







 本文探讨了声纹识别在文本提示型应用中的作用,分析了其功能需求,如声控开门和说话人识别,并介绍了科大讯飞的声纹识别产品,强调了在不同场景下的性能表现。同时,指出百度和腾讯目前尚未提供声纹识别服务。
本文探讨了声纹识别在文本提示型应用中的作用,分析了其功能需求,如声控开门和说话人识别,并介绍了科大讯飞的声纹识别产品,强调了在不同场景下的性能表现。同时,指出百度和腾讯目前尚未提供声纹识别服务。

有了声纹识别的模型,如何应用?现在主要考虑在前端增加一些音频质量的评估工具,对音频进行一个初步的过滤。
一些思路
文本提示型
来源:mialrr /Speaker-Recognition
声纹辨认包括两部分:① 文本匹配 ② 声纹匹配 (实际上也就是文本提示型的声纹识别)。
其中,借助语音识别模块作为文本匹配的辅助工具(语音转文字)。
(1)声纹识别模块
#! /usr/bin/env python3
# coding=utf-8
import requests
import time
# 1:1 检测两个声音是不是同一个人的声音
def Speaker_1_1():
# url = 'http://bbs.ziyoujie.com:8888'
# url = 'http://localhost:8888'
url = 'http://47.110.142.112:9999'
sound0path = "../sample-files/156_0.wav"
sound1path = "../sample-files/156_1.wav"
AppID = "2rtg2z53r"
APIKey = "378d4582ad3ed253057cafe9c70fae8b"
SecretKey = "d6uk5fd"
starttime = time.time()
data = {'AppID': AppID, 'APIKey': APIKey, 'SecretKey': SecretKey}
files = {'Sound0': open(sound0path, 'rb'), 'Sound1': open(sound1path, 'rb')}
r = requests.post(url, files=files, data=data)
print(r.url)
print(r.json())
print(time.time()-starttime, "秒")
# 认证分为两部分(1:检测是否说了指定的文字的语音 2:检测是不是同一个人的声纹)
def ASR_Speaker_1_1():
# url = 'http://bbs.ziyoujie.com:8888'
# url = 'http://localhost:8888'
url = 'http://47.110.142.112:9999'
sound0path = "../sample-files/76256_39.wav"
sound1path = "../sample-files/156_1.wav"
AppID = "2rf9j453r"
APIKey = "378d4582ad3ed253057cafe9c70fae8b"
SecretKey = "d6uk5fd"
starttime = time.time()
# SpkTxt 对应的是 Sound0
# 如果是英文语音需要选择 en, 该选项是针对语音识别, 声纹没有Language限制
data = {'AppID': AppID, 'APIKey': APIKey, 'SecretKey': SecretKey,
'Language': 'cn',
'SpkTxt': '他完全将自己当成了一个凡人在体会这人世间的生老病死悲欢离合'}
files = {'Sound0': open(sound0path, 'rb'), 'Sound1': open(sound1path, 'rb')}
r = requests.post(url, files=files, data=data)
print(r.url)
print(r.json())
print(time.time() - starttime, "秒")
if __name__ == "__main__":
Speaker_1_1()
ASR_Speaker_1_1()
(2) 语音识别模块(语音转文字)
#! /usr/bin/env python3
# coding=utf-8
import requests
import time
# 语音识别 (语音转文字)
def ASRTxt():
url = 'http://bbs.ziyoujie.com:8888'
#url = 'http://localhost:8888'
#url = 'http://47.110.142.112:9999'
soundPath = "/home/louj/disk/m2_2T/VoxCeleb1/data/vox1/test/wav/id90148/EEEEEEEE48/76256_39.wav"
AppID = "暂时先不提供"
APIKey = "378d4582ad3ed253057cafe9c70fae8b"
SecretKey = "d6uk5fd"
starttime = time.time()
# 'Language': 'en'
data = {'AppID': AppID, 'APIKey': APIKey, 'SecretKey': SecretKey,
'Language': 'cn',
'SpkTxt': '他完全将自己当成了一个凡人在体会这人世间的生老病死悲欢离合'}
files = {'Sound': open(soundPath, 'rb')}
r = requests.post(url, files=files, data=data)
print(r.url)
print(str(r.json()))
print(time.time()-starttime, "秒")
if __name__ == "__main__":
# 暂时先不提供
ASRTxt()
功能需求分析
使用声纹识别实现声控开门的核心价值:
- 方便、快捷,无须用手
- 可实现文本交互(留言等)
功能列表:

