




阿里云又在深夜放出了新东西,这次是Qwen系列的多重更新:Qwen-Image-Edit迎来月度大升级,Qwen3-Omni全模态模型、语音生成模型Qwen3-TTS也同步开源。
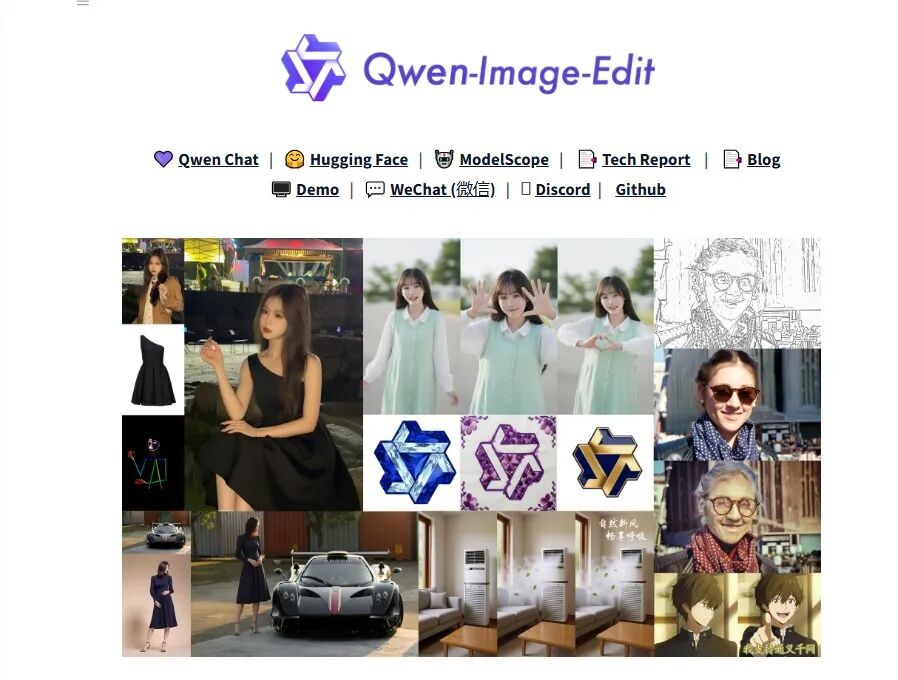
这次或许真的可以和谷歌Nano Banana说再见了。升级后的Qwen-Image-Edit-2509,针对性解决了之前图像编辑里的不少麻烦。之前处理多张图片拼接时,总容易出现边缘生硬、风格不统一的问题,现在它能轻松应对“人+产品”“人+场景”这类组合输入,1到3张图的融合效果尤其自然。

更实用的是一致性提升,编辑人像时不管怎么换姿势、调风格,面部特征都能保留得很好,做产品海报时也不用担心修图修到产品本身走样。
文字编辑也比以前灵活,不只是改内容,字体、颜色甚至材质纹理都能调整,加上原生支持的ControlNet功能,深度图、边缘图这些精准操控工具都能直接用,不用再额外找插件。



而同样值得关注的,是首个原生端到端全模态模型Qwen3-Omni的发布。
之前用多模态模型,总免不了在文本、图像、音频这些不同类型的处理之间切换,效率不高还容易出偏差,而Qwen3-Omni终于实现了统一处理。
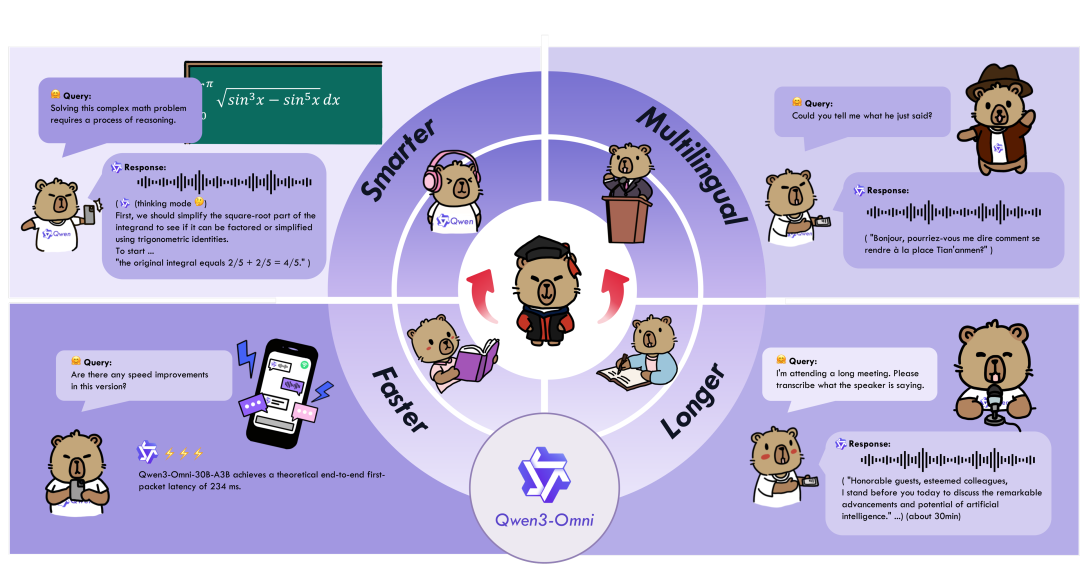
它能同时接收文本、图像、音频和视频输入,然后直接用文本或自然语音输出结果,36项音频和视频基准测试里有22项都达到了最新水平,开源范围内更是32项领先,自动语音识别这些核心能力已经能和Gemini 2.5 Pro看齐。
同时,多语言支持上它也做了不少扩展,文本能处理119种语言,语音输入支持19种,输出也有10种,连粤语这样的方言都包含在内。
实时交互的延迟控制得也不错,这对于需要轮流对话的场景很重要,比如做客服机器人或者实时翻译,不会有明显的卡顿感。
其专门开源的Qwen3-Omni-30B-A3B-Captioner模型,还填补了开源社区在精细音频描述领域的空白。
同步发布的Qwen3-TTS也藏着实用的升级,17种音色每种都支持10种语言,不仅有常见的多国语言,还有闽南语、四川话这些方言选项。
Qwen3系列提供了从0.6B到235B不同规模的版本,最小的0.6B模型在普通手机上都能流畅运行,日常的推理任务完全能应对。旗舰版的235B模型也不用复杂的硬件配置,4张H20就能部署,显存占用只有性能相近模型的三分之一。
开发团队提到,他们花了很多时间解决那些不花哨但实用的问题,比如平衡不同领域的数据、稳定扩展强化学习。
这种务实的思路在模型里体现得很明显:Qwen3-Omni的“思考者-表达者”架构,能根据任务轻重切换思考模式,复杂问题慢慢推理,简单问题快速响应,帮用户在效果和成本之间找平衡;不同规模的模型覆盖从手机到企业服务器的全场景,不用为了性能被迫投入过高成本。
从图像编辑的细节优化到全模态的统一处理,能看出来是在顺着用户的实际需求往下走。对于一直在找好用又实惠的AI工具的人来说,这样的更新或许比那些噱头满满的发布会更值得关注。


















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









