







论文地址:https://arxiv.org/abs/2407.04287
代码地址:https://github.com/ergastialex/mars
bib引用:
@misc{ergasti2024marspayingattentionvisual,
title={MARS: Paying more attention to visual attributes for text-based person search},
author={Alex Ergasti and Tomaso Fontanini and Claudio Ferrari and Massimo Bertozzi and Andrea Prati},
year={2024},
eprint={2407.04287},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.04287},
}
模型:参考RASA基于ALBEF
摘要【两大挑战(身份内、身份外)两个组件(视觉重建损失、属性损失)】
基于文本的人物搜索 (TBPS) 是一个在研究界引起了极大兴趣的问题。该任务是根据文本描述检索特定个人的一张或多张图像。该任务的多模态性质需要学习表示,将文本和图像数据桥接到共享的潜在空间内。
现有的 TBPS 系统面临两大挑战。
- 一个被定义为由于文本描述固有的模糊性和不精确性而导致的身份间噪声,它表明视觉属性的描述通常如何与不同的人相关联;
- 另一个是身份内的变化,即所有那些令人讨厌的东西,例如姿势、照明,它们可以改变给定主题的相同文本属性的视觉外观。
为了解决这些问题,本文提出了一种名为 MARS (Mae-Attribute-Relation-Sensitive) 的新型 TBPS 架构,它通过引入两个关键组件来增强当前最先进的模型:视觉重建损失和属性损失。
- 前者使用经过训练的 Masked AutoEncoder 在文本描述的帮助下重建随机蒙版的图像块。在此过程中,鼓励模型在潜在空间中学习更多富有表现力的表征和文本-视觉关系。
- Attribute Loss 平衡了不同类型属性的贡献,这些属性被定义为形容词-名词文本块。这种损失可确保在人员检索过程中考虑每个属性。
对三个常用数据集(即 CUHK-PEDES、ICFG-PEDES 和 RSTPReid)进行的广泛实验报告了性能改进,与当前技术水平相比,平均精度均值 (mAP) 指标有了显著提高。
Introduction
TBPS 是用于在图像库中搜索特定身份的查询。这与标准的基于文本的图像检索任务类似,但在概念上有所不同,在标准基于文本的图像检索任务中,描述用于查找与给定描述最匹配的一个或多个图像。
1. 1. 研究现状
【双流分支得到嵌入学习一个共同的空间来检索最相似特征】
通常,专为 TBPS 设计的架构包括两个编码器,一个用于图像,一个用于文本提示。
编码器为每种模态提取一个潜在代码,然后可以使用各种损失函数进行对齐,例如跨模态投影匹配 [27] 或对比损失 [2]。通过这样做,文本和视觉潜在代码被迫位于公共空间中,以便人们可以使用文本嵌入来检索最相似图像的潜在代码。
【基于ALBEF、BLIP中跨模态交叉注意力层得到的结果作为重排序的前K个对象作为检索对象】
最近的方法(例如 [1, 9, 13])选择的最受欢迎的选择是微调和调整预先训练的大型视觉语言模型VLP,例如 CLIP [23]、BLIP [10] 和 ALBEF [11]。这是由于 TBPS 中常用的数据集相对较小的规模,这些数据集通常由不到 100k 的图像组成。此类大型模型提供的细粒度知识可以用作训练 TBPS 系统的可靠起点。此外,基于 BLIP [13] 或 ALBEF [1] 的架构使用跨模态编码器,该编码器通过交叉注意层将图像和文本信息融合在一起,并执行额外的匹配。更详细地说,在这样的架构中,搜索任务由两个阶段组成:在第一阶段,对于每个文本嵌入,获得 k 个最近邻图像的列表;然后,根据跨模态编码器的匹配结果对前 k 个候选者进行重新排序。
1.2. 挑战分析【身份间噪声、身份内噪声】
使用文本代替图像来执行检索既带来了一些新的可能性,也带来了新的挑战。一方面,不再需要查询图像,从而实现了更灵活、更轻松的搜索过程。另一方面,文本提示通常是模糊的或模棱两可的,并且缺乏图像所能提供的客观性。标准数据集中包含的描述(如“一个拿着黑包和白衬衫的女孩”)缺少区分相似图像所需的必要独特细节。例如,包包可以同时位于右肩或左肩,或者衬衫可以具有不同的细节,例如徽标或纹理。这种差异很小,但它们可能对应于给定视频中的不同身份。这种模糊性阻碍了定量结果在 TBPS 系统中,我们关心的是找到给定标题的精确身份,而不仅仅是最相似的图像。我们将其称为身份间噪声(见右侧的图 1)。

图 1.CUHK-PEDES 图像和标题。在左侧,a 和 b 是身份内变化的示例,其中同一个人的视觉属性(例如,姿势、照明等)在图像之间有所不同。在右侧,c 和 d 是身份间变体的示例,其中字幕可以与两个身份匹配,这两个身份看起来非常相似,但只有一个是正确的(绿色表示正确匹配,红色表示错误匹配)。
另一个关键问题由身份内变化表示(见左侧图 1)。数据集中同一主体的外观可能会因多种因素而异,例如姿势、摄像机位置(正面或背面)或照明。【典】同时,可以使用不同的文本描述来描述具有不同粒度和模糊程度的主题。这些麻烦可能会产生不可忽视的影响;例如,如果从后面捕获一个人,则“man/woman”等属性会变得更加模糊。
1.2.1. 已有的一些解决方案、不足、本文分析【考虑①文本编码技术②长文本中每个属性的贡献】
有几种方法提出了限制此问题的解决方案。
- 最常见的一种是【MLM】通过执行掩码语言建模在图像和文本嵌入之间构建更细粒度的关系 [9, 13]。这是通过屏蔽文本提示并通过交叉注意力机制利用图像补丁嵌入来预测缺失的单词来实现的。
- 或者,RaSa [1] 提出了一种除了掩码之外略有不同的解决方案,其中包括更改一些单词,然后训练模型识别哪些单词被更改。
【本文分析:文本编码技术没有充分利用给定文本中包含的所有属性,这使得检索不太精确】
in this work we argue that another problem of current TBPS systems is that
the existing text encoding techniques do not fully exploit all the attributes contained in a given text,
making the retrieval less precise. Indeed, assigning the same importance to all attributes, especially
to the most discriminative ones, is often fundamental to distinguish different identities. In fact,
two different subjects, that are yet very similar in appearance, might only be correctly separated
by a single small attribute e.g. shoes color, in their description.
