




👻 一个奇怪的现象
python中所有的数据都是对象, 对象分为两大类: 不可变对象(Immutable Object)和可变对象(Mutable Object)
搞清楚这个概念, 能解释清代码中很多奇怪的现象。
比如下面的代码:
# 传入一个数字, 数字+1
def add_func(num: int):
num += 1
# 传入一个列表, 添加元素5
def append_func(nums: list):
nums.append(5)
if __name__ == '__main__':
x = 10 # 定义一个整数
y = [1, 2, 3, 4] # 定义一个列表
add_func(x)
print(x) # 10
append_func(y)
print(y) # [1,2,3,4,5]
可以看到, 在主函数中定义了一个整数x和一个列表y, 分别定义了两个函数add_func和append_func分别对这两个对象进行操作。奇怪的是, 当操作完成之后, 打印x和y的值, 会发现整数x的值仍然是10, 而列表y的值已经被添加了新元素5。
👀 区分可变与不可变
什么叫做 “可变” 与 "不可变"呢?
在上一篇 ⌈内存数据存储机制 -存储管理系统⌋ 一章中, 我们了解到如何判断是否是同一个对象, 是通过地址。
既然y的值已经改变了, 那么是不是已经和原来的y不是一个对象了呢?
那么在上面的代码中, 我们使用id()来检查一下。
if __name__ == '__main__':
x = 10 # 定义一个整数
y = [1, 2, 3, 4] # 定义一个列表
print("x的原始存储地址: ", hex(id(x))) # 0x7ffad3ff4ad8
