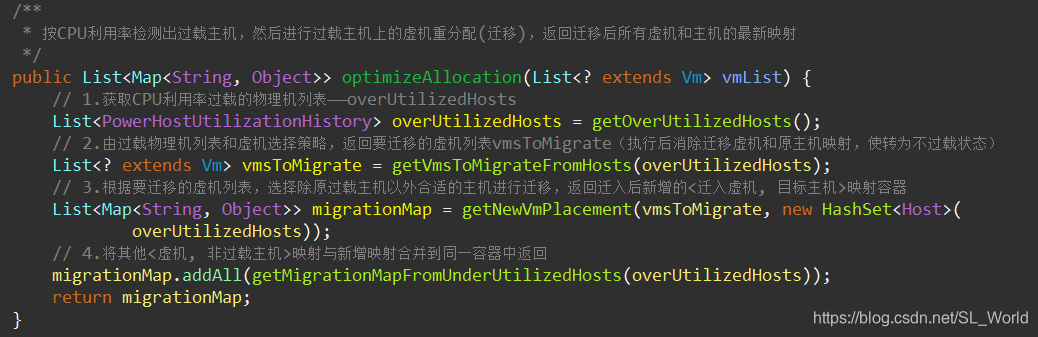
【函数功能】:按CPU利用率检测出过载主机,然后进行过载主机上的虚机重分配(迁移),返回迁移后所有虚机和主机的最新映射
主要过程如下(已省中间日志和时间记录代码)
- 获取CPU利用率过载的物理机列表(eg.>80%)——
overUtilizedHosts - 由过载物理机列表和虚机选择策略,返回要迁移的虚机列表
vmsToMigrate(执行后消除迁移虚机和原主机映射,使转为不过载状态) - 根据要迁移的虚机列表,选择除原过载主机以外合适的主机进行迁移,返回迁入后新增的
<迁入虚机, 目标主机>映射容器 - 将其他
<虚机, 非过载主机>映射与新增映射合并到同一容器中返回
以下,我们进入到每个函数中,更深入了解内部处理机制
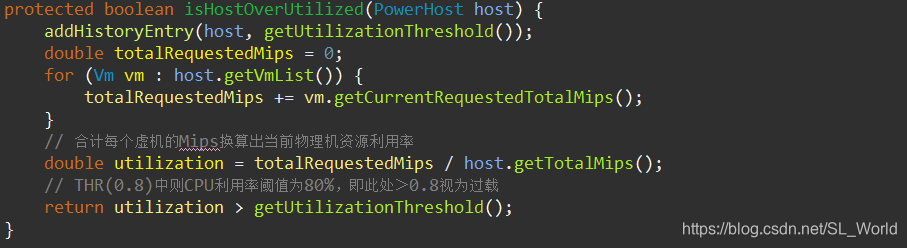
2.5.1 过载主机检测策略 —THR(0.8)
过载主机检测法——THR(0.8)'
- 返回过载主机列表:
overUtilizedHosts
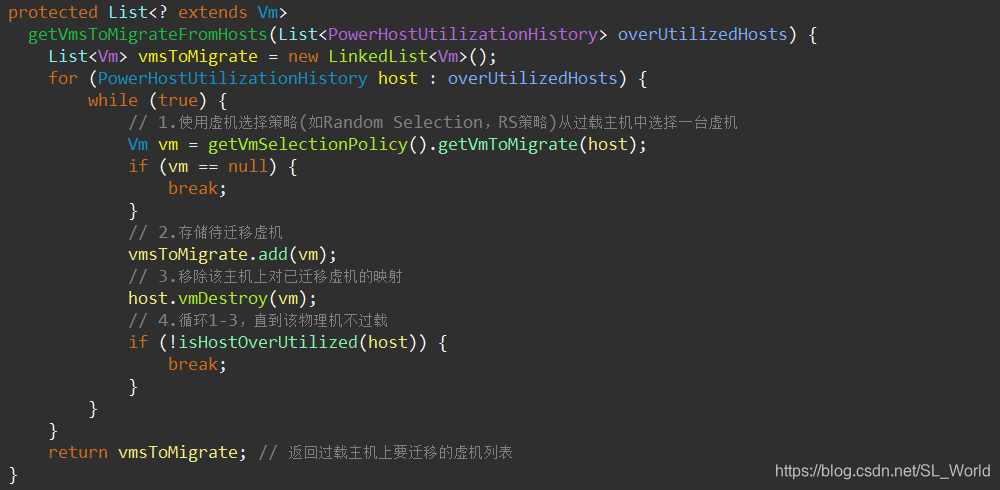