除了上述内容之外,在这项工作中,我们认为当前 TBPS 系统的另一个问题是现有的文本编码技术没有充分利用给定文本中包含的所有属性,这使得检索不太精确。事实上,对所有属性,尤其是最具区分力的属性,赋予相同的重要性往往是区分不同身份的基础。事实上,两个不同的subjects,虽然在外观上非常相似,但在它们的描述中,可能只用一个小属性(例如鞋子的颜色)正确地分开。对于包含多个属性的长文本描述尤其如此,我们希望 TBPS 系统在检索过程中平均平衡每个属性的贡献。这项工作中提出的属性损失正是为了推动模型正确利用所有属性而设计的。
1.3. 本文工作【 MARS:TE+VE+CE+MAEdecoder】
在本文中,我们提出了一种名为 MARS (Mae-Attribute-RelationSensitive) 的新型 TBPS 架构,它试图进一步改进当前最先进的架构。所提出的系统由文本编码器、图像编码器、跨模态编码器和掩码自动编码器组成。此外,它还在训练期间引入了两个新的损失。
首先,提出了一种新的属性损失,它与标题和图像数据中的每组属性相匹配。这促使跨模态编码器以同等权重考虑标题中的每个属性,从而减少检索的不确定性。与 [15] 等其他方法不同,在这种方法中,除副词、限定词、特殊字符和数字之外的每个单词都被视为“属性”,我们将句子中的属性定义为遵循结构形容词 + 名词的一组单词(例如“白衬衫”)。这些集合中的每一个都形成一个属性块。匹配在跨模态编码器的输出中执行,其中对对应于每个属性块的嵌入的平均值进行分类,从而加强了文本和图像数据之间的相关性。
其次,为了进一步增强文本和图像编码器的能力,我们添加了一个受掩码自动编码器 (MAE) 架构启发的损失 [7]。在 MAE 中,编码器的输入图像被屏蔽(即,一些补丁被删除),解码器的任务是重建原始图像。具体来说,在 MARS 中,图像编码器充当 MAE 编码器,并添加了一个额外的 MAE 解码器来执行重建。此外,解码器还将从文本中提取的嵌入作为输入,以帮助指导图像重建。通过这种方式,我们的目标是进一步增强封装在图像和文本嵌入中的 mutual-information 。
2. 相关工作
Shuang等[12]首先探索了将文本和图像连接在一起以进行基于文本的图像检索和跟踪任务,他们还介绍了CUHK-PEDES数据集。此数据集由一组行人图像组成,这些图像与文本描述配对,用作查询以检索正确的主题。这个新的数据集和需要解决的问题引起了很多关注,并提出了几种方法来解决这个问题。
- Zheng等[28:Gumbel top-k 重参数化]提出了一种新的分层Gumbel注意力网络来促进跨模态对齐,
- 而Wang等[20]则提出了一种新的多粒度嵌入学习模型。另一方面,[27] 提出了跨模态投影匹配 (CMPM) 损失和跨模态投影分类 (CMPC) 损失。
- Shao et al. [18:LGUR] 引入了一个基于 transformer 的端到端框架,用于学习文本和图像的粒度统一表示。
- 此外,还有一组方法尝试使用额外的数据,如分割、姿态估计或属性预测来提高检索性能 [21, 29]。
- 此外,Wu等[22:Lapscore]介绍了两个子任务,即图像着色和文本完成。第一个选项有助于学习富文本信息以为灰色图像着色,而在第二个选项中,要求模型完成标题中的彩色单词空缺。
- Zeng 等人 [26] 提出了一个关系感知聚合网络 (RAN),利用人与本地对象之间的关系。此外,还引入了三个辅助任务:识别行人的性别、识别相似行人的图像以及对齐标题和图像之间的语义信息。
- 此外,【文本到图像搜索中的一个常见问题是存在弱正对】。Ding 等人 [5:SSAN] 首先解决了这个问题,他们在三元组损失中分配了不同的边际。
在此之前,对齐不同模态嵌入所需的视觉编码器和文本编码器都是从头开始训练的。最近,预训练视觉语言模型的使用引起了人们的注意,例如在 [3, 19, 23, 24] 中。
【IRRA、RASA、CADA】Cao等[23]对使用CLIP [16]作为TBPS的支柱进行了实证研究。其中,在 CLIP 上预训练的 IRRA [9] 引入了一个隐式关系推理模块,旨在最大限度地减少图像-文本相似性分布和归一化标签匹配之间的 KL 差异。此外,IRRA 还提出了一种掩码语言建模 (MLM),其中借助文本标记重建一组掩码图像嵌入。此外,RaSa [1] 设计了两种新颖的策略:关系感知学习 (RA) 和敏感性感知学习 (SA)。与 RaSa 的并发工作由 CADA [13] 表示,它专注于构建双向图像-文本关联。更详细地说,它尝试将文本标记与图像块相关联,并将图像区域与文本属性相关联。后者是通过修改 MLM 以掩盖特定属性而不是随机单词来完成的。
【APTM】除了对不是专门为行人识别量身定制的常见文本图像数据集进行预训练外,Yang等[25]还引入了一个名为MALS的新型数据集(多属性和语言搜索)。MALS 数据集是使用扩散模型生成的,以克服与真实数据收集相关的隐私问题和注释成本。为了评估该数据集的有效性,Yang 等人开发了一个名为 APTM(属性提示学习和文本匹配学习)的模型。
在 APTM[25] 中,作者提出了一种新的属性损失,称为图像-属性匹配 (IAM) 损失。这个损失函数旨在使用仅包含主题部分信息的简洁文本描述 T 对图像-文本对 (I,T) 进行分类(例如,“这个人穿裤子或短裤”)相反,在我们的论文中,我们提出了一个结构化的属性损失,目的是推动跨模态编码器使用标题中包含的每个属性来执行图像和文本之间的匹配。特别是,我们的损失不会像 [25] 那样构建新的描述,而是推动模型以显式的方式更多地关注属性嵌入。更详细地说,我们的模型根据句子中包含的每个属性在图像和文本之间执行额外的匹配。
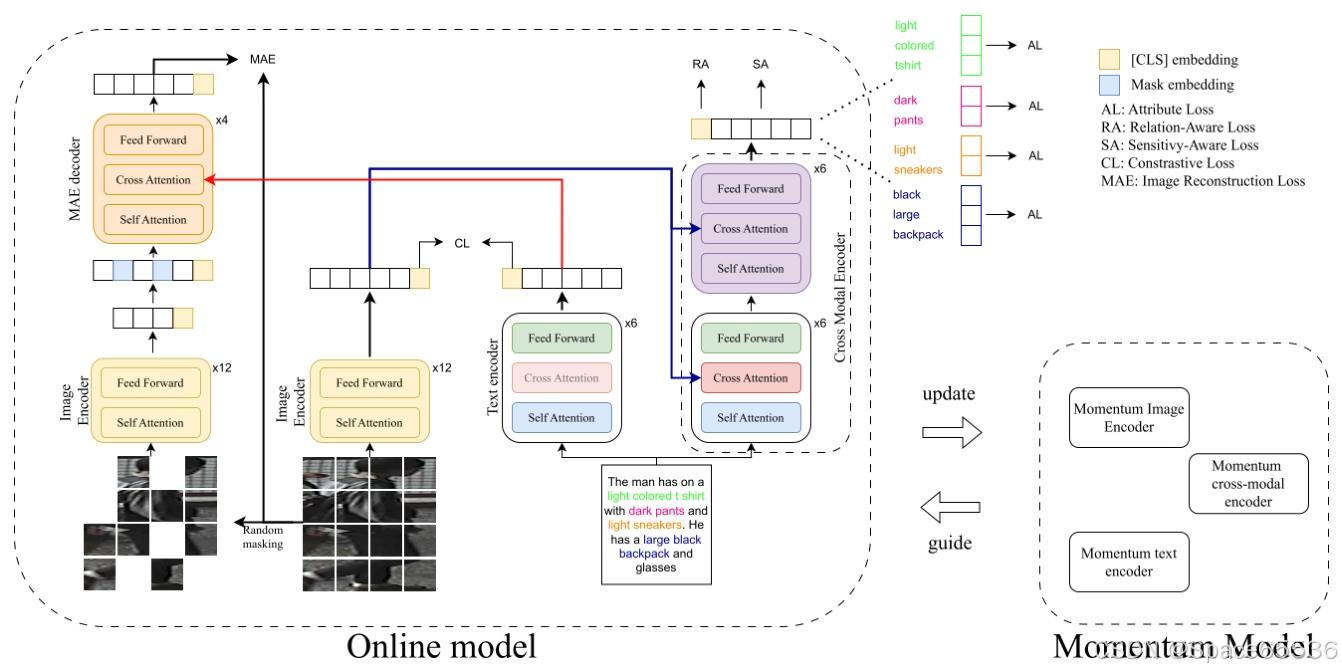