print("y的原始存储地址: ", hex(id(y))) # 0x2ab3f19d0c0
add_func(x)
print(x) # 10
append_func(y)
print(y) # [1,2,3,4,5]
print("x修改后的存储地址: ", hex(id(x))) # 0x7ffad3ff4ad8
print("y修改后的存储地址: ", hex(id(y))) # 0x2ab3f19d0c0
通过结果我们可以看到, x和y的内存地址仍然是原来的地址, 并没有发生任何的改变, 即x和y仍然是原来的对象。
但与此同时, y存储的列表数据却改变了, 这就叫做可变对象。而x的值并没有改变, 就叫做不可变对象。
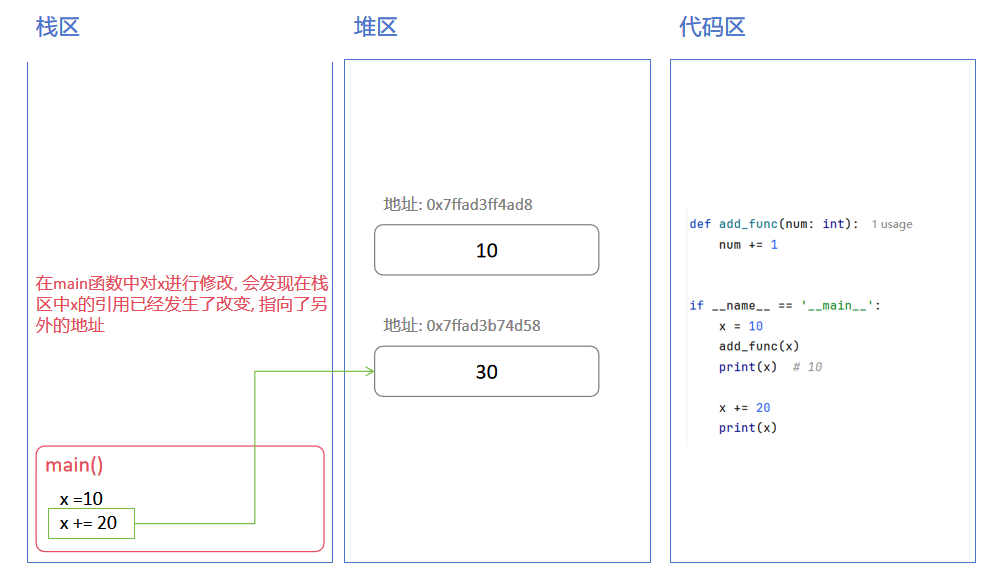
🌟 堆区角度理解可变与不可变
在上一章 ⌈内存数据存储机制 - 栈与堆的存储 - 栈是什么⌋ 这一章节中, 我们可以了解到栈中存储的是对象的引用(指针), 真正的数据存储在堆中。因此对数据的操作, 实际上是发生在堆区的。
不可变与可变的区别就在于: 对象在堆中的"内容区域"是否允许被修改
🔥 可变对象(mutable)
包含有: list、dict、set、bytearray
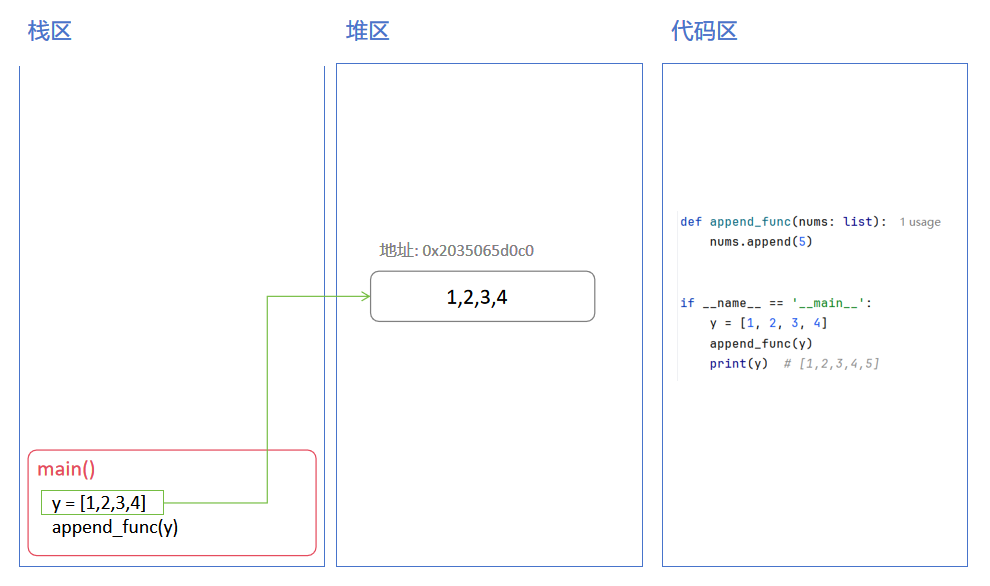
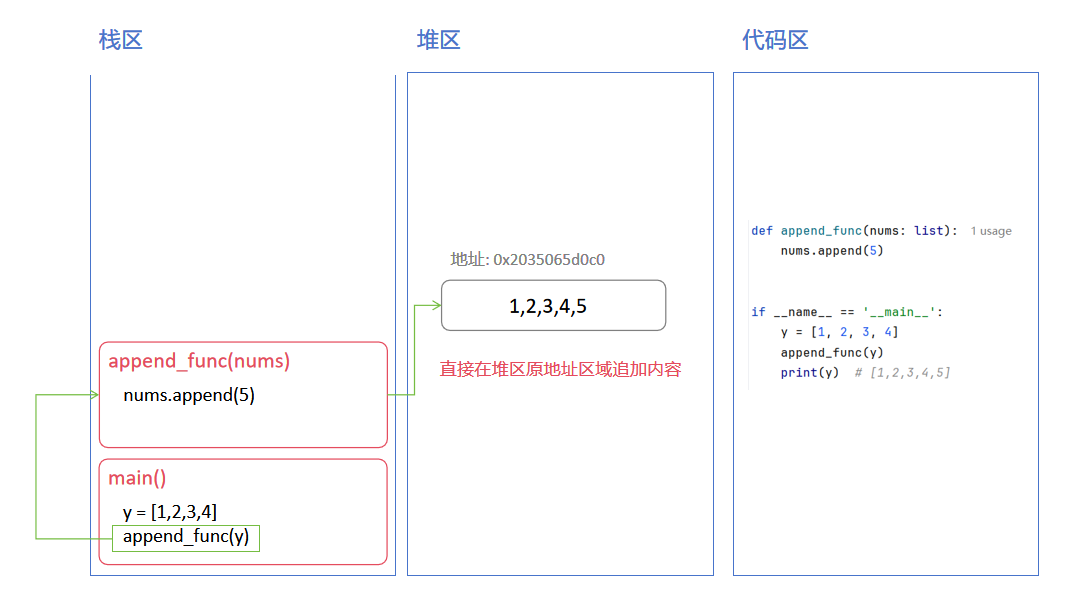
修改时堆区内的操作:
堆区对象内部结构可以改变, 修改时不需要创建新对象, 只是在堆中修改内容
下面是可变对象堆区中数据的变化流程:
🔥 不可变对象(mutable)
包含有: int、float、str、tuple、frozenset、bytes
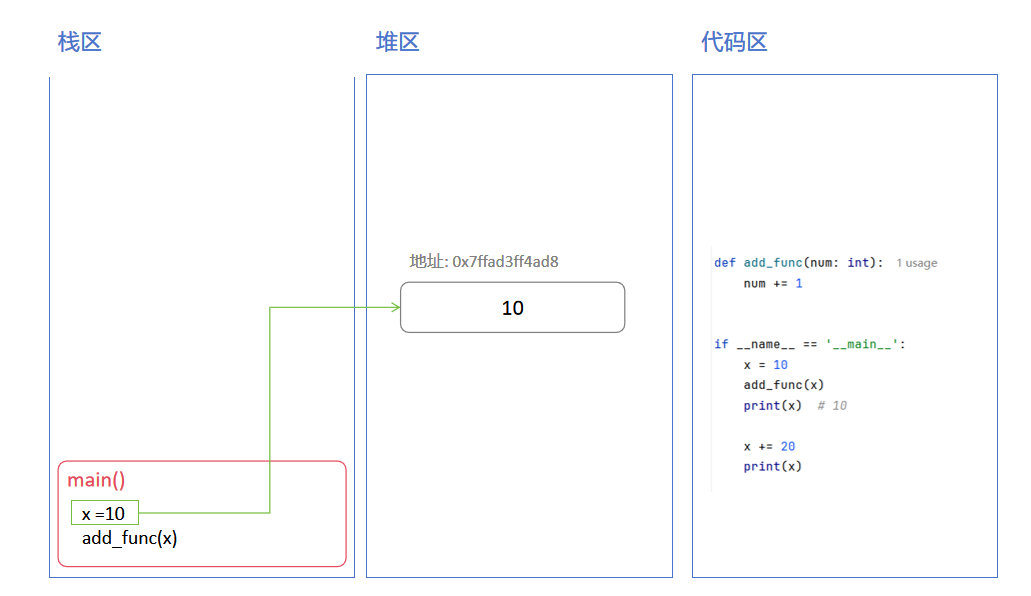
