





Python列表与元组底层原理深度解析:从C结构到性能优化(含mermaid图解+实战代码)
前言
列表(List)和元组(Tuple)是Python最常用的序列类型,看似简单的[1,2,3]和(1,2,3),底层实现却差异巨大。很多开发者只知道“列表可变、元组不可变”,却不清楚其内部机制导致的性能差异和适用场景。
本文从CPython源码出发,拆解两者的C结构、内存布局、核心机制,结合mermaid图解和实战代码,帮你从“会用”到“精通”,面试遇到底层问题也能轻松应对!
一、核心结构揭秘:列表和元组的C语言实现
Python的列表和元组在CPython中均有对应的结构体,这是它们特性差异的根源。
1. 列表(List):动态数组的精密设计
列表本质是支持过度分配(Over-allocation)的动态数组,结构体定义在listobject.h中:
typedef struct {
PyObject_VAR_HEAD // 可变对象头部(引用计数、类型、逻辑长度ob_size)
PyObject **ob_item; // 指向元素指针数组的指针
Py_ssize_t allocated; // 实际分配的容量(≥ ob_size)
} PyListObject;
列表内存布局图解
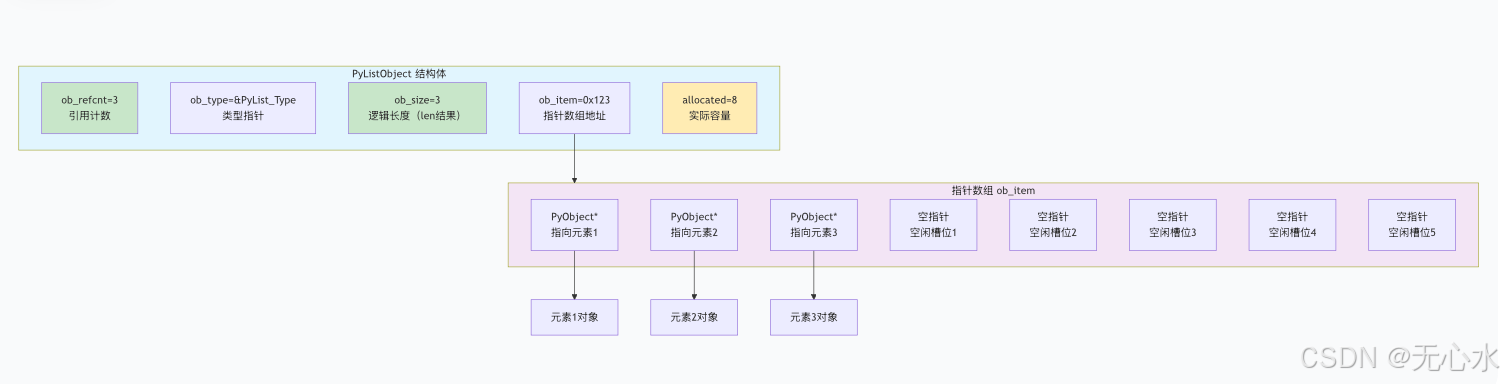
关键特性:
Python列表在CPython中的内存布局包含以下关键部分:
- PyListObject结构体:
ob_refcnt:引用计数,跟踪有多少变量引用此列表ob_type:类型指针,指向列表类型对象ob_size:逻辑长度,即len(lst)返回的值ob_item:指向指针数组的地址allocated:实际分配的容量,通常大于逻辑长度
