




 本文分享了2019年发表在arXiv上的一篇关于利用姿态信息和注意力机制进行基于文本的人物检索的论文。作者提出了一种包含全局、单个局部和双重局部匹配的网络模型,以解决跨模态匹配中的关键问题,即如何提取与语言描述相关的视觉内容。
本文分享了2019年发表在arXiv上的一篇关于利用姿态信息和注意力机制进行基于文本的人物检索的论文。作者提出了一种包含全局、单个局部和双重局部匹配的网络模型,以解决跨模态匹配中的关键问题,即如何提取与语言描述相关的视觉内容。
Text-image retrieval 论文分享
论文链接
[1]Pose-Guided Joint Global and Attentive Local Matching Network for Text-Based Person Search
Task:这篇文章是放在2019arXiv上的,主要讲的是利用姿态信息和注意力机制来解决基于文本的人物检索的问题。
Motivation: 作者认为提取与语言描述相关的视觉内容是解决这个跨模态匹配的关键;相关图像和语言描述会涉及不同层次的语义相关性。
因此,为了利用人物描述和相对应的视觉内容多层次的相关性,作者提出GALM(Pose-guide global and attentive local matching network)。包括三部分:全局,单个局部,双重局部
Difficulties::
1、全局表征不能有效提取到图片中与人物相关的视觉内容。(利用pose information)
2、全局特征是一个粗糙的表征,只有局部的image region才与给定的文本描述有关(利用hard attention)
3、除了句子级别的关联,词组级别的关联对image-text matching 同样重要
(利用Pose-guide the aligned part matching)
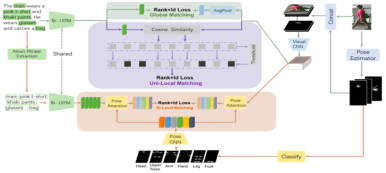
这篇文章的公式比较多,因为用到三个分支计算损失函数,但静下心来看的话还是能够看的懂得,没有特别难的地方。

















 1906
1906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









