 Hadoop搭建难题:web访问与NameNode启动故障解决方案
Hadoop搭建难题:web访问与NameNode启动故障解决方案





 本文详细阐述了在Hadoop搭建过程中遇到的两个常见问题:NameNode无法启动和web访问通过主机名受限。首先,解决NameNode启动失败需检查并修复日志错误;其次,通过Windows和Linux hosts文件修改实现主机名映射,确保web界面可用。
本文详细阐述了在Hadoop搭建过程中遇到的两个常见问题:NameNode无法启动和web访问通过主机名受限。首先,解决NameNode启动失败需检查并修复日志错误;其次,通过Windows和Linux hosts文件修改实现主机名映射,确保web界面可用。
针对Hadoop搭建完成后无法在web上利用主机名去浏览以及启动namenode无反应的对于方案
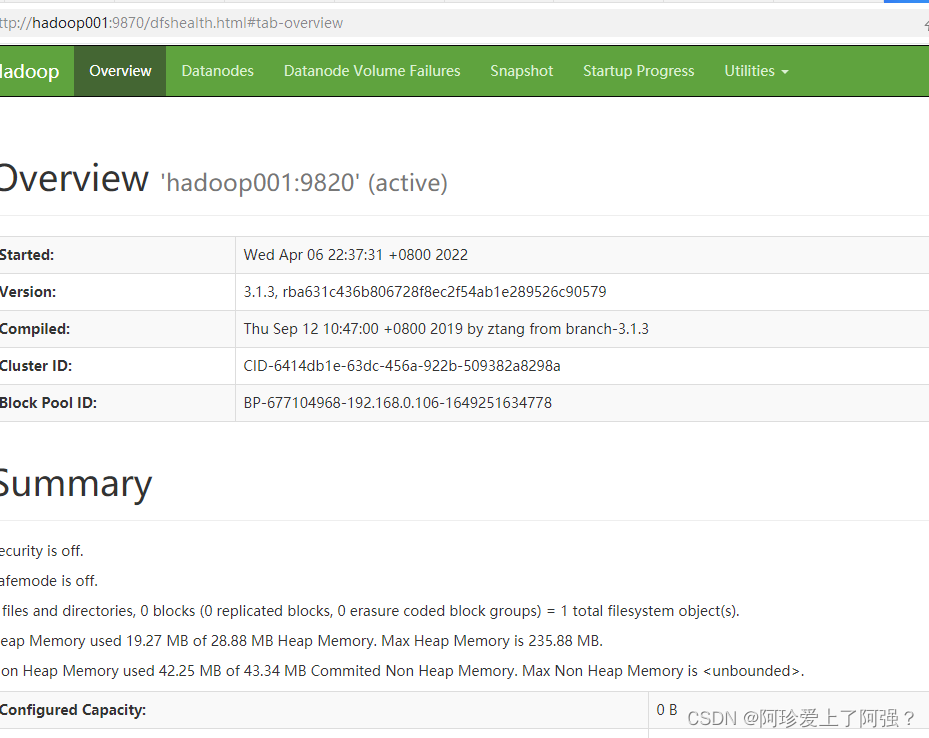
一、正常搭建后web访问一般都没问题,如下图
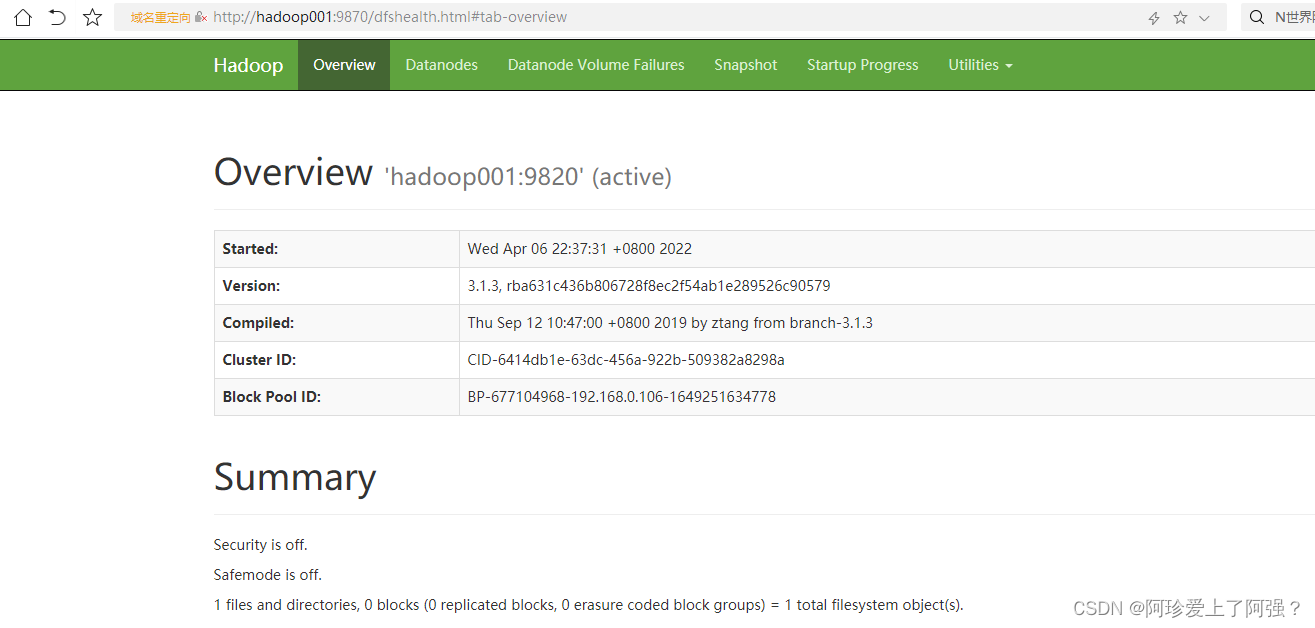
但是现实操作往往总有写问题
问题一、在hadoop目录夹下执行 start name后jps查看却未启动
