




前段时间在做点云深度学习网络课题时,随手在博客“ModelNet40 中加入自己的数据集”中放了两串代码,目的是方便自己的存取(当时不会GIT的菜鸟)。结果成了所写博客中访问最多,提问最多的博文(瑟瑟发抖)。近段时间在恶补语言基础知识,索性换换脑,将这部分的知识进行一个相对完整的整理。希望对那些想快速入手点云深度学习,用来做课设、毕设的小朋友一点点帮助。以下都是个人的所学所思所想,不一定正确,仅做参考。也欢迎各路大神指出问题,将虚心改进。
一、组织架构
为了遵循博客简短干货原则,也为了更细致的描述及解决问题,我将该问题分成了3部分,分别如下:
二、数据集的分类
深度学习网络从二维扩展到三维是一个必然趋势。相较于二维图像,三维点云可以包含更多的信息。近几年来二维图像深度学习的发展似乎逐渐升级到一个瓶颈期,各种技术在短短几年内快速爆发,在各种图像问题上都达到了相当高的精度,因此突破性的想法也越来越难形成。导致很多研究者将目标对准了三维点云。在2017年PointNet提出之前,基于多视角,基于图像,基于体素的点云分类分割方法在缓慢的尝试和更新。2017年以后以PointNet为首的直接在点云上进行分类分割的深度学习网络迅速爆发。特别是在2019-2020,CVPR,ECCV等顶会上,3D出现的频次明显提高。
那说到深度学习,最让人头疼的其实就是数据集。好在许多科研机构,无私的贡献了相当多类型的三维数据集,为推动行业的发展默默贡献着。按照数据集在深度学习网络中使用方式的不同,我将这些数据集分成了两类:大型数据集和小型数据集
清新脱俗的名字,当然这里的大不是指数据集包含的点云个数的多少,而是每个点云的点数的多少。下面将列举一些常见的数据集进行说明。
三、大型数据集
大型数据集指一个点云中包含的对象或场景非常大,直观表现就是点数非常多的数据集。
1、Stanford Large-Scale 3D Indoor Spaces (S3IDS)
链接: http://buildingparser.stanford.edu/results.html
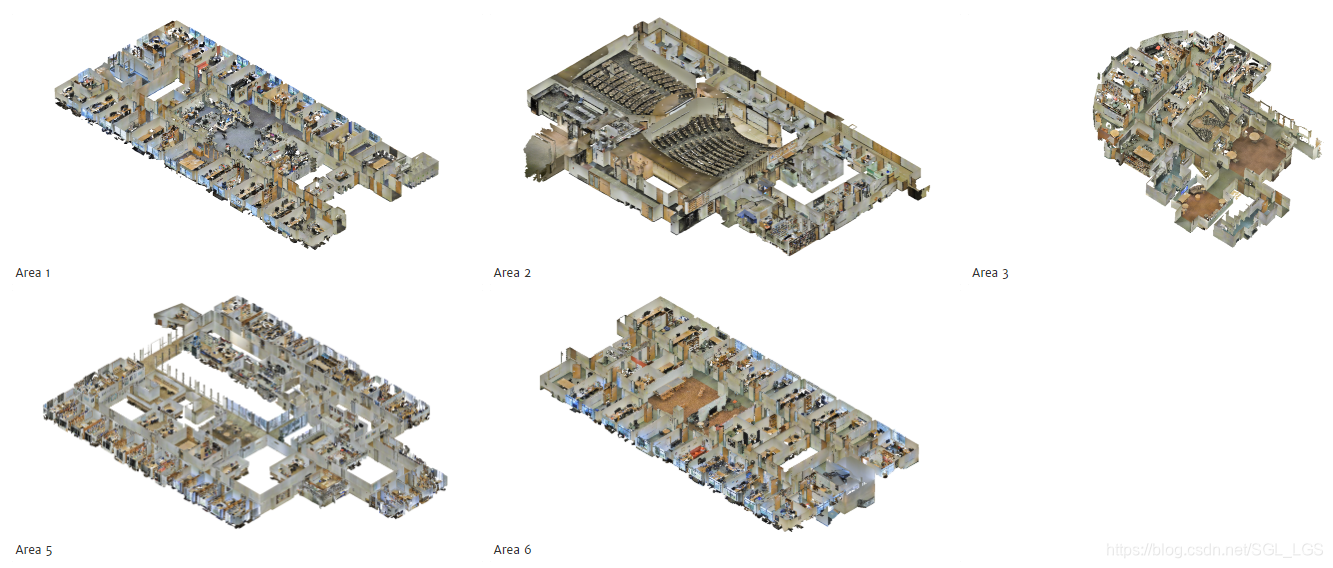
斯坦福室内数据集是由6个大型室内区域组成(如上图所示),每个区域又分为若干个房间,一共有271个房间,13个语义类别(例如:桌子,板凳,墙壁,沙发等)。
2、Virtual KITTI dataset(vKITTI)
链接:https://europe.naverlabs.com/Research/Computer-Vision/Proxy-Virtual-Worlds/

虚拟激光雷达点云是一个大型的室外道路点云,也包含了13个类别(例如:汽车,道路,树木等)。
上述两个数据集就是列举的大型数据集,当然还有很多其他的。我们的目的不是为了详细介绍这些数据集的来源等,就是为了让大家知道何为“大”。上述数据集的每个房间或者每个场景点云都包含几万到几十万甚至上百万的点。对点云深度学习网络有一定了解的小伙伴一定都知道目前网络输入的点受限于设备计算能力等一般输入点数为(1024,2048,4096最多到了8192)。因此直接将每个点云输入到网络中明显是不可行的。而数据的预处理,对于网络的性能影响是非常大的,因此接下来介绍下对此类大型点云,一般的深度学习网络是如何进行预处理的。
三、大型数据集的预处理
其实想法非常简单两个字足以说明一切“切和降”,切指将每个大型点云切分成一定规格的Blocks。降指降采样手段,将每个block的点数进一步的降低或者规范到固定的数量,作为网络的输入。下面就两篇论文介绍其数据预处
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2517
2517









 到【灌水乐园】发言
到【灌水乐园】发言







