




昨晚,当大家还在 GitHub 上讨论 DeepSeek 刚开源的 V3-0324 模型时,OpenAI 毫无预兆地甩出了 GPT-4o 多模态生图功能,甚至免费开放。短短 24 小时,AI 行业便呈现出激烈的暗战缩影。
就在两天前,DeepSeek 刚用一场低调升级震动了技术圈:V3-0324 版本以 6850 亿参数的 MoE 架构,把单次代码生成量怼到 958 行,连 Claude 用户都跑来围观“前端代码秒出完整网页”的现场演示。
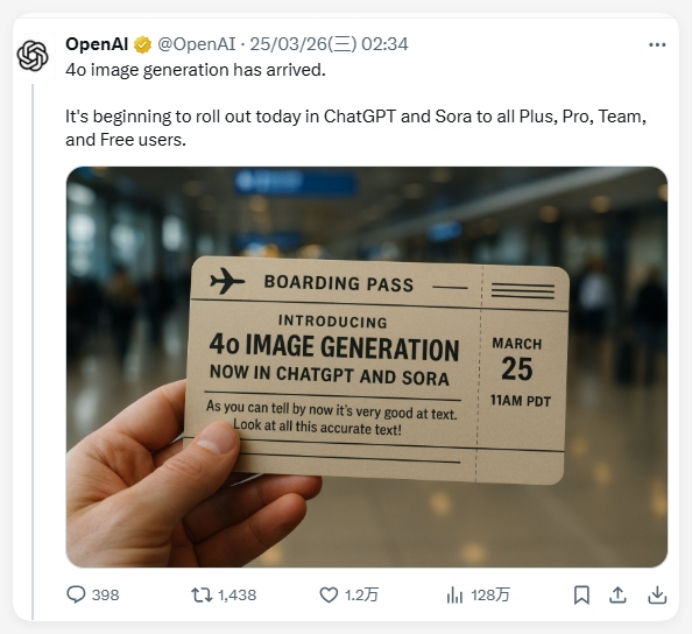
但OpenAI的“反击”来得比所有人预想得更快。24 小时后,GPT-4o 突然解锁原生图像生成,将最新图像生成模型正式内置于 GPT-4o 中,并且和谷歌的 Gemini 一样能“用嘴改图”,效果比 Gemini 还要好,所以有网友认为这波更新也是被谷歌“逼急了”。
新功能的亮点包括:
-
能够精确渲染文本内容,提供高质量的图像效果;
-
支持多种输入输出方式,涵盖文本、图像和音频等多种形式;
-
理解复杂指令并结合上下文,创造出具有真实感的第一人称视角图像;
目前可以在 ChatGPT 上体验 4o Image Generation 功能。
先来看看官网给出的出图案例:
提示词:一张用手机拍摄的宽幅图像,显示一个玻璃白板,位于俯海湾大桥的房间里。视野中可以看到一位穿着印有大型 OpenAl 标志的T恤的女性正在书写。字迹看起来自然且有些凌乱,我们可以看到摄影师的倒影。

更令人瞩目的是,GPT-4o 支持多轮对话修改功能。用户可以通过连续的对话逐步调整图像内容。
例如:摄影师的自拍视角,她转身与他击掌。

同时,4o 将精确符号与图像融合的能力,将图像生成变为一种真正的视觉交流工具。
提示词:创建一张逼真的照片,内容是两名 20 多岁的女巫(一名是灰白色挑染发型,另一名是长卷的红褐色头发)正在阅读一个街标。背景:纽约威廉斯堡一条普通的城市街道,一根电线杆上完全被许多详细的街标覆盖(例如,街道清扫时间、需要停车许可证、车辆分类、拖车规则),包括中间的几个荒谬的标志:Broom Parking for Witches Not Permitted in Zone C,Magic Carpet Loading and Unloading Only (15-Minute Limit) 等等。人物:一名女巫拿着一把扫帚,另一名女巫拿着一个卷起的魔法地毯。她们在前景中,身体微微背向相机,头部微微倾斜,仔细查看标志。从背景到前景的构图:街道 + 停放的汽车 + 建筑物 → 街标 → 女巫。人物必须是离拍摄相机最近的。

小编也来实测了一波:
提示词:水墨画风格的老虎,背景是泼墨山水,留白构图。

短短几秒的时间,就生成了一张效果不错的中国风图片。
可以看出 GPT-4o 的出图质量已经非常成熟。它的颠覆性在于其原生多模态基因:不同于传统AI绘画工具需要单独调用图像模型,GPT-4o 的神经网络能同时处理文本、图像、语音输入,实现真正的“全链路创作闭环”
对比 Midjourney 30 美元/月的订阅费,GPT-4o 每日 3 次免费额度也能满足个人创作者轻量需求。
AI绘画生态或将被重构
这场看似简单的功能升级,有可能会改变 AI 绘画格局,重构整个创作生态。当我们在讨论 GPT-4o多 模态生图时,本质上在讨论创作本质的重新定义。
算—AI算
大家有什么看法呢?欢迎在评论区留言讨论哦~


















 241
241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