2.5.2 选择待迁移虚机(从过载主机中依vmSelectionPolicy策略)—RS
此处用到之前传入的虚机选择策略——vmSelectionPolicy = 'rs'
- 返回过载主机上要迁移的虚机列表:
vmsToMigrate
2.5.3 选择目标迁入主机(选择除原过载主机以外合适主机进行迁移)
此处用到虚机分配策略——vmAllocationPolicy 本质为 最先降序分配(First-Fit-Decrease, FFD)
- 返回迁入后新增的
<迁入虚机, 目标主机>映射容器:migrationMap
① 根据CPU利用率降序排序待迁移的虚机集合
② 从excludedHosts以外的主机选择适合迁入该虚机的主机
③ 将虚机迁移到目标主机上
④ 保存迁入虚机和该主机的映射
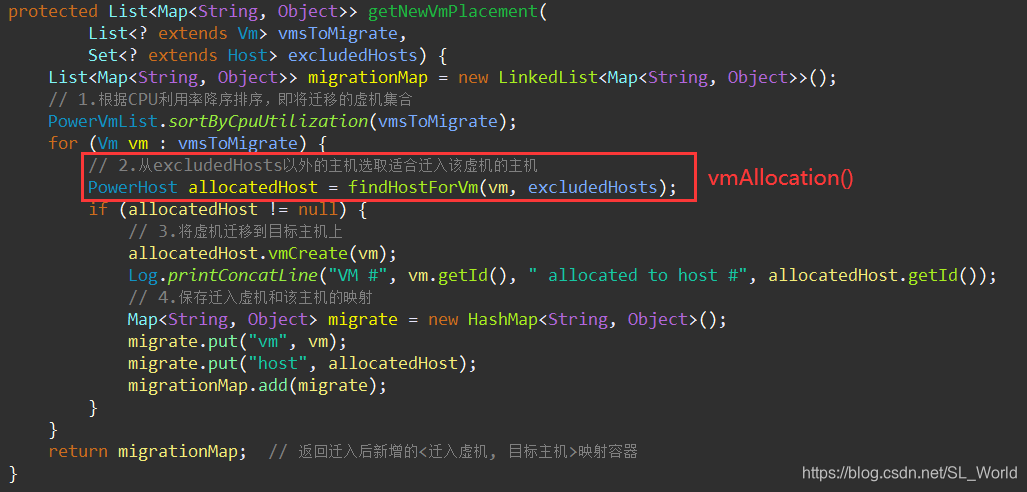
- 选择迁入后
剩余资源最少的主机作为目标主机,可见该虚机分配策略为最先降序分配(First-Fit-Decrease, FFD)法
