



 Mosaix首席科学家劳逆在Robin.ly AI技术专访中分享了他对机器学习、自然语言处理的研究,特别是弱监督学习的重要性。他认为无监督学习是解决强化学习问题的关键,弱监督学习将是机器学习未来的发展趋势。
Mosaix首席科学家劳逆在Robin.ly AI技术专访中分享了他对机器学习、自然语言处理的研究,特别是弱监督学习的重要性。他认为无监督学习是解决强化学习问题的关键,弱监督学习将是机器学习未来的发展趋势。
Robin.ly 是立足硅谷的视频内容平台,服务全球工程师和研究人员,通过与知名人工智能科学家、创业者、投资人和领导者的深度对话和现场交流活动,传播行业动态和商业技能,打造人才全方位竞争力。
本期Robin.ly AI技术专访特邀Mosaix的联合创始人、首席科学家劳逆博士分享他在机器学习、自然语言处理方向的研究经历,以及对弱监督学习技术未来发展的见解。
劳逆博士毕业于卡耐基梅隆大学语言技术研究所。曾在Google从事知识图谱和搜索问答系统研究。Mosaix2016年成立于硅谷,专注于开发可定制的、多语言人工智能语音助手应用服务。

劳逆在硅谷接受Robin.ly专访
以下为精彩内容节选
v

长按二维码或点击“阅读原文”
访问Robin.ly观看完整英文访谈视频
1
早期经历
Wenli: 可以回顾一下您的成长经历吗?您上学的时候是运动健将,还是更喜欢看书?
Ni Lao:
我比较喜欢看书。以前别人给我起过一个绰号叫“熊猫”,因为我那时候很胖,很少运动,跟现在不太一样。那会儿我更喜欢独处,在非常认真的完整老师布置的作业之余,还会一个人静静地观察大自然。
Wenli: 您后来获得了卡内基 · 梅隆大学语言技术学院的博士学位,师从William Cohen。当初为什么选择他作为导师,在他那里都学到了些什么呢?
Ni Lao:
我当时花了很多时间钻研出了一些新的算法,他对我的工作很感兴趣。我记得有一年的夏天,我正在考虑换导师,他刚好有一个项目,想让我试试。于是我就写了一个能够在知识谱图上进行推理的算法,可以用于推荐和搜索系统。他很满意,直接就让我加入他们的团队。
William是个很有意思的人,爱弹班卓琴,每天都乐呵呵的,也希望自己的学生能享受生活。他很聪明,跟你聊几句就能洞察你所面临的问题,并告诉你如何解决;如果他一时没有解决办法,至少也会给你指明继续探索的方向。

劳逆(右二)与导师William Cohen(左二);图片来源:noon99jaki.github.io
2
Google的工作经历
Wenli:在读博士期间,您的研究课题是自然语言处理和基于知识的系统。毕业后您加入了Google,他们推出了第一个基于知识的系统。您在Google工作这段期间都遇到过什么样的挑战呢?
Ni Lao:
那时候,基于知识的系统在工业界并不像现在这样流行,但这一概念很早以前就有了。几十年来,人们一直在研究这方面的技术。我认为是Google让这个系统进入了主流领域,引起了人们的关注。我当时碰巧参与了一个由Google资助的项目,毕业后很自然的就加入了Google。
我在工作中面临的挑战,主要是如何用机器学习和自然语言处理来研究一些核心课题,比如如何理解网络上的内容并利用这些信息构建知识谱图,这个问题今天仍然没有解决,进展非常缓慢。今天大家看到的大多数知识谱图都是人工或者半人工生成的,经常需要人工验证事实的准确性,甚至有时候还需要直接手动输入信息。
Wenli: 我之前在您的个人网站上看到您在Google主要负责自然语言处理和问答系统的相关项目,还做过一些志愿者工作。您能不能详细回顾一下这段经历?
Ni Lao:
我在Google工作了五年半,主要负责问答系统的开发。这些项目大致可以分为两类。第一类是关闭域问答(close domain question answering),可以利用知识谱图中的信息回答问题,但只能回答一些特定类型的问题,比如一个人的配偶和职业等信息,前提是你必须事先生成知识谱图来定义这种关系。另一类是开放域问答(open domain question ans-wering),需要在没有任何预先定义的关系的前提下回答人们在网上提出的任何问题,这比第一类任务更具挑战性。这两类任务难度都很大,但背后用到的是不同的技术。
工作之外我的确还做了一些志愿者工作,组织过几批中学生来Google园区参观,邀请了一些工程师和科学家为他们介绍在Google工作是一种什么样的体验。我最喜欢Google的那种开放的工程师文化,所有人的代码都是公开的,可供他人参考。这样的环境有助于增强人与人之间的沟通,也能鼓励员工相互协助。