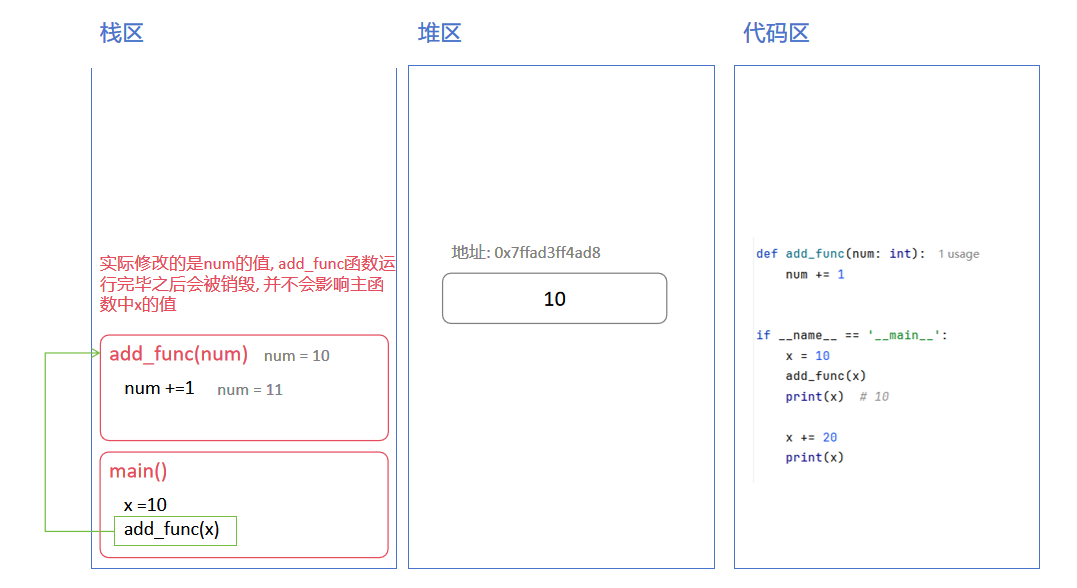
修改时堆区内的操作:
看似是修改, 实际上是在堆区中新建一个对象, 堆区变量指向了新的堆对象
下面是不可变对象堆区中数据的变化流程:
🧲 python参数传递机制总结
根据上面的内容,我们可以了解到python使用的是"对象引用传递"
-
不可变对象: 函数内"修改"的实际上是创建的新对象
-
可变对象: 函数内的修改会影响原始对象
🚨 Attention
重新赋值(=)会创建新绑定, 而原地修改(append, extend…)会影响原对象
🕳️ 默认参数的陷阱
在上面的章节中, 我们了解到, 由于列表是可变对象, 因此如果定义的列表对象传递进函数中, 会改变原始对象的值。
因此, 如果函数中使用可变对象定义了默认参数, 在函数首次调用时会修改默认参数, 由于可变的特性, 会导致下次再调用函数时, 会复用上次调用的可变对象, 导致返回值错误。
如下例所示:
def add_item(item, container=[]):
container.append(item)
return container
if __name__ == '__main__':
c1 = add_item(10)
print(f"第一次添加元素: ", c1) # [10]
c2 = add_item(20)
print(f"第二次添加元素: ", c2) # [10, 20]
如果要保证可变对象不被复用, 可以搭配使用None和if来改进
def add_item(item, container=None):
if container is None:
container = []
container.append(item)
return container