图 2.建议的架构概述 (相同的颜色对应于共享参数)。首先,将图像和文本的输入对 ( I , T ) (I, T) (I,T) 分别馈送到图像编码器 ε v \varepsilon_{v} εv 和文本编码器 ε t \varepsilon_{t} εt,并将对比损失应用于获得的嵌入向量 v 和 t。其次,训练 MAE 解码器 D m a e D_{mae } Dmae 将蒙版图像补丁序列重建为原始的未蒙版图像。最后,文本被馈送到跨模态编码器 E c r o s s E_{cross } Ecross,视觉嵌入 v 被注入到其交叉注意力层中。 E c r o s s E_{cross } Ecross f 的输出用于三种不同的损失函数:(a) 类标记 f c l s fcls fcls 用于关系感知损失中,以学习正负图像文本对之间的匹配函数,然后,(b) 给定掩码输入文本 T m a s k T_{mask } Tmask 敏感感知损失用于识别掩码词,最后,(c) 属性损失是在对应于属性的嵌入上计算的块。
3 PROPOSED METHOD
3.1. 模型架构
在本文中,我们提出了 MARS (Mae-Attribute-Relation-Sensitive),这是一种用于 TBPS 的新型架构。在构建系统时,我们决定使用 RaSa [1] 作为起点,因为目前是最好的 TBPS 模型之一,并且我们在 ALBEF [11] 上初始化了架构权重。
MARS 由四个主要组件组成(图 2):(a) 图像编码器 ε v \varepsilon_{v} εv,用于编码一系列图像补丁,(b) 文本编码器 ε t \varepsilon_{t} εt,用于从字幕生成文本嵌入,(c) MAE 解码器 D m a e D_{mae } Dmae,其任务是重建蒙版图像,最后,(d) 跨模态编码器 E c r o s s E_{cross } Ecross,用于计算我们提出的属性损失以及基线 RaSa [1] 损失:敏感感知和关系感知损失。
更详细地说,图像编码器是一个视觉转换器 (ViT) [6],由 12 个变压器块组成,这些块由自注意力层和前馈层组成。文本编码器和跨模态编码器基于 BERT [4],这是一个基于 transformer 的 12 块架构,用于语言理解。BERT 的前 6 个块用作文本编码器。另一方面,Cross-Modal Encoder 由 BERT 的所有 12 个块组成,但是,与以前的方法(如 [1, 11])不同,我们为其所有块配备了交叉注意力层,而不仅仅是最后 6 个。通过这样做,我们可以使用整个 BERT 架构执行跨模态编码,这有助于提高匹配精度,因为它将在实验中显示。最后,MAE 解码器由 4 个装有交叉注意的变压器块组成。此外,还初始化了动量模型。动量模型是在线模型的较慢版本,其权重使用指数移动平均线 (EMA) 获得:
θ
^
=
m
θ
^
+
(
1
−
m
)
θ
(
1
)
\hat{\theta}=m \hat{\theta}+(1-m) \theta (1)
θ^=mθ^+(1−m)θ(1) 其中
θ
^
\hat{\theta}
θ^ 是动量模型的权重,而 θ 是在线模型的权重,m 是动量系数。在计算 3.2 节中解释的损失时,此模型将至关重要。
在训练过程中,从图像-文本对 ( I , T ) (I, T) (I,T) 开始, ε v \varepsilon_{v} εv 为每个 M 图像块生成一系列图像嵌入 v = v c l s , v 1 , ⋯ , v M v={v_{c l s}, v_{1}, \cdots, v_{M}} v=vcls,v1,⋯,vM,同时将标记化文本馈送到 ε t \varepsilon_{t} εt,生成一系列文本嵌入 t = t c l s , t 1 , ⋯ , t N t={t_{c l s}, t_{1}, \cdots, t_{N}} t=tcls,t1,⋯,tN ,即 N 字数。在 v 和 t 中,第一个嵌入是类标记 [CLS]。此外,使用 ε v \varepsilon_{v} εv 嵌入了长度为 L < M L<M L<M 的图像块的掩码版本。然后,在获得的序列中插入一组 K = M − L K=M-L K=M−L 掩码嵌入,并将整个序列馈送到 D m a e D_{mae } Dmae,它也借助文本嵌入 t 重建原始图像,这些嵌入通过交叉注意力机制馈送到 D m a e D_{mae } Dmae 中。最后,文本 T 用作 E c r o s s E_{cross } Ecross 的输入,而图像嵌入 v 被注入 E c r o s s E_{cross } Ecross 交叉注意力层,生成跨模态嵌入 f = f c l s , f 1 , ⋯ , f N f={f_{c l s}, f_{1}, \cdots, f_{N}} f=fcls,f1,⋯,fN。跨模态嵌入的 [CLS] 标记将用于在图像和字幕之间执行额外的匹配。
评估阶段由两个步骤组成:首先,使用图像和文本编码器计算所有图像和文本嵌入,对于每个文本嵌入,通过计算文本的 [CLS] 标记与图像之间的相似性来获得最接近的图像嵌入的有序列表。然后,选择每个文本的前 k 个候选者,并考虑到 Cross-Modal Encoder 的匹配结果执行额外的重新排名阶段。这个额外的步骤可以进一步提高排名结果。
3.2 基线损失【RA、SA、CL】
作为我们模型的基线训练目标,我们采用了 RaSa [1] 中使用的损失集。此外,我们最终提出的架构还引入了两种新颖的损失:属性损失和掩码自动编码器损失。
关系感知损失。关系感知 (RA) 损失是对各种模型中常用的传统图像文本匹配 (ITM) 损失的修改 [10, 11, 25]。具体而言,ITM 在正图像文本对和负图像文本对之间执行二进制分类。ITM 变体(表示为 P -ITM)不是随机选择硬负样本,而是通过评估嵌入相似性并使用该值作为绘制负对的概率来创建负对集。这种相似性使用来自单峰编码器的 [CLS] 标记表示进行量化(图 2 中的文本和图像编码器)。选择负对的概率与相应的图像文本 [CLS] 标记的相似性成正比。因此,表现出较高相似性的负对更有可能被选择,从而增强了模型区分真正相关和不相关的图像文本对的鲁棒性。损失 L p − I T M L_{p-I T M} Lp−ITM 是一种交叉熵损失,用于区分输入对 ( I , T ) (I, T) (I,T) 是正还是负。