- 指针数组(ob_item):
- 包含实际元素数量的有效指针
- 剩余的空闲槽位用于后续的
append()操作 - 每个指针指向对应的Python对象
- 过度分配策略:
- 示例中逻辑长度=3,但分配容量=8
- 这种设计减少了频繁重新分配的开销
- 当列表增长时,Python会按一定策略(约1.125倍)增加容量
这种设计使得Python列表在追加操作时具有较好的平均时间复杂度O(1)。
2. 元组(Tuple):不可变数组的极致优化
元组是固定大小的内联数组,结构体定义在tupleobject.h中:
typedef struct {
PyObject_VAR_HEAD // 可变对象头部(仅包含引用计数、类型、长度ob_size)
PyObject *ob_item[1]; // 柔性数组,直接内联存储元素指针
} PyTupleObject;
元组内存布局mermaid图解
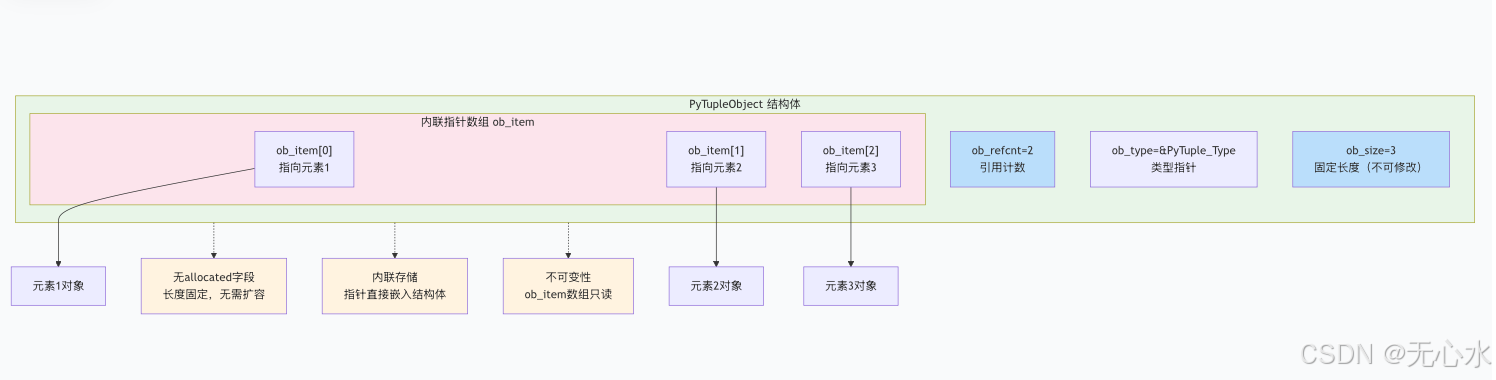
关键特性详解:
- 无
allocated字段:- 元组长度在创建时固定,不需要记录分配容量
- 无需扩容机制,内存一次性分配完成
ob_item内联存储:- 指针直接嵌入PyTupleObject结构体,减少内存碎片
- 比列表少一层指针跳转,访问速度更快
- 内存布局更紧凑,缓存友好
- 不可变性:
- C层面
ob_item数组为只读,无法修改指针指向 - 但元素本身如果是可变对象(如列表),仍然可以修改其内容
- 示例:
tup = (1, 2, [3, 4])中tup[2].append(5)是允许的
- C层面
与列表内存布局的对比:
| 特性 | 列表 | 元组 |
|---|---|---|
| 内存分配 | 动态过度分配 | 一次性固定分配 |