Wenli:您在离开Google之后加入了Mosaix。当初还有其他初创公司联系您吗?为什么最后选择了Mosaix?
Ni Lao:
很多创业公司都联系过我,但最开始我并没有考虑过要离开Google,直到接到了Mosaix的邀请。我觉得只有Mosaix做的是我真正想要探索的东西,也就是如何更好的理解互联网上的信息,了解用户,并试图让机器更好地为用户服务。
3
机器学习算法的理解
Wenli: 咱们再谈谈技术。在机器学习中有监督学习,无监督学习,还有强化学习。您能简要谈谈您对这些机器学习算法的理解吗?
劳逆谈监督学习、无监督学习和强化学习
Ni Lao:
这三个概念有些复杂都是很重要的概念,跟每个人都息息相关。假设你想让一台机器学习玩超级马里奥的游戏,可以采用监督学习,一步一步的教机器怎么做。比如看到前面有一只乌龟,就应该跳过去;看到一枚硬币,应该继续前进。你需要明确诸如此类的指示,制定各种各样的规则,还需要用人工进行标记。少了这些步骤,你就无法实现这样的功能。
第二个是强化学习,也就是让机器自己去探索最佳策略。你只需要定义一个比较高的目标,比如通关或拿到更多金币,机器就会尝试不同的策略,看看哪个能满足你的要求,然后你再去不断改进这个策略。在强化学习领域,我们已经实现了飞跃,比如AlphaGo或Atari Games,机器可以探索人类从未探索过的空间,找到更好的策略。但是存在两个问题。首先,你需要找到机器可以探索的空间,这是个很重要的问题。对于Go来说情况比较简单,探索的空间只是棋盘。但对于其他情况,比如自动驾驶汽车或玩超级马里奥,你就必须定义更复杂的空间让机器进行学习。比如让机器玩游戏,就需要编写无数的规则来实现最终的目标。第二,人们并没有在强化学习中应用足够多的学习理论,因此程序优化的效率不高,需要很长时间才能收敛,也需要大量数据才能改善其性能。
第三个是无监督学习,我认为这是解决强化学习问题的关键。对于监督学习,需要逐步标记机器应该做什么;对于强化学习,只需要提供最终目标让机器去探索。而对于无监督学习,我们会让机器自己去探索这个世界,预测一系列动作的结果,这些都是没有被人为标记过的。例如图像分类,可以利用ImageNet数据集中成千上万猫的图像来训练机器识别出猫。但如果你想让孩子分辨出什么是猫,只需要一张图片就够了。孩子们早就见过猫了,也能区分猫和其他动物的区别,在家长们帮孩子给猫贴上“猫”的标签的时候,孩子的大部分学习过程在此之前就已经完成了。这就是为什么无监督学习在机器学习领域中如此重要。
说到这儿,我还想提一下Yann LeCun的蛋糕。比如说机器学习是一个蛋糕,其中大部分是无监督学习,目标是理解周围的世界;蛋糕上还有一些糖霜,这是监督学习,有人工标签和数据;最上面还有一个樱桃,这是强化学习,可以优化你的目标。
换个角度说,如果糖霜是监督学习,余下的蛋糕和樱桃都可以归为弱监督学习。这是一个繁琐的创新过程,也是机器学习未来的发展趋势。
想要弄清楚如何更好的表征事物,比如定义一个空间让模型去探索高质量的表征方式,必须要尝试不同的模型结构。我们需要从动物学,心理学或神经科学中获得灵感,还需要找到合适的应用场景和可观的回报来推动这些创新。
