




InternVL2-2B 模型是 InternVL 系列多模态大型语言模型(MLLM)中的一员,以下是对该模型的详细介绍:
一、模型概述
InternVL2-2B 是一个专门设计用于处理和理解多种类型数据输入(如图像和文本)的深度学习模型。它结合了视觉和语言模型的优势,能够执行复杂的跨模态任务,如图文匹配、图像描述生成等。通过整合视觉特征和语言信息,InternVL2-2B 在多模态领域取得了出色的表现。
1.模型特点
- 多模态输入能力 :InternVL2-2B 支持多种输入模态,包括文本、图像等,使得模型能够处理更加复杂和多样的输入数据。
- 多任务输出能力 :得益于其强大的解码器连接能力,InternVL2-2B 可以支持多种输出格式,如图像、边界框和掩码等,展现了广泛的通用性。
- 高性能 :在各种基准测试中,InternVL2-2B 展现了与商业闭源模型相匹配的性能,特别是在文档和图表理解、信息图表问答、场景文本理解和 OCR 任务等方面表现出色。
- 可扩展性 :InternVL2-2B 是 InternVL2 系列中的一个成员,该系列还包括从适合边缘设备的 2B 模型到更为强大的 108B 模型等多个版本,用户可以根据具体需求选择合适的模型规模。
2.模型结构
InternVL2-2B 模型由以下几个主要部分组成:
- 视觉编码器 :负责处理图像数据,提取图像特征。
- 语言模型部分 :负责处理文本数据,理解语言信息。
- 多模态融合层 :将视觉编码器和语言模型部分的输出进行融合,生成跨模态的表示。
3.模型应用
InternVL2-2B 模型可以广泛应用于各种需要跨模态理解和生成的任务中,如:
- 图文匹配 :根据图像内容生成与之匹配的文本描述或根据文本描述检索相关图像。
- 图像描述生成 :自动为图像生成准确、流畅的文本描述。
- 视觉问答 :根据图像内容回答用户提出的问题。
- 多模态检索 :在包含图像和文本的多模态数据集中检索相关信息。
二、构建说明
建议使用 RTX3060 及以上显卡
1. 安装 miniconda
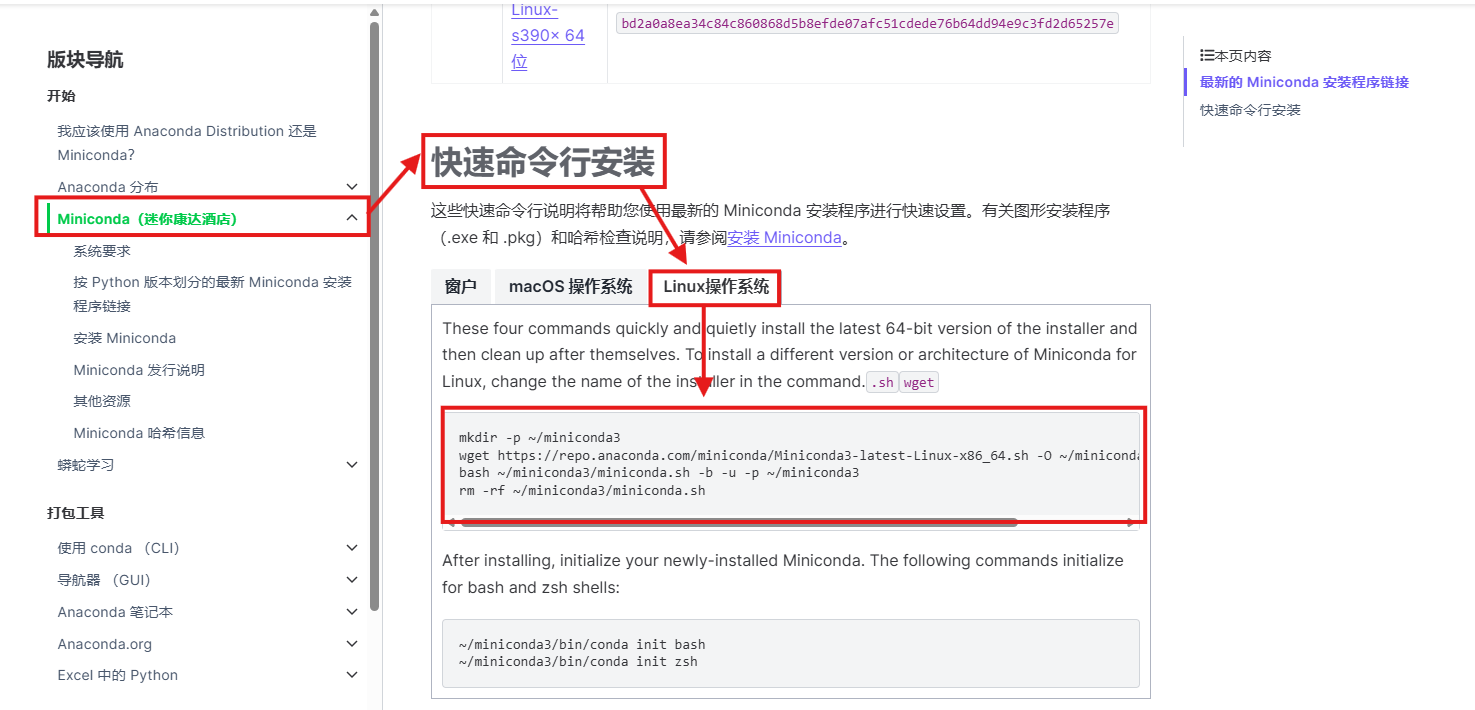
进入 Anaconda 官网:
找到快速命令行安装,选择 Linux 系统,复制代码进入终端中进行安装。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 725
725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









