




 本次分享聚焦于竞赛题目解读,涵盖数据下载、导入及初步分析。通过EDA和数据可视化,深入理解数据特征,为构建有效模型奠定基础。作业要求撰写背景资料报告,探索数据集组合方式。
本次分享聚焦于竞赛题目解读,涵盖数据下载、导入及初步分析。通过EDA和数据可视化,深入理解数据特征,为构建有效模型奠定基础。作业要求撰写背景资料报告,探索数据集组合方式。
任务
学习时长:1/13——1/14
任务名称:赛题解读以及数据下载导入、赛题的理解分析
任务简介:赛题的初步理解分析
详细说明:
本节将会赛题的背景资料的了解以及数据文件的分布以及数据的下载以及本地导入,赛题的理解分析通过对构建自己对构建特征来说有一个比较大的作用,针对于数据的解读来说比较重要的一环。
数据的解读包括数据的EDA、数据的可视化,数据的类型、数据的文件分布、数据的特征组合的一些猜测都在这里面会涉及到。
代码数据下载:
链接:https://pan.baidu.com/s/1PS_iY_vyTWFM5L04UTL2fA
提取码:lryb
作业名称(详解):针对于这个数据集的一些想法,如何把这么多个数据及放到一起,组合成新的数据集,网上搜集这个比赛的背景资料,写成一个报告(报告的截图也行)。
作业提交形式:
打卡内容:PPT截图或手写拍照,打卡提交.(可以只是文字提交,或图片提交,或组合都行)
打卡截止时间:1/14
打卡
1. 赛题
1.1 背景介绍

1.2 目标描述

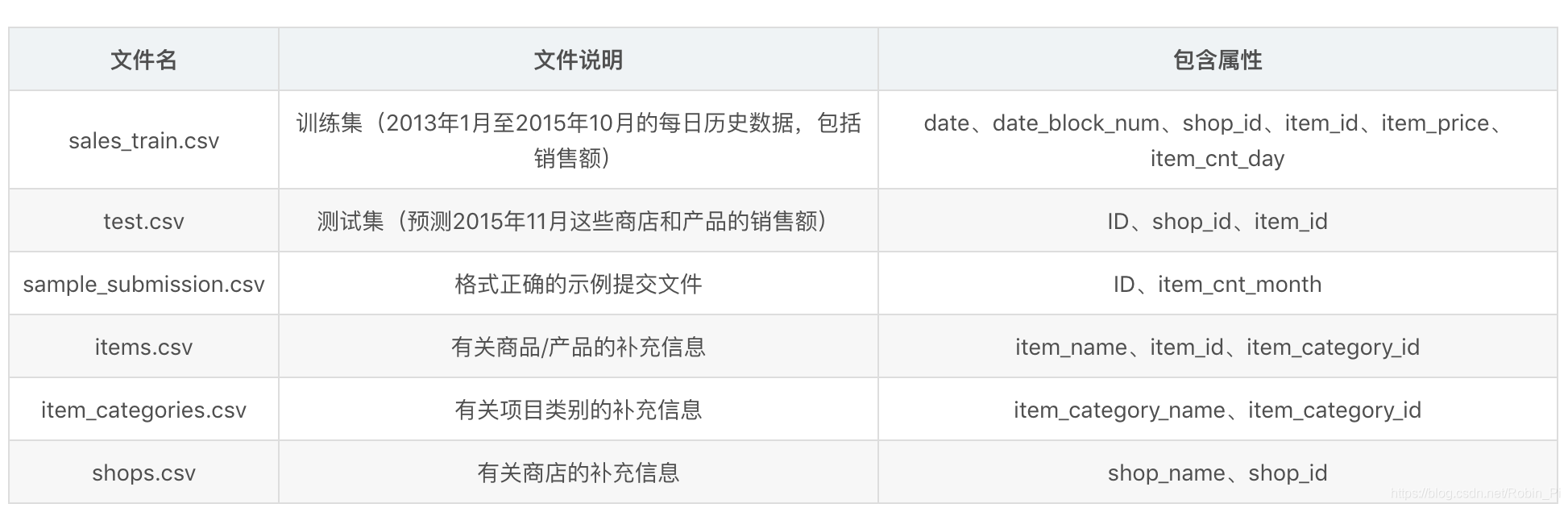
1.3 文件说明

2. 数据初步探索
import numpy as np
import pandas as pd
数据导入
data = pd.read_csv('sales_train.csv')
# data = pd.read_csv('test.csv')
# data = pd.read_csv('items.csv')
# data = pd.read_csv('item_categories.csv')
# data = pd.read_csv('shops.csv')
逐个查看
data.head()
sales_train.csv:
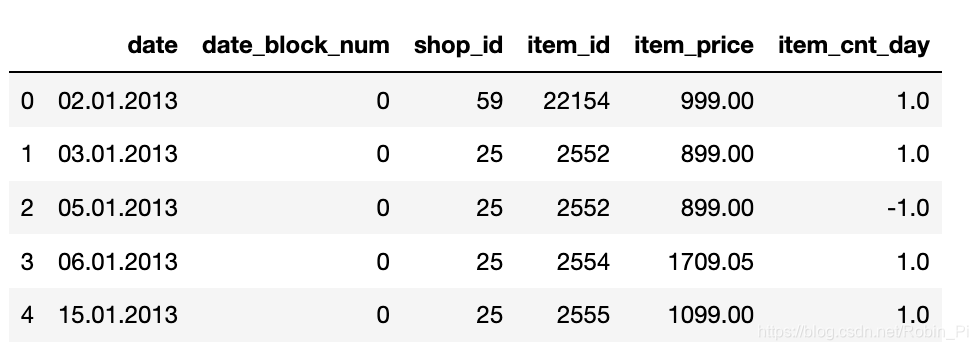
date_block_num 表示对月份的编码,比如一月用0表示;
item_cnt_day 表示销售数量,而我们要预测的对象就是一个月的它。
test.csv:

items.csv:

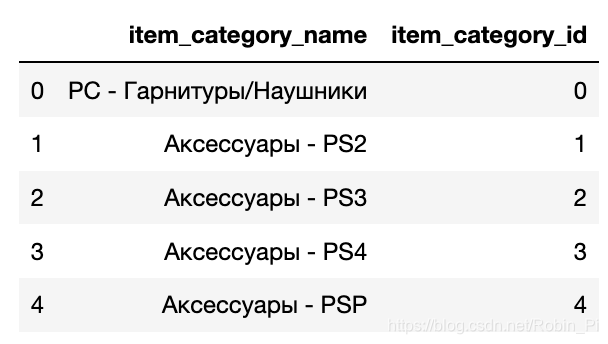
item_categories.csv:
shops.csv:

查看所有的数据后,对数据有了深一层的理解:
特征变量分为两大块:
- name类:时间、商店、商品三个变量的具体名称
- ID类:上面变量的编码
最终预测的变量: 按月来预测item_cnt_day
下一步要做的是就是将数据整合起来。
时间序列的读取可以采用 pandas 中的分组和聚合函数:先分导入各CSV 文件,再使用 groupby() 进行分组,agg()进行聚合。

















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