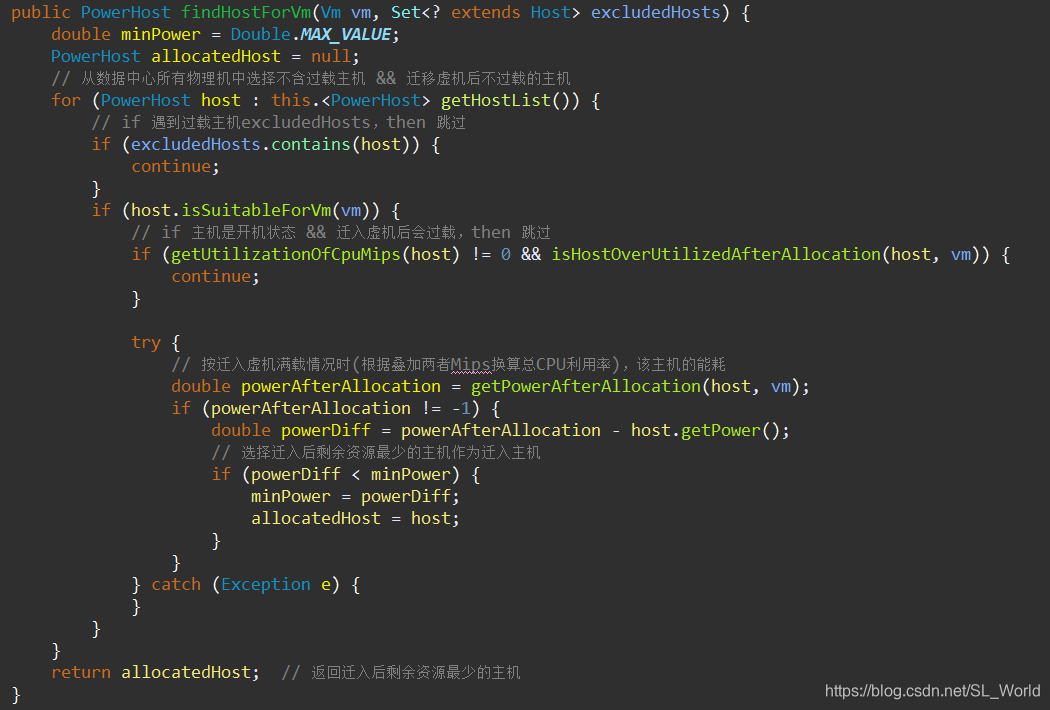
- 此处假设
处理器CPU利用率 ≈ Mips资源利用率,来估计迁入虚机后目标主机的最大CPU利用率,以判断是否过载
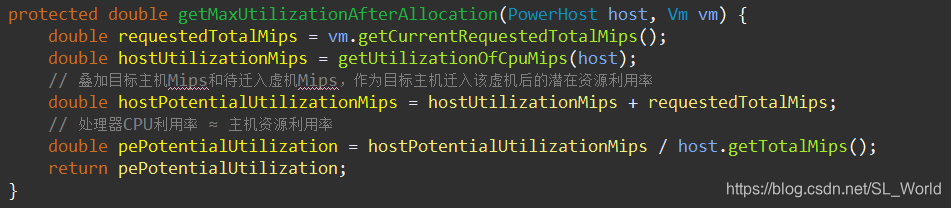
2.5.4 合并原<虚机, 主机>映射形成迁移后的完整映射
migrationMap.addAll(getMigrationMapFromUnderUtilizedHosts(overUtilizedHosts));
三、IqrMc案例
3.1 基本概述
位置:org.cloudbus.cloudsim.examples.power.planetlab中的IqrMc.java
功能:对异构功耗感知数据中心的仿真,该数据中心应用四分位距IQR虚拟机分配策略 + 选择和其他虚机CPU历史利用率相关性最大的MC虚拟机选择策略
这里只介绍主机过载检测策略(IQR) + 虚机选择策略(MC),虚机分配策略均默认最先降序分配(First-Fit-Decrease, FFD)法
3.2 参数设置

3.3 虚拟机选择策略(Maximum Correlation)