设
l
c
i
t
m
(
f
c
l
s
)
l_{c}^{i t m}(f_{c l s})
lcitm(fcls) 是一个全连接层,应用于
E
c
r
o
s
s
(
T
,
E
v
(
I
)
)
E_{cross }(T, E_{v}(I))
Ecross(T,Ev(I)) 的 [CLS] 令牌,它预测给定类 c 的 logit。损失可以计算为:
L
p
−
I
T
M
=
−
1
3
⋅
N
B
∑
(
I
,
T
)
∈
P
∑
c
∈
C
y
c
l
o
g
e
x
p
(
l
c
i
t
m
(
f
c
l
s
)
)
∑
n
∈
C
e
x
p
(
l
n
i
t
m
(
f
c
l
s
)
)
\mathcal{L}_{p-I T M}=-\frac{1}{3 \cdot N_{B}} \sum_{(I, T) \in P} \sum_{c \in C} y_{c} log \frac{exp \left(l_{c}^{i t m}\left(f_{c l s}\right)\right)}{\sum_{n \in C} exp \left(l_{n}^{i t m}\left(f_{c l s}\right)\right)}
Lp−ITM=−3⋅NB1∑(I,T)∈P∑c∈Cyclog∑n∈Cexp(lnitm(fcls))exp(lcitm(fcls)),
其中 c 是可能的类的集合,其中包括两个类别:正对和负对。变量
y
c
y_{c}
yc 表示真实值,其中
y
c
=
1
y_{c}=1
yc=1 如果对
(
I
,
T
)
(I, T)
(I,T) 属于类 c。集合 P 构建为三个子集的并集,因此除以 3,每个子集的大小为
N
B
N_{B}
NB 、
P
+
+
P^{++}
P++ 、
P
−
+
P^{-+}
P−+ 、
P
+
−
P^{+-}
P+− 。
- P + + P^{++} P++ 由输入批次组成,其中所有对 ( I , T ) (I, T) (I,T) 都是正数。
- P − + P^{-+} P−+ 由每张文本 T 的负片图像 I 组成,随机采样,概率由从 ε t ( T ) \varepsilon_{t}(T) εt(T) 获得的 t c l s t_{c l s} tcls 和从 E v ( I ) E_{v}(I) Ev(I) 获得的 v c l s v_{c l s} vcls 之间的相似性决定。
- P + − P^{+-} P+− 由每张图像 I 的负文本 T 组成,随机采样,概率由从 E v ( I ) E_{v}(I) Ev(I) 获得的 v c l s v_{c l s} vcls 和从 ε t ( T ) \varepsilon_{t}(T) εt(T) 获得的 t c l s t_{c l s} tcls 之间的相似性决定。
此外,通过添加正关系检测 (PRD) 扩展了 P -ITM 损失,该检测称为交叉熵损失,旨在检测弱正对。在训练过程中,通过将图像的标题与具有相同身份的不同图像的标题随机切换来构建弱正对。反之亦然,我们将强正对定义为来自数据集的原始对。假设
l
c
p
r
d
(
f
c
l
s
)
l_{c}^{p r d}(f_{c l s})
lcprd(fcls) 是一个全连接层,应用于
E
c
r
o
s
s
(
T
,
E
v
(
I
)
)
E_{cross }(T, E_{v}(I))
Ecross(T,Ev(I)) 的 [CLS] 令牌,它预测给定类 c 的 logit,则:
L
p
r
d
=
−
1
N
B
∑
(
I
,
T
)
∈
P
+
+
∑
c
∈
C
y
c
l
o
g
e
x
p
(
l
c
p
r
d
(
f
c
l
s
)
)
∑
n
∈
C
e
x
p
(
l
n
p
r
d
(
f
c
l
s
)
)
\mathcal{L}_{prd }=-\frac{1}{N_{B}} \sum_{(I, T) \in P^{++}} \sum_{c \in C} y_{c} log \frac{exp \left(l_{c}^{prd }\left(f_{c l s}\right)\right)}{\sum_{n \in C} exp \left(l_{n}^{prd }\left(f_{c l s}\right)\right)}
Lprd=−NB1∑(I,T)∈P++∑c∈Cyclog∑n∈Cexp(lnprd(fcls))exp(lcprd(fcls)) 这里
P
+
+
P^{++}
P++ 只是可以是弱或强的正对,c 是类的数量(在本例中为 2),对应于强正对和弱正对。然后,最终的 RA 损失计算为:
L
R
A
=
L
p
−
I
T
M
+
λ
1
L
p
r
d
(
4
)
\mathcal{L}_{R A}=\mathcal{L}_{p-I T M}+\lambda_{1} \mathcal{L}_{prd } (4)
LRA=Lp−ITM+λ1Lprd(4),其中
λ
1
\lambda_{1}
λ1 是一个超参数,用于平衡
L
p
r
d
L_{prd }
Lprd 的贡献。
敏感感知损失。与 RA 损失类似,敏感感知 (SA) 损失是 [9] 中引入的基本掩码语言建模 (MLM) 的扩展,它增加了基于动量的替换标记检测 ( m -RTD),给定一个强正对 ( I , T ) (I, T) (I,T) ,MLM 损失表示为交叉熵损失。给定一个掩码文本 m a s k mask mask ,其中每个单词都有被掩码的概率 P,该模型被训练为预测正确的缺失单词。设 V 表示词汇表中所有可能的单词的集合,并且 l v ( f m a s k ) l_{v}(f_{mask }) lv(fmask) 是一个完全连接层,应用于从 E c r o s s ( T m a s k , E v ( I ) ) E_{cross }(T_{mask }, E_{v}(I)) Ecross(Tmask,Ev(I)) 获得的每个嵌入,该嵌入预测词汇表 V 的 logit。MLM损失表述为:
