 DeepSeek V3.1升级,可处理13万字长文本
DeepSeek V3.1升级,可处理13万字长文本





昨晚,DeepSeek 宣布其线上模型版本已升级至 V3.1。此次更新虽非市场期待的 R2 系列,但在长文本处理能力上实现显著突破,将上下文窗口从 64K 扩展至 128K,相当于可处理 10 万至 13 万汉字内容。
新模型采用稀疏混合专家架构(MoE)与多头潜在注意力机制(MLA),总参数量达到 685B,激活参数量为 37B per token,在保持高性能的同时控制计算成本。关键技术创新包括分块注意力机制和旋转位置编码优化,有效降低长序列处理的显存占用。
总的来说,新模型与 DeepSeek-V3-0324 相比,在参数量等方面没有明显变化。
媒体与社区信息显示,线上网页、App与小程序入口已切换到新版本,API 调用方式保持不变;开源侧则上传了 Base 权重。
目前,该模型已经冲上了 Hugging Face 热门模型榜第 2 位:
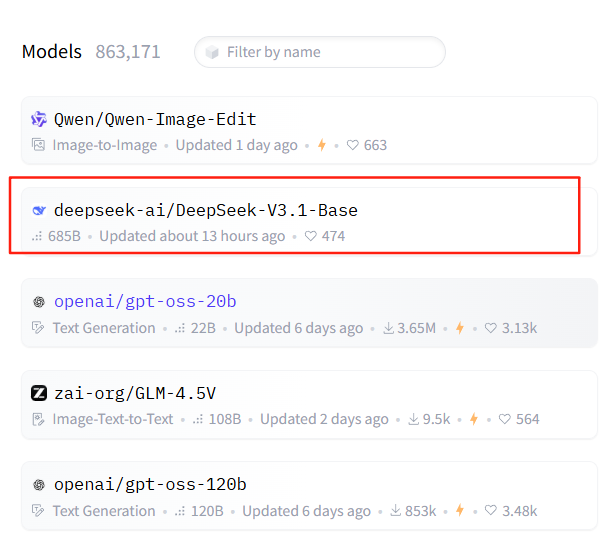
值得注意的是,将 Base 权重放到平台而不急于公布一长串基准分数,意味着团队更看重把“可复现与可部署”的阈值拉低,让社区先行试跑,收集真实场景反馈,再补齐系统性的评测材料。对于希望做私有化适配的团队,这样的节奏反而更友好:先验证推理链路、量化与张量格式,再决定是否大规模迁移。
当然,V3.1 并不等于 R2。后者背负的外界预期更多在新范式与更高上限,而前者强调的是当下可用性。在上游硬件与供应链仍有不确定性的时候,模型路线的快与稳很难兼得。
V3.1 是一个强调可用性的版本,它不会解决所有对 R2 的期待,却能在当下把体验拉齐,维持产品与生态的活跃。
回顾 DeepSeek 今年的几次更新,基本都是变动不大的小更新,这里我整理了 DeepSeek-R1 发布以来的一系列模型更新的时间节点:
| 时间 | 模型名称 | 特点 |
| 2025年1月底 | DeepSeek-R1 | 初始发布。 |
| 2025年3月 | DeepSeek-V3-0324 | 模型参数约660B,网页端、App和API提供64K上下文,开源版本上下文长度为128K。 |
| 2025年5月底 | DeepSeek-R1-0528 | R1模型的小版本升级,在数学、编程与通用逻辑等多个基准测评中表现优异,并改善了幻觉、创意写作、工具调用等功能。 |
| 2025年8月19日 | DeepSeek-V3.1 | 线上模型版本升级,上下文长度拓展至128K;多步推理任务性能提升,模型幻觉减少;编程和Agent性能显著增强。 |
尽管 V3.1 有一定改进,市场关注的 R2 模型仍未公布具体发布时间。大家认为 R2 将会在哪些方面实现新突破?欢迎交流讨论!


















 732
732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