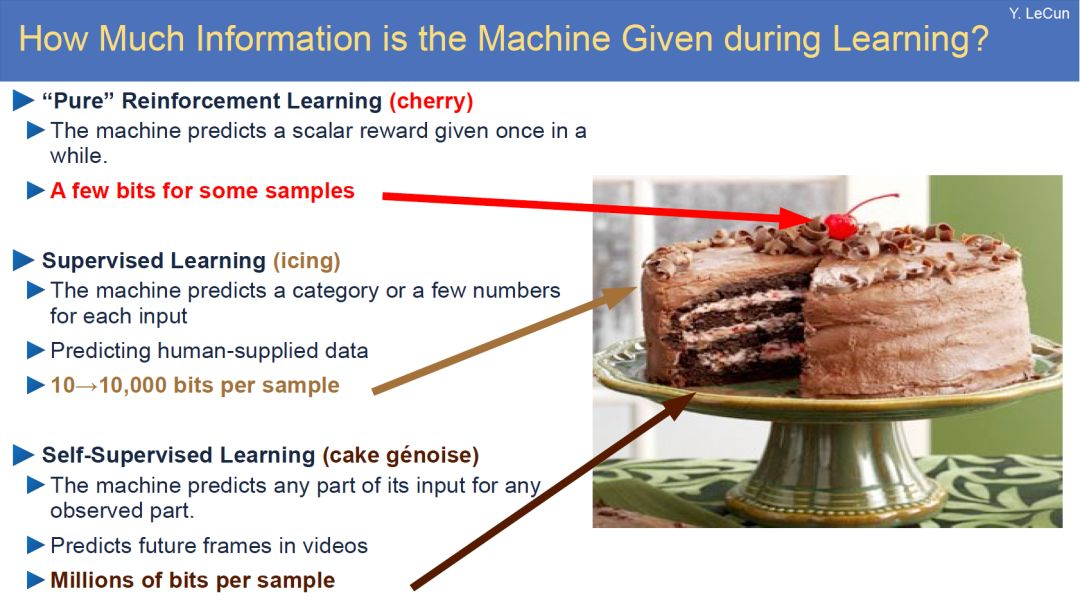
LeCun的蛋糕(来源:Yann LeCun ISSCC, San Francisco, 2019-02-18)
4
Mosaix 的特点和优势
Wenli:Mosaix的语音助手与Siri和Alexa等科技巨头打造的产品相比有什么区别?能举个例子吗?
Ni Lao:
我们先说业务部分。在我看来,语音助手就是互联网的门户。每个助手都会对互联网的一部分内容进行索引,例如Alexa会对Prime视频进行索引,而Google Assistant会对YouTube进行索引。但互联网上的很多其他内容并不在二者的索引范围内,我们的产品刚好可以填补这个空缺。
再说说技术部分。大公司拥有很多资源,可以雇佣许多人来编写规则,标记数据,把控质量,打造语音助手。而我们采取的是不同的方式。我们会在一个系统中部署大量的机器学习算法,摸索机器应该如何思考,类似手动进行注释。但是为了做到这一点,我们必须训练这些算法,尽量只使用系统的最终输出,反向传播到位于过程中间的所有学习模块,对其进行训练。举一个比较极端的例子,假如你只有用户,没有任何数据标签人员。如果为用户提供一些选项,你就能够根据用户的选择判断出用户的意图。但如果我们在最开始时没有用户该怎么办呢?我们还是会想办法做一些注释。针对一个问题,会有人去评估系统的最终输出应该是什么。它可以是对问题的解释,也可以是结果,然后系统可以从输出中学习。
让机器理解网络上的内容也是我们的目标之一。比如有人输入“我想听Taylor Swift的Love Story”。如果你知道Taylor Swift是一个歌手,她有一首歌名为“Love Story“,你就知道这个用户在说”Love Story“时想表达什么意思。这就是我们理解内容的方式。我们还在继续努力,希望对内容有更深入的了解,比如如何通过评论和描述了解电影,了解产品。

Mosaix团队 (图片来源:劳逆)
Wenli: 你们的语音助手是如何在初始阶段获得用户的?目前还需要克服哪些技术上的困难?下一步的目标是什么呢?
Ni Lao:
我认为提高性能和获取用户是一个先有鸡还是先有蛋的问题。例如每个人都说搜索引擎非常智能,这是因为很多人都在使用它,而它只需要记住人们在看到结果后选择的内容,从而进行后续的结果筛选。我们的系统也类似,人们用得越多,这个系统就会越智能。 在获得第一批用户之前,我们必须确保我们的系统很可靠,能够满足人们的需求。我们很幸运,拥有非常强大的业务拓展团队,下一个目标就是获得更多用户。我们正处于一场以吸引用户为目标的竞赛,类似早期的搜索引擎,每一家都希望能获得更多用户。(完)
点击“阅读原文” 访问Robin.ly观看完整英文访谈视频。

合作转载请加微信:robinly_assistant
相关阅读
Palantir早期员工、连续创业者Brien Colwell:创业动力源自创造文化

你“在看”吗?

















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