if __name__ == '__main__':
c1 = add_item(10)
print(f"第一次添加元素: ", c1) # [10]
c2 = add_item(20)
print(f"第二次添加元素: ", c2) # [20]
🪫 遍历操作列表的问题
列表作为可变对象, 除了默认参数的陷阱, 在进行遍历修改的时候还有一些坑需要注意。
names = ['Alice', 'Bob', 'Ella', 'Frank', 'Jery', 'Jack']
for name in names:
names.remove(name)
print(names) # ['Bob', 'Frank', 'Jack']
当我们通过for循环遍历删除列表元素时, 按道理来说应该能够将元素全部删除的, 但是结果发现有部分元素并没有被删除掉。
为什么会这样? 看下面的图就可以理解。

列表作为可变对象, 操作之后整个列表 遍历位序都会发生改变, 因此遍历与操作不能在同一个列表上进行操作。
解决这个问题也很简单, 可以使用切片方法将列表复制一份, 去操作复制的列表即可。
names = ['Alice', 'Bob', 'Ella', 'Frank', 'Jery', 'Jack']
for name in names[:]:
names.remove(name)
print(names) # []
📚 直接赋值 VS 浅拷贝 VS 深拷贝
有一些场景中, 我们需要将对象拷贝。
对象拷贝有三种方法:
- 直接赋值
- 浅拷贝 (
copy) - 深拷贝 (
deepcopy)
上面我们提到, 对象有可变对象和不可变对象, 那么在直接赋值, 浅拷贝或深拷贝时, 被拷贝的对象会不会影响原对象? 如果不可变对象是嵌套的拷贝结果会是怎样的?
