




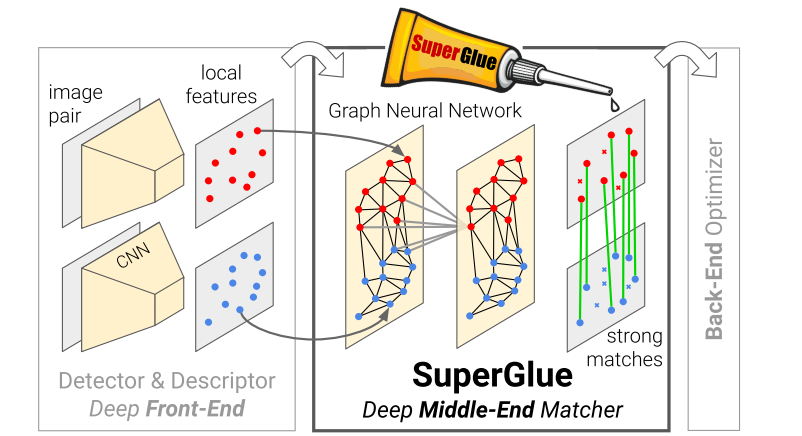
 SuperGlue是一种基于图神经网络的特征匹配算法,通过学习特征点的位置信息及相互关联来提升匹配性能。该文介绍SuperGlue的工作原理,包括图卷积神经网络、注意力机制及Sinkhorn算法的应用。
SuperGlue是一种基于图神经网络的特征匹配算法,通过学习特征点的位置信息及相互关联来提升匹配性能。该文介绍SuperGlue的工作原理,包括图卷积神经网络、注意力机制及Sinkhorn算法的应用。
SuperGlue: Learning Feature Matching with Graph Neural Networks 论文解析
简介
出发点
快速最临近邻搜索(FLANN)算法常常被用于匹配得到最近邻特征点,从而得到图片A和图片B中的特征点的匹配对。但是本文认为,特征点的提取与描述采用复杂的深度学习算法后不再是限制因素,而Naive的匹配方法才是限制其性能的关键点。因此本文在SuperPoint的基础上提出了一种匹配算法,取得了匹配性能的极大改进。
相关工作
-
经典的局部特征匹配流程
- 提取特征点
- 计算视觉描述子
- 最近邻搜索匹配
- 滤除不正确的匹配关系(Lowe’s radio test)
- 计算图片间的几何关系(RANSAC)
-
基于深度学习的匹配
- 改进特征点提取方法
- 改进描述符计算方法
- 依旧采用传统的最近邻搜索方法
-
图搜索
图匹配是一个NP-难的问题,其中和特征点匹配等价的问题为最优搬运问题。该问题可采用Sinkhorn算法进行求解。
- 集合深度学习
难点:特征点的数量和彼此之间的相关关系都是不确定的,难以用传统的卷积方法进行深度学习。
具体的也是参考了一些相关文献,找到了适用于本任务的学习方法
- TODO
- [3] [13] [21] [23] [25] [30] [37] [38] [54] [55] [56] [58] [60] [62] [64]
因此,本文的创新点在于:
- 采用深度学习方法,替换掉传统的最近邻搜索与不正确匹配关系剔除两个步骤
- 采用基于注意力机制的图卷积神经网络提取特征信息
- 采用可微分的分配算法,即Sinkhorn算法,得到匹配结果