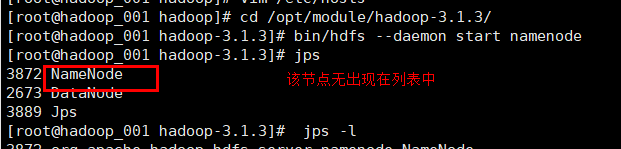
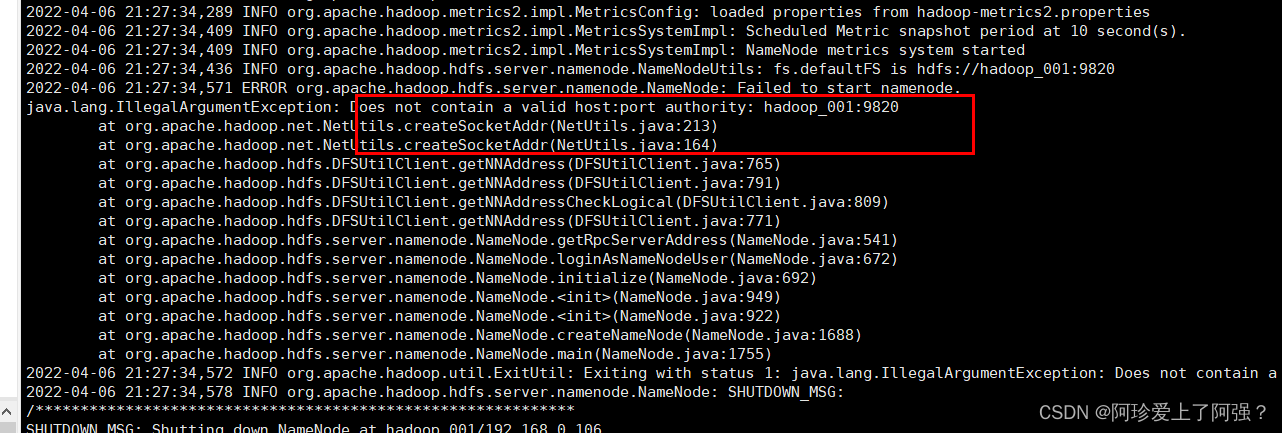
解决:查看日志文件找出对应错误:如下图错误(文件名不能出现特殊符号)
问题二、设置好映射名却无法正常打开
解决 1、windows下hosts文件映射
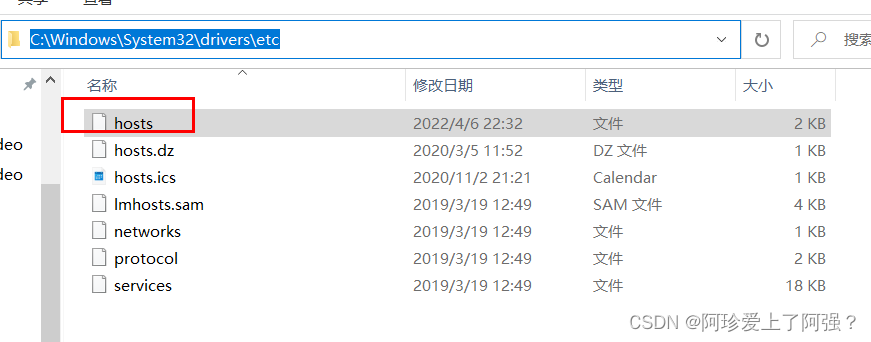 hosts为只读文件,复制一份到桌面改完再覆盖c盘下的hosts文件
hosts为只读文件,复制一份到桌面改完再覆盖c盘下的hosts文件
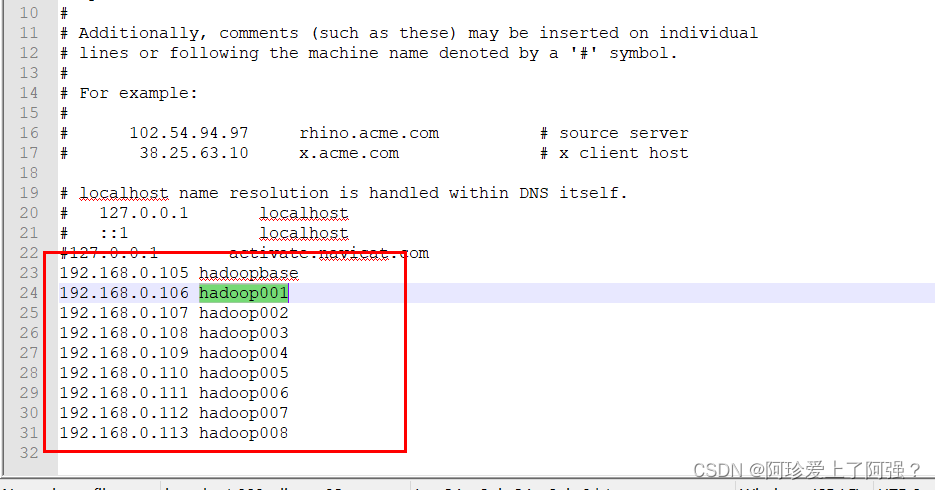 ip为linux对应ip
ip为linux对应ip
2、linux
一、关闭防火墙systemctl disable firewalld
二、vim /etc/hosts 添加对应的windows下添加的内容
再次跟进映射名就能进去了

















 891
891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