- 在会议室等场所,需要完成说话人辨认(重要);
- 在总裁室等场所,需要完成说话人验证(重要);
- 其他人需要留言,需要语音识别(次要);
关于阈值

参考:一种基于声纹和语音的防录音假冒身份识别方法及系统.pdf
没想到其系统,与本项目不谋而合:
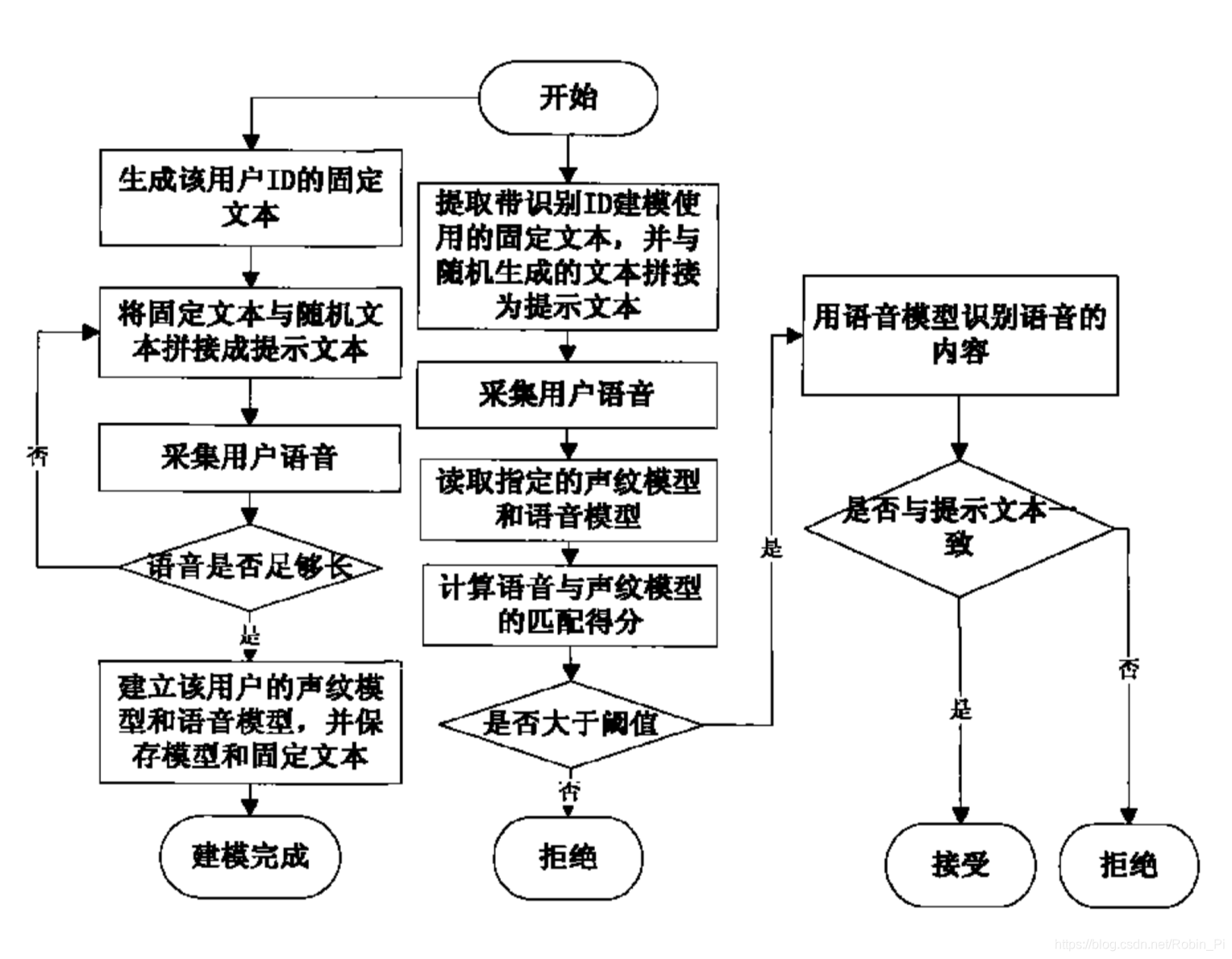
产品应用
讯飞
(1)产品介绍(当前官网)
-
可以将说话人声纹信息与库中的已知用户声纹进行1:1比对验证和1:N的检索,并且还需要将说话人所读出的数字声音与云端动态给定的数字内容进行验证。最终,仅当声纹+内容都匹配即验证/检索成功
-
语言支持:中文的数字
声音要求:注册和测试将采用不同的8位不重复随机数,并且注册需5遍动态数字;验证需1遍动态数字。
响应时间:注册—500ms,验证—900ms
(2)InterVeri 2.1声纹识别系统
注:本性能指标仅仅为API的调用时间,不包含数据库访问时间
- 声纹注册:
20s有效语音,单路平均0.68秒完成注册;25路并发条件下,每路平均时间<2s,最大时间<3s - 声纹确认:
8s有效语音,单路平均 0.35秒完成确认;70路并发条件下,每路平均时间<2s,最大时间 - 声纹鉴别:
200人规模,8s有效语音,单路1.1秒完成识别;20路并发条件下,每路平均时间<2s ;如识别规模在200人以上,则人数与识别性能成线性增长关系。
百度(暂无声纹识别)
腾讯(暂无声纹识别)
微软
参考:

















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