方法
理解本文需要有如下的基础知识:
- 图卷积神经网络
- 注意力机制
- 最优搬运问题
图卷积神经网络
图卷积神经网络是目前很火的内容,为了理解本文,需要有如下的相关知识,即网络的计算方式。
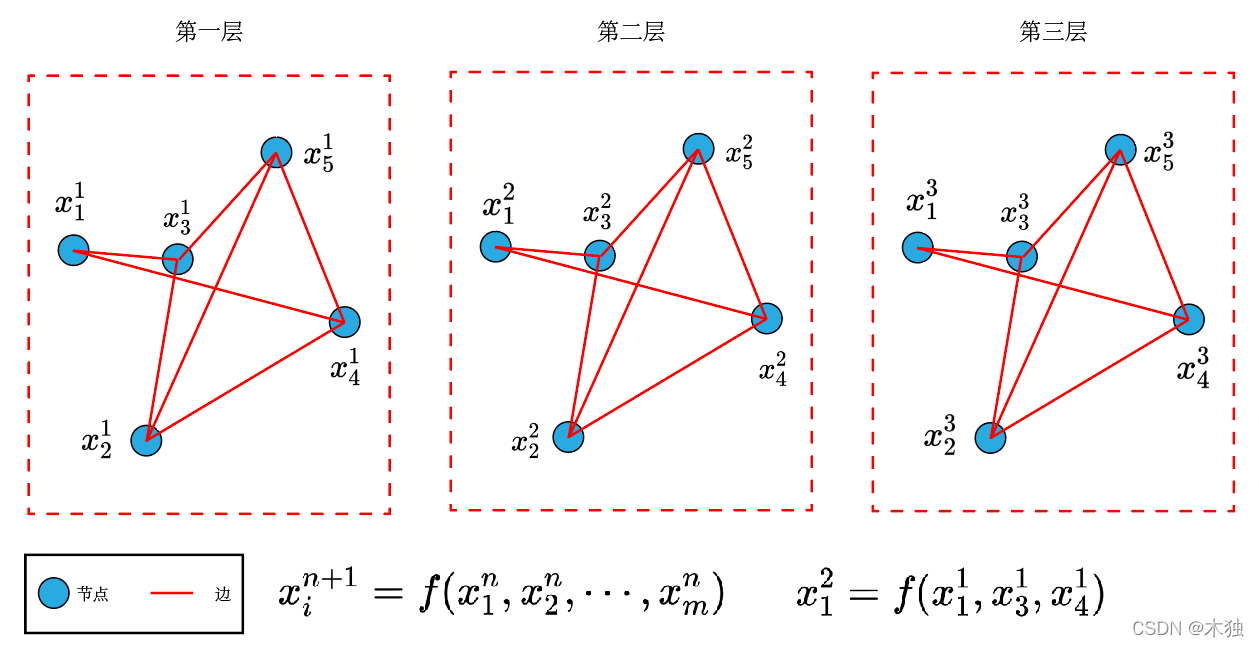
- 图网络分为很多层,和普通卷积网络类似
- 图网络每一层中有节点和边,节点和边的连接关系不规则
- 定义卷积操作,即下一层节点的值,为上一层节点连接的所有节点的函数。
x i n + 1 = f ( x 1 n , x 2 n , x 3 n , ⋯ , x m n ) , x 1 → m 为 所 有 与 i 节 点 关 联 的 节 点 x_i^{n+1} = f(x_1^n,x_2^n,x_3^n,\cdots,x_m^n),x_{1\to m}为所有与i节点关联的节点 xin+1=f(x1n,x2n,x3n,⋯,xmn),x1→m为所有与i节点关联的节点- 例如: x 1 2 x_1^2 x12为第二层第一个节点与 x 2 , x 3 x_2,x_3 x2,x3节点相连,因此计算为:
x 1 2 = f ( x 1 1 , x 3 1 , x 4 1 ) x_1^2 = f(x_1^1,x_3^1,x_4^1) x12=f(x11,x31,x41)
- 例如: x 1 2 x_1^2 x12为第二层第一个节点与 x 2 , x 3 x_2,x_3 x2,x3节点相连,因此计算为:
- 通过定义不同的卷积方法 f f f,得到不同类型的图卷积网络,文中借鉴注意力机制定义了卷积方法。
注意力机制
文中通过注意力机制构建了卷积计算方法,所谓的注意力机制即计算如下的权重,然后进行加权求和。
简化版本为:
A = α 1 x 1 + α 2 x 2 + ⋯ + α m x m A=\alpha_1 x_1 + \alpha_2 x_2 + \cdots + \alpha_m x_m A=α1x1+α2x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2415
2415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