L M L M = − 1 N B ∑ ( I , T ) ∈ P + + 1 N m a s k t ∑ w ∈ t m w ∑ v ∈ V y v l o g e x p ( l v ( f m a s k ) ) ∑ n ∈ V e x p ( l n ( f m a s k ) ) \mathcal{L}_{M L M}=-\frac{1}{N_{B}} \sum_{(I, T) \in P^{++}} \frac{1}{N_{mask }^{t}} \sum_{w \in t} m_{w} \sum_{v \in V} y_{v} log \frac{exp \left(l_{v}\left(f_{mask }\right)\right)}{\sum_{n \in V} exp \left(l_{n}\left(f_{mask }\right)\right)} LMLM=−NB1∑(I,T)∈P++Nmaskt1∑w∈tmw∑v∈Vyvlog∑n∈Vexp(ln(fmask))exp(lv(fmask))
其中 N B N_{B} NB是批量大小, N m a s k t N_{mask}^{t} Nmaskt是给定文本t的掩码单词数,如果单词被掩码, m w m_{w} mw为1,否则为0(即 N m a s k t = ∑ w ∈ t m w ) N_{mask}^{t}=\sum_{w\in t}m_{w}) Nmaskt=∑w∈tmw)和 y v y_{v} yv是基本事实词汇表上的一个热门值。另一方面,在m-RTD中,重点是检测被替换的单词。为了替换被掩码的单词,传销动量模型被采用,它缓慢收敛,提供不太准确的单词预测。传销动量模型通过有效地用其预测替换被掩码的单词,为每个被掩码的单词预测一个单词,在线模型的任务是识别这些单词中的哪些被替换了。
m-RTD损失基于交叉熵损失,它教模型区分替换和非替换单词。设c是每个单词的可能预测集,其中预测可以是“替换”或“不替换”,
l
c
(
f
r
e
p
l
))
l_{c}(f_{repl}))
lc(frepl))是应用于从
E
C
r
o
s
s
(
T
r
e
p
l
,
E
v
(
I
))
E_{Cross}(T_{repl},E_{v}(I))
ECross(Trepl,Ev(I))获得的每个嵌入的全连接层,它预测c类的logit。损失函数可以表示为:
L
m
−
R
T
D
=
−
1
N
B
∑
(
I
,
T
)
∈
P
+
+
1
N
w
t
∑
c
∈
C
y
c
l
o
g
e
x
p
(
l
c
(
f
r
e
p
l
)
)
)
∑
n
∈
C
e
x
p
(
l
n
(
f
r
e
p
l
)
)
\mathcal{L}_{m-R T D}=-\frac{1}{N_{B}} \sum_{(I, T) \in P^{++}} \frac{1}{N_{w}^{t}} \sum_{c \in C} y_{c} log \frac{\left.exp \left(l_{c}\left(f_{repl }\right)\right)\right)}{\sum_{n \in C} exp \left(l_{n}\left(f_{repl }\right)\right)}
Lm−RTD=−NB1∑(I,T)∈P++Nwt1∑c∈Cyclog∑n∈Cexp(ln(frepl))exp(lc(frepl)))
其中
N
B
N_{B}
NB是批量大小,
N
w
t
N_{w}^{t}
Nwt是给定文本t中的字数,
y
c
y_{c}
yc是基本事实。
最后的
L
S
A
L_{S A}
LSA是:
L
S
A
=
L
M
L
M
+
λ
2
L
m
−
R
T
D
(
7
)
\mathcal{L}_{S A}=\mathcal{L}_{M L M}+\lambda_{2}\mathcal{L}_{m-R T D}\quad(7)
LSA=LMLM+λ2Lm−RTD(7)
其中 λ 2 \lambda_{2} λ2是用于平衡 L m − R T D L_{m-R T D} Lm−RTD贡献的超参数。
对比损失。对比损失 (CL) 是最后一个基线模型损失。如图 2 所示,在将两个编码器(Image Encoder 和 Text Encoder)传递到线性层以在较低维度空间中投影后,仅使用两个编码器(Image Encoder 和 Text Encoder)的 [CLS] 标记来计算对比损失。给定一个图像-文本对
(
I
,
T
)
(I, T)
(I,T) ,我们从
E
v
(
I
)
E_{v}(I)
Ev(I) 获得
v
c
l
s
v_{c l s}
vcls 和从
ε
t
(
T
)
\varepsilon_{t}(T)
εt(T) 得到
t
c
l
s
t_{c l s}
tcls 。然后,将两个嵌入向量馈送到线性层中,得到
t
c
l
s
′
t_{c l s}'
tcls′ 和
v
c
l
s
′
v_{c l s}'
vcls′ 。动量模型也复制了相同的过程,获得
t
^
′
c
l
s
\hat{t}' cls
t^′cls 和
v
^
′
c
l
s
\hat{v}' c l s
v^′cls。此外,还存储了图像队列
Q
^
i
\hat{Q}_{i}
Q^i 和文本队列
Q
^
t
\hat{Q}_{t}
Q^t 以隐式放大批处理大小。然后,CL 公式表述为:
L
N
C
E
(
x
1
,
x
2
,
Q
)
=
−
1
∣
Q
∣
∑
(
x
,