📗 直接赋值 =
直接赋值实际上是对象的引用。当将一个变量赋值给另一个变量时, 两个变量指向同一个对象, 如果修改了一个变量, 另一个变量也会受影响。
a = [1, 2]
b = a # 将a以赋值的方式拷贝给b
# 可以看到a和b指向同一个列表对象
print(hex(id(a))) # 0x1f18ccbd0c0
print(hex(id(b))) # 0x1f18ccbd0c0
# 在b中添加元素之后, 再去查看, 发现a和b都改变了
b.append(3)
print(a) # [1, 2, 3]
print(b) # [1, 2, 3]
📙浅拷贝 copy
不同于直接赋值, 浅拷贝则会创建一个新的对象, 但不会递归地复制子对象。
from copy import copy
a = [1,2]
b = copy(a) # 将a进行浅拷贝并赋值给b
# 可以看到a和b指向的是不同的列表对象
print(hex(id(a))) # 0x2178f4ad800
print(hex(id(b))) # 0x2178f4ad0c0
# 在b内添加元素之后并不影响a
b.append(3)
print(a) # [1,2]
print(b) # [1,2,3]
使用浅拷贝的方式, 很大程度上避免了修改被拷贝的对象, 影响原对象的问题。
但如果对象是嵌套值, 则会有很大不同。
from copy import copy
a = [[1,2],[4,5]]
b = copy(a)
b[0].append(3)
# 对嵌套列表a进行浅拷贝之后赋值给b, 修改b后查看
# a与b的元素都改变了
print(a) # [[1, 2, 3], [4, 5]]
print(b) # [[1, 2, 3], [4, 5]]
由此可以看出, 如果是嵌套结构, 浅拷贝的对象的变动仍然会影响原对象。
📘深拷贝 deepcopy
深拷贝会递归地复制对象及其所有子对象, 生成一个完全独立的新对象。
from copy import deepcopy
a = [[1,2],[4,5]]
b = deepcopy(a)
b[0].append(3)
# 对嵌套列表a进行深拷贝之后赋值给b, 修改b后查看
# b的变动并没有影响a
print(a) # [[1, 2], [4, 5]]
print(b) # [[1, 2, 3], [4, 5]]
🧲 几种拷贝方式的总结
- 性能: 浅拷贝比深拷贝更快, 因为它只复制对象的引用, 而不是递归地复制所有子对象
- 内存使用: 深拷贝会占用更多内存, 因为创建了对象及其所有子对象的副本
- 适用场景: 如果对象包含可变的子对象, 并且需要修改子对象不影响原对象, 应该使用深拷贝; 如果对象不包含可变的子对象, 或者无需修改子对象, 可以使用浅拷贝
🎃 一个小补充
列表、字典和集合都含有copy()方法, 且都是浅拷贝方法
data1 = [[1, 5, 7], [2, 4, 6]]
data2 = {'id': '1001', 'name': 'Alice', 'score': [98, 79, 82]}
data3 = {1, 2, 3, 4, 5}
# 拷贝嵌套列表对象之后添加元素, 原对象改变
copy_data1 = data1.copy()
copy_data1[1].append(8)
print(data1) # [[1, 5, 7], [2, 4, 6, 8]]
# 拷贝嵌套字典对象之后添加元素, 原对象改变
copy_data2 = data2.copy()
copy_data2['score'].append(69)
print(data2) # {'id': '1001', 'name': 'Alice', 'score': [98, 79, 82, 69]}
# 集合是无序且元素唯一的数据结构, 集合元素必须是可哈希的, 不能直接嵌套, 但本身copy()行为是浅拷贝
# 如果搭配frozenset()就是可嵌套的
copy_data3 = data3.copy()
print(data3) # {1, 2, 3, 4, 5}
🎯 总结
可变对象与不可变对象
可变对象: list, dict, set, bytearray
不可变对象: int, float, str, tuple, frozenset, bytes
如何区分可变对象与不可变对象?
对象在堆区中的"内容区域"是否允许被修改
对象参数的传递
不可变对象: 函数中对参数(对象)的"修改"实际上是创建新的对象
可变对象: 函数中对参数(对象)的修改会影响原对象
对象可变特性带来的问题
👉 默认参数陷阱(可以搭配None和if进行优化)
👉 删除可变对象中的元素时可能会导致删除异常(不要在原对象上操作)
几种拷贝方式对原对象的影响
是否影响原对象: 🔴(影响) 🟢(不影响)
| 操作拷贝对象 | 操作拷贝对象的子对象 | |
|---|---|---|
| 直接赋值 | 🔴 | 🔴 |
| 浅拷贝 | 🟢 | 🔴 |
| 深拷贝 | 🟢 | 🟢 |
适用场景
深拷贝: 对象包含可变的子对象, 并且需要修改子对象不影响原对象 (性能优先)
浅拷贝: 对象不包含可变的子对象, 或者无需修改子对象 (功能优先)


















 1568
1568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