-
函数调用

-
设定备选策略(Fallback policy):选择最小迁移时间(RAM最小)的虚机
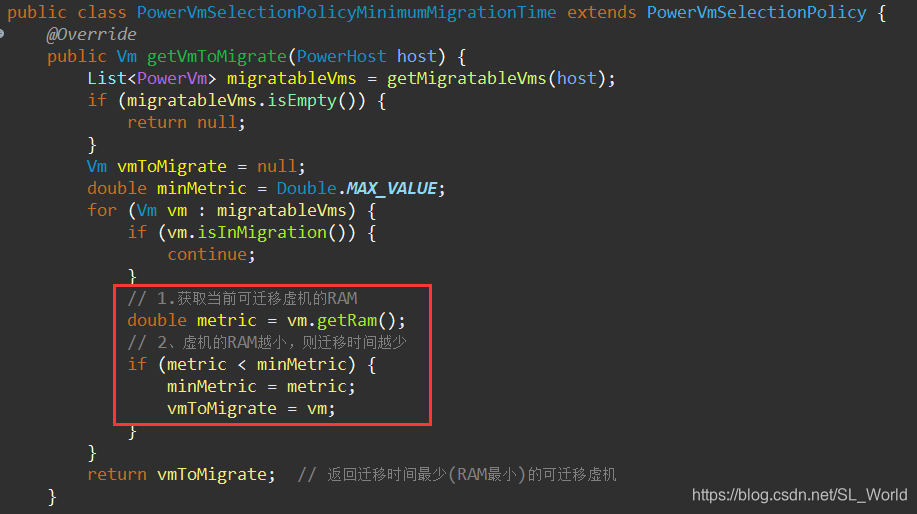
-
MC虚机选择策略
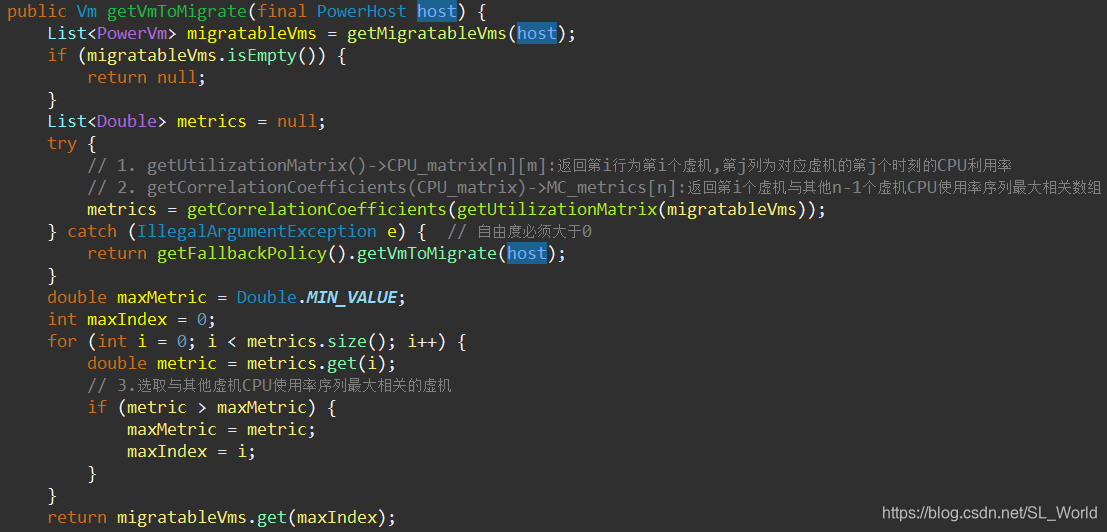
-
CPU使用率相关性列表的计算逻辑(使用最小二乘估计模型参数,使用RSquared评价模型拟合度)
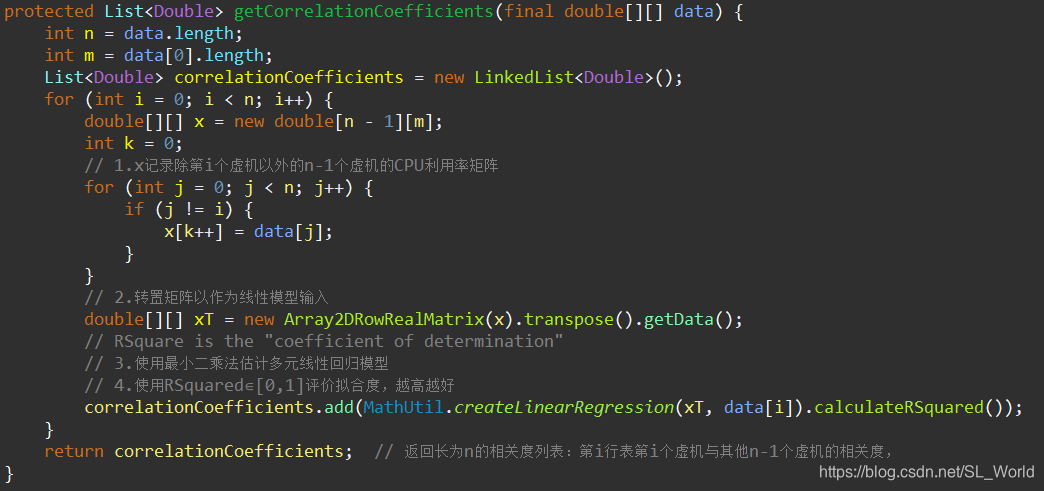
核心逻辑
correlationCoefficients.add(MathUtil.createLinearRegression(xT, data[i]).calculateRSquared());
// 把第i个虚机的CPU使用率序列当做y,对n-1个虚机CPU使用序列当做n-1个样本,建模多元线性组合模型Xb = y,并求b
correlationCoefficients.add(MathUtil.createLinearRegression(X, y).calculateRSquared());