x
+
)
∈
(
x
1
,
x
2
)
l
o
g
e
x
p
(
s
(
x
,
x
+
)
/
τ
)
∑
x
i
∈
Q
e
x
p
(
s
(
x
,
x
i
)
/
τ
)
\mathcal{L}_{N C E}\left(x_{1}, x_{2}, Q\right)=-\frac{1}{|Q|} \sum_{\left(x, x_{+}\right) \in\left(x_{1}, x_{2}\right)} log \frac{exp \left(s\left(x, x_{+}\right) / \tau\right)}{\sum_{x_{i} \in Q} exp \left(s\left(x, x_{i}\right) / \tau\right)}
LNCE(x1,x2,Q)=−∣Q∣1∑(x,x+)∈(x1,x2)log∑xi∈Qexp(s(x,xi)/τ)exp(s(x,x+)/τ) 其中 τ 是可学习的温度参数,Q 是队列,
s
(
x
,
x
+
)
=
x
T
x
+
∥
x
∥
⋅
∥
x
+
∥
s(x, x_{+})=\frac{x^{T} x_{+}}{\|x\| \cdot\left\|x_{+}\right\|}
s(x,x+)=∥x∥⋅∥x+∥xTx+ 。图像-文本结构损失 (ITC) [11, 16] 表述为:
L
I
T
C
=
[
L
N
C
E
(
v
c
l
s
′
,
t
^
c
l
s
′
,
Q
^
t
)
+
L
N
C
E
(
t
c
l
s
′
,
v
^
c
l
s
′
,
Q
^
v
)
]
/
2
\mathcal{L}_{ITC }=\left[\mathcal{L}_{N C E}\left(v_{c l s}', \hat{t}_{c l s}', \hat{Q}_{t}\right)+\mathcal{L}_{N C E}\left(t_{c l s}', \hat{v}_{c l s}', \hat{Q}_{v}\right)\right] / 2
LITC=[LNCE(vcls′,t^cls′,Q^t)+LNCE(tcls′,v^cls′,Q^v)]/2 除了
L
I
T
C
L_{ITC }
LITC 之外,在 RaSa 中还添加了模态内结构损失 (IMC),其重点是保持同一人相对于其他人的图像和文本嵌入。
L
I
M
C
=
[
L
N
C
E
(
v
c
l
s
′
,
v
^
c
l
s
′
,
Q
^
v
)
+
L
N
C
E
(
t
c
l
s
′
,
t
^
c
l
s
′
,
Q
^
t
)
]
/
2
\mathcal{L}_{I M C}=\left[\mathcal{L}_{N C E}\left(v_{c l s}', \hat{v}_{c l s}', \hat{Q}_{v}\right)+\mathcal{L}_{N C E}\left(t_{c l s}', \hat{t}_{c l s}', \hat{Q}_{t}\right)\right] / 2
LIMC=[LNCE(vcls′,v^cls′,Q^v)+LNCE(tcls′,t^cls′,Q^t)]/2 最终损失变为:
L
C
L
=
(
L
I
M
C
+
L
I
T
C
)
/
2
(
11
)
\mathcal{L}_{C L}=\left(\mathcal{L}_{I M C}+\mathcal{L}_{I T C}\right) / 2 (11)
LCL=(LIMC+LITC)/2(11)
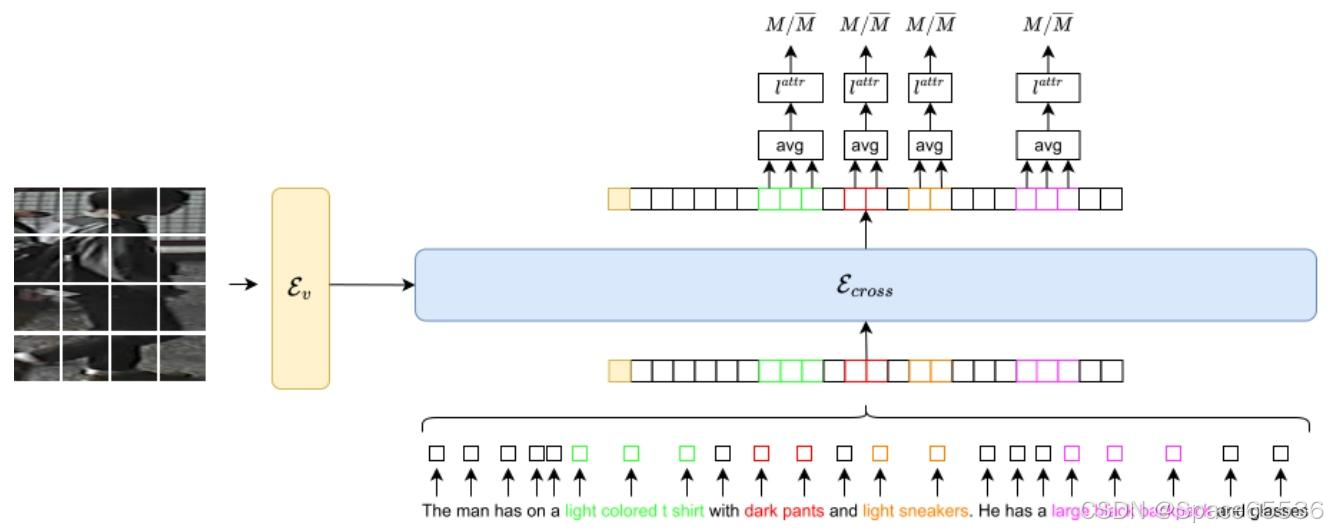
图 3.属性损失概述。使用 SpaCy 可以识别包含名词和相关形容词的句子块。然后,在处理每个令牌后 E c r o s s E_{cross } Ecross ,计算每个块嵌入的平均值。然后,对于它们中的每一个,模型会预测 image-chunk 对是否匹配。在图中,具有相同颜色的单词块(即绿色、红色、橙色和紫色)表示提取的块及其相应的嵌入(每个框代表一个嵌入)。
3.3. 属性损失
我们的属性损失旨在增强模型区分匹配和不匹配的文本-图像对的能力。特别是,我们将标题中的属性定义为由名词及其相应的形容词(例如“white long shirt”)组成的单词块。为了提取这些块,使用了 SpaCy [8]。这种损失背后的想法是,在由多个属性组成的标题中,模型无法为每个属性赋予正确的重要性,并且可能会忽略最具歧视性的属性。限制这种影响至关重要,因为通常,由于文本描述的模糊性,具有不同身份的两个人可能被非常相似的文本描述,只是在单个属性上有所不同。在这种情况下,如果忽略了大多数独特的属性,则文本描述和正确人员之间的正确匹配可能会失败,从而阻碍模型的准确性。因此,提议的属性 loss 的目标是限制这些情况,最终使整个系统更加健壮。
为此,给定跨模态编码器
E
c
r
o
s
s
E_{cross }
Ecross 的输出,该编码器将文本 T 和图像嵌入
v
=
E
v
(
I
)
v=E_{v}(I)
v=Ev(I) 作为输入,对于每个属性,即给定文本 T 中名词形容词的块
c
h
)
ch)
ch) ,相应嵌入的平均值计算如下:
c
h
^
(
T
,
v
,
c
h
)
=
1
N
w
c
h
∑
w
∈
c
h
E
c
r
o
s
s
(
T
,
v
)
[
w
i
]
\hat{c h}(T, v, c h)=\frac{1}{N_{w}^{c h}} \sum_{w \in c h} \mathcal{E}_{cross }(T, v)\left[w^{i}\right]
ch^(T,v,ch)=Nwch1∑w∈chEcross(T,v)[wi],
其中
N
w
c
h
N_{w}^{c h}
Nwch 是给定块中的字数
c
h
.
ch.
ch. 和
w
i
w^{i}
wi 是单词 w 在
E
c
r
o
s
s
E_{cross }
Ecross 输出中的位置.
有了这些信息,现在可以计算每个块的建议属性损失 L A L L_{AL} LAL。更详细地说, L A L L_{AL} LAL 的任务是在标题中的每个属性块与真实图像之间执行匹配。设 N B N_{B} NB 为批量大小, N c h N_{c h} Nch 为与图像 I 关联的文本 T 中的块数, l c a t t r ( c h ^ ( t , i , c h ) ) l_{c}^{a t t r}(\hat{c h}(t, i, c h)) lcattr(ch^(t,i,ch)) 是与方程 2 相同的全连接层,用于预测图像-文本对 ( I , T ) (I, T) (I,T) 是否匹配。损失函数变为:
L A L = 1 3 ⋅ N B ∑ ( I , T ) ∈ P 1 N c h ∑ c h ∈ t ∑ c ∈ C y c l o g e x p ( l c a t t r ( c h ^ ( T , E v ( I ) , c h ) ) ) ∑ n ∈ C e x p ( l n a t t r ( c h ^ ( T , E v ( I ) , c h ) ) \mathcal{L}_{AL}=\frac{1}{3 \cdot N_{B}} \sum_{(I, T) \in P} \frac{1}{N_{c h}} \sum_{c h \in t} \sum_{c \in C} y_{c} log \frac{exp \left(l_{c}^{attr }\left(\hat{c h}\left(T, \mathcal{E}_{v}(I), c h\right)\right)\right)}{\sum_{n \in C} exp \left(l_{n}^{attr }\left(\hat{c h}\left(T, \mathcal{E}_{v}(I), c h\right)\right)\right.} LAL=3⋅NB1∑(I,T)∈PNch1∑ch∈t∑c∈Cyclog∑n∈Cexp(lnattr(ch^(T,Ev(I),ch))exp(lcattr(ch^(T,Ev(I),ch)))
Here. c c c, y e y_e ye and P P P are built as in Eq. 2.
此外,我们探索了损失函数的加权变体。该实验的结果在本文后面的表 2 中介绍。具体来说,我们选择了 CUHK-PEDES 语料库中排名前 25 位的最常见的名词和形容词(图 4),并计算了在 0 和 1 之间标准化的频率值。如果该单词不在前 25 个最常用的单词中,我们将
α
w
\alpha_{w}
αw 设置为 0。然后,我们将块
c
h
.
ch.
ch. 的重要性权重
ω
c
h
\omega_{c h}
ωch 定义如下:
ω
c
h
=
1
−
∑
w
∈
c
h
α
w
N
w
c
h
(
14
)
\omega_{c h}=1-\frac{\sum_{w \in c h} \alpha_{w}}{N_{w}^{c h}} (14)
ωch=1−Nwch∑w∈chαw(14),其中
N
w
c
h
N_{w}^{c h}
Nwch 是块中包含的单词总数。最后,最终的加权属性损失公式化为:
L
w
e
i
g
h
t
e
d
−
A
L
=
1
3
⋅
N
B
∑
(
I
,
T
)
∈
P
1
N
c
h
∑
c
h
∈
t
∑
c
∈
C
ω
c
h
⋅
y
c
l
o
g
e
x
p
(
l
c
a
t
t
r
(
c
h
(
T
,
E
v
(
I
)
,
c
h
)
)
)
∑
n
∈
C
e
x
p
(
l
n
a
t
t
r
(
c
h
^
(
T
,
E
v
(
I
)
,
c
h
)
)
)
(
15
)
\mathcal{L}_{weighted-AL }=\frac{1}{3 \cdot N_{B}} \sum_{(I, T) \in P} \frac{1}{N_{c h}} \sum_{c h \in t} \sum_{c \in C} \omega_{c h} \cdot y_{c} log \frac{exp \left(l_{c}^{attr }\left(c h\left(T, \mathcal{E}_{v}(I), c h\right)\right)\right)}{\sum_{n \in C} exp \left(l_{n}^{attr }\left(\hat{c h}\left(T, \mathcal{E}_{v}(I), c h\right)\right)\right)} (15)
Lweighted−AL=3⋅NB1∑(I,T)∈PNch1∑ch∈t∑c∈Cωch⋅yclog∑n∈Cexp(lnattr(ch^(T,Ev(I),ch)))exp(lcattr(ch(T,Ev(I),ch)))(15)
如等式 14 所述,较低重要性的权重 (
(
ω
c
h
→
0
)
(\omega_{c h} \to 0)
(ωch→0) ) 被分配给具有非常常见词的块,而较高重要性权重
(
ω
c
h
→
1
)
(\omega_{c h} \to 1)
(ωch→1) 被分配给具有不常见词的块。此方法用于降低与多个不同图像匹配的非常常见属性的贡献,从而降低身份。
总之,属性损失用于关注单个句子的细微细节,使用文本中包含的描述图像的细粒度细节来提高匹配性能(例如,“粉红色耳机”可能是一个非常不常见的属性,如果考虑得当,可以提高模型的准确性)。因此,属性损失有助于模型使用整个给定的文本而不会丢失细节。换句话说,通过均匀分配注意力,它鼓励对输入数据进行更全面的理解。
3.4. Masked AutoEncoder Loss
受掩码语言模型的启发,我们开发了一种基于 Masked AutoEncoder [7] (MAE) 的新型损失函数。MAE 最初用作 transformer 的自我监督训练技术。目标是将一系列被遮罩的图像图块重建回原始的未遮罩图像图块。在我们的例子中,我们定制了这种技术,还集成了文本嵌入。更详细地说,我们通过交叉注意力层将文本嵌入注入 MAE 解码器中。目的是使用文本信息来帮助解码器重建图像补丁,从而将单词和视觉信息紧密地联系在一起。
给定一个图像-文本对
(
I
,
T
)
(I, T)
(I,T) ,我们从图像 I 中随机采样补丁,概率为
P
m
a
e
P_{mae }
Pmae 并丢弃剩余的补丁。选中的补丁通过图像编码器
ε
v
\varepsilon_{v}
εv 进行处理,得到其对应的嵌入
v
c
l
s
,
v
1
,
.
.
.
,
v
L
{v_{c l s}, v_{1}, ..., v_{L}}
vcls,v1,...,vL ,
L
<
M
L<M
L<M 。在将这些嵌入馈送到 MAE 解码器
D
m
a
e
Dmae
Dmae 之前,已删除的
K
=
M
−
L
K=M-L
K=M−L 补丁的嵌入被替换为可学习的掩码嵌入,从而获得一组
v
m
a
s
k
e
d
=
v
c
l
s
′
,
v
1
′
,
.
.
.
,
v
M
′
v_{masked }={v_{cls }', v_{1}', ..., v_{M}'}
vmasked=vcls′,v1′,...,vM′
的维度 M 。然后将集合
v
m
a
s
k
e
d
v_{masked }
vmasked 送入 MAE 解码器
D
m
a
e
D_{mae }
Dmae,与文本 T 对应的文本嵌入
t
c
l
s
,
t
1
,
.