3.4 虚拟机过载检测策略(IQR)
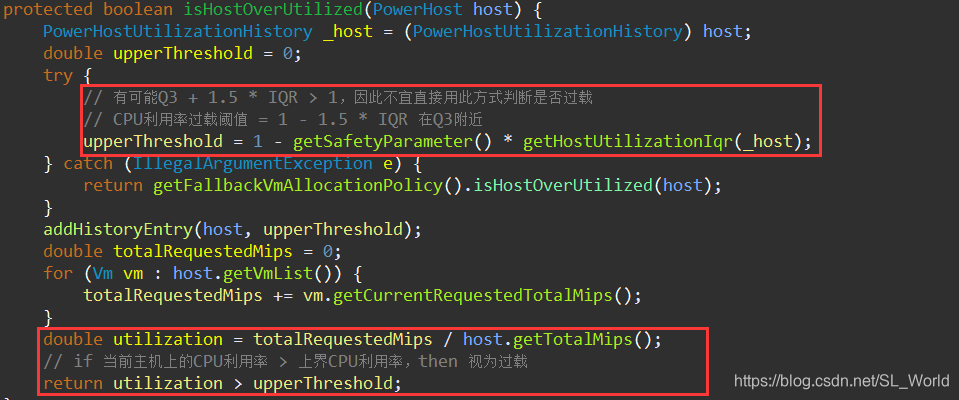
- 计算
IQR = Q3 - Q1

四、MadMmt案例
【主机过载检测MAD优点】:对异常值不敏感,不会因为特殊的异常值而导致估计的严重偏差
4.1 基本概述
位置:org.cloudbus.cloudsim.examples.power.planetlab中的MadMmt.java
功能:对异构功耗感知数据中心的仿真,该数据中心应用绝对中位数偏差Mad虚拟机分配策略 + 选择最小迁移时间Mmt虚拟机选择策略
这里只介绍主机过载检测策略(Mad) ,虚机分配策略均默认最先降序分配(First-Fit-Decrease, FFD)法
4.2 参数设置

4.3 虚拟机过载检测策略(MAD)

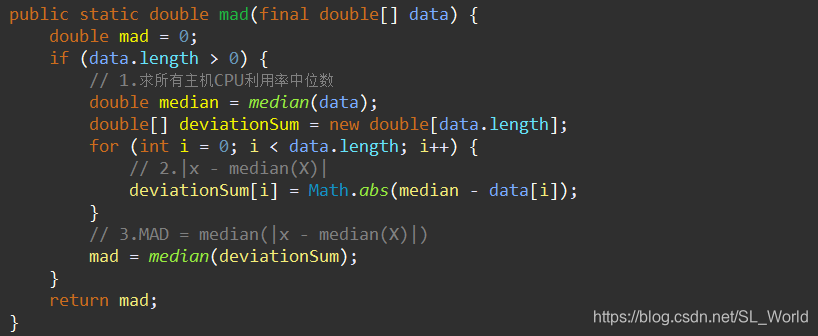


















 2887
2887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