.
.
,
t
N
=
E
t
(
T
)
{t_{c l s}, t_{1}, ..., t_{N}}=E_{t}(T)
tcls,t1,...,tN=Et(T) 融合,使用交叉注意机制重建原始图像。MAE 损失是重建损失,使用已删除补丁的均方误差 (MSE) 计算:
L
M
A
E
=
1
N
B
∑
i
=
0
N
B
1
K
∑
j
=
0
M
m
i
j
∥
x
j
i
−
x
^
j
i
∥
2
2
\mathcal{L}_{MAE}=\frac{1}{N_{B}} \sum_{i=0}^{N_{B}} \frac{1}{K} \sum_{j=0}^{M} m_{i}^{j}\left\| x_{j}^{i}-\hat{x}_{j}^{i}\right\| _{2}^{2}
LMAE=NB1∑i=0NBK1∑j=0Mmij
xji−x^ji
22,其中
m
i
j
m_{i}^{j}
mij 是一个指示变量,如果补丁最初被删除,因此需要重建,则等于 1,否则等于 0。设
x
j
i
x_{j}^{i}
xji 为原始图像块,
x
^
j
i
\hat{x}_{j}^{i}
x^ji 为重建的那个,则
x
^
j
i
=
D
m
a
e
(
v
m
a
s
k
e
d
,
E
t
(
T
)
)
\hat{x}_{j}^{i}=D_{mae }(v_{masked }, E_{t}(T))
x^ji=Dmae(vmasked,Et(T))
在我们的例子中,提出的 MAE 与模型的所有其他组件一起进行了端到端训练,弥合了文本和图像信息之间的差距。
3.5 Full Objective and Reranking
最后,完整的模型损失为:
L
=
L
p
−
I
T
M
+
λ
1
L
p
r
d
⏟
L
R
A
+
L
M
L
M
+
λ
2
L
m
−
R
T
D
⏟
L
S
A
+
λ
3
L
C
L
+
λ
4
L
M
A
E
+
λ
5
L
A
L
\mathcal{L}=\underbrace{\mathcal{L}_{p-I T M}+\lambda_{1} \mathcal{L}_{p r d}}_{\mathcal{L}_{R A}}+\underbrace{\mathcal{L}_{M L M}+\lambda_{2} \mathcal{L}_{m-R T D}}_{\mathcal{L}_{S A}}+\lambda_{3} \mathcal{L}_{C L}+\lambda_{4} \mathcal{L}_{M A E}+\lambda_{5} \mathcal{L}_{A L}
L=LRA
Lp−ITM+λ1Lprd+LSA
LMLM+λ2Lm−RTD+λ3LCL+λ4LMAE+λ5LAL,其中每个
λ
∗
\lambda_{*}
λ∗ 是分配给特定损失的权重。
在推理过程中,参考ALBEF[11]和RaSa[1],考虑到二次交互操作的高效率,我们采用采样策略,我们选择k个图像-文本对的子集,并将ITM秩应用于这个缩减集。具体来说,给定文本输入T,我们通过计算相似度分数 s ( t c l s , v c l s ) s(t_{c l s},v_{c l s}) s(tcls,vcls)并选择得分最高的图像来识别top-k, k = 128 k=128 k=128。第5.1节分析了更改此参数如何影响效率和准确性。
改变K值的影响。增大K值对除执行时间外的其他指标(如R@1、R@5、R@10和mAP)是有益的 。但当K值增大到128之后,继续增大K值带来的积极效果(如对R@1等指标的提升)几乎可以忽略不计,以K=256为例,相比K=128,它所需的执行时间几乎翻倍,但仅R@1的精度增益只有0.016,从效率和精度的综合权衡角度考虑,最终选择k=128,并非是改变K值没有影响。
4. 实验
4.1. 实验设置
我们在单个 NVIDIA 4090 GPU 上训练模型,总共 30 个时期,使用批量大小 8 。我们采用权重衰减为 0.02 的 AdamW 优化器 [14]。对于 PRD 和 m -RTD 参数,学习率的初始值为 1e4,对于其他参数,学习率的初始值为 1e5。图像大小调整为 384 × 384(数据集图像大小为 128 × 384),还可以进行水平随机翻转。我们将 BERT 中的最大字数设置为 70。动量系数 m 为设置为 0.995。温度 t设置为 0.07,CL 损失中使用的队列大小为 65536。关于蒙版比率,我们将其设置为 75%,因此在经过 ε v \varepsilon_{v} εv 之前会消除 75% 的图像块。我们对 MLMloss 采用标准 BERT [4],掩码概率为 15%,而对于 m − R T D m-R T D m−RTD 损失,使用 30% 的掩码概率。最后,在 RA 中输入弱对的概率设置为 0.1。我们将方程 17 中描述的损失的 λ s \lambda s λs 设置为: λ 1 = 0.5 \lambda_{1}=0.5 λ1=0.5 , λ 2 = 0.5 \lambda_{2}=0.5 λ2=0.5 , λ 3 = 0.5 \lambda_{3}=0.5 λ3=0.5 , λ 4 = 1 \lambda_{4}=1 λ4=1 , λ 5 = 2 \lambda_{5}=2 λ5=2
6. 结论
在本文中,我们提出了一种名为 MARS 的新型 TBPS 架构,它由文本编码器、图像编码器和跨模态编码器组成,就像以前的一些最先进的系统一样,但此外,它还配备了一个掩码自动编码器,与图像编码器共享编码器部分,并实现一个解码器,该解码器将掩码图像嵌入作为输入以及文本嵌入。
我们提议的 MARS 架构在基于文本的人物搜索方面带来了重大改进。我们开发了一种新颖的方法来解决身份间和身份内的变化,提供了一个强大的解决方案,能够超越当前的技术水平。
具体来说,多亏了掩码自动编码器,我们开发了一种新的视觉重建损失,它成功地鼓励模型学习来自文本和图像编码器的更具信息量的嵌入。其次,我们为整个跨模态编码器配备了额外的交叉注意力,用于重新排序阶段。最后,我们开发了一种新的属性损失,它使模型能够专注于给定句子的每个属性。值得注意的是,正如我们的消融所表明的那样,仅靠这种损失并不能将模型推向最佳状态,但是当与 MAE Loss 或新的交叉模型编码器结合使用时,属性损失使模型的性能优于最先进的技术。
总而言之,上述所有新颖性使 MARS 成为具有出色性能的模型,尤其是 mAP。这意味着,总体而言,我们的模型能够将匹配结果排在比以前的方法更早的位置,这在现实世界中至关重要。


















 2146
2146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