| 指针存储 | 额外的指针数组 | 内联在结构体中 |
| 可变性 | 可修改长度和内容 | 创建后不可修改 |
| 内存效率 | 较低(有过度分配) | 较高(紧凑存储) |
| 访问速度 | 稍慢(多一次指针跳转) | 稍快(直接访问) |
这种设计使得元组在作为字典键、函数返回值等场景下具有更好的性能和内存效率。
二、核心机制差异:扩容 vs 缓存
1. 列表的动态扩容机制
列表的append()看似简单,实则隐藏着“过度分配”的优化逻辑,避免每次追加都重新分配内存:
扩容规则(CPython 3.11+)
- 初始状态:
allocated=0,首次append后allocated=4; - 当
ob_size == allocated(容量耗尽),新容量 =max(ob_size*2, ob_size+8); - 小列表优化:长度<9时扩容幅度较大,长度≥9后按1.125倍增长,平衡内存与性能。
扩容流程mermaid图解
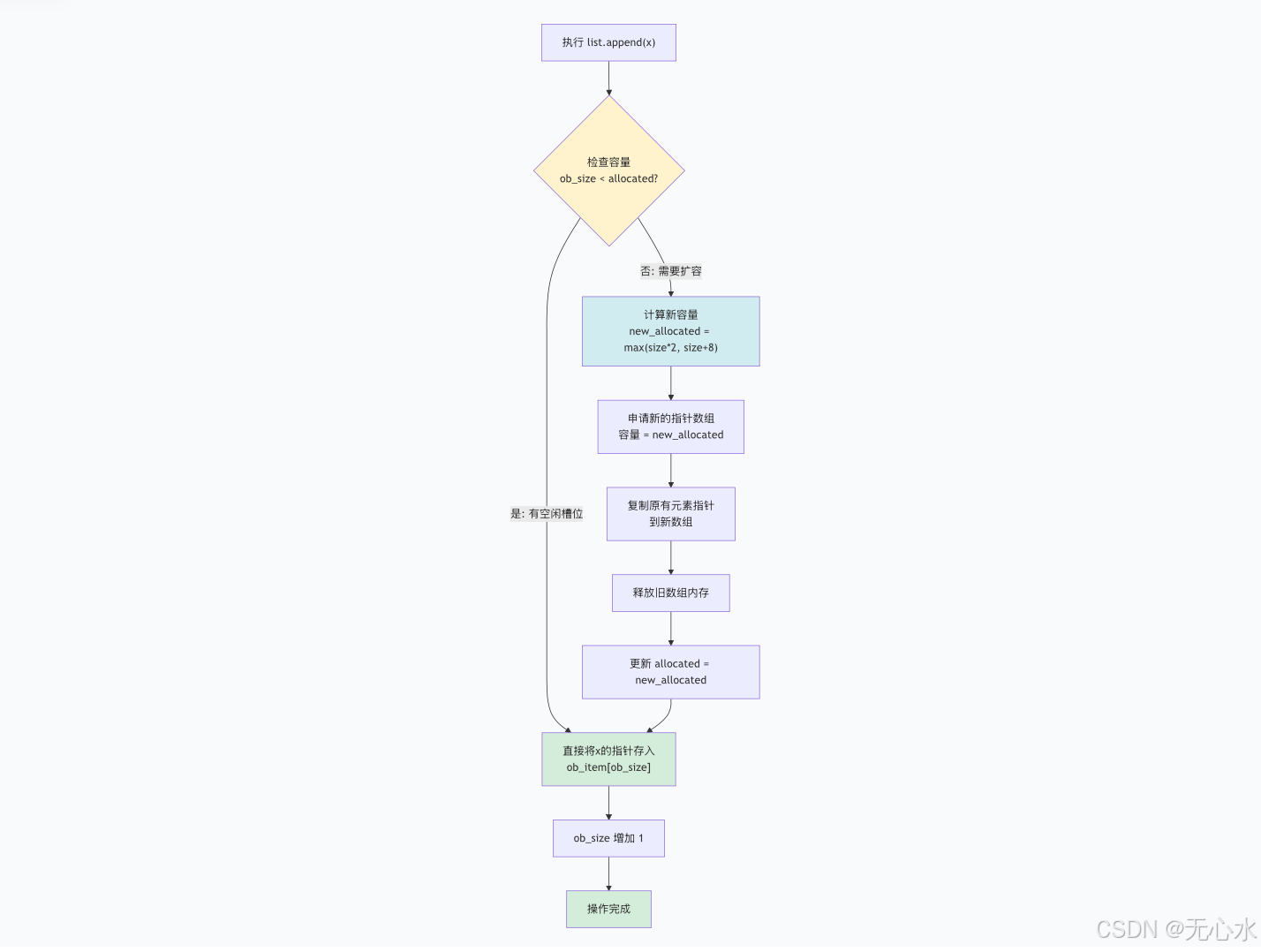
扩容流程详细说明:
- 容量检查阶段:
- 当执行
append()操作时,首先检查当前逻辑长度ob_size是否小于已分配容量allocated - 如果有空闲槽位,直接使用,时间复杂度O(1)
- 如果已满,触发扩容机制
- 当执行
- 扩容计算阶段:
- 新容量计算公式通常为:
max(size*2, size+8) - 对于小列表,倾向于使用
size+8策略 - 对于大列表,使用
size*2的倍增策略 - 这种混合策略平衡了内存使用和性能
- 新容量计算公式通常为:
- 内存重新分配阶段:
- 申请新的、更大容量的指针数组
- 将原有所有元素指针复制到新数组
- 释放旧的指针数组内存
- 更新
allocated字段为新容量值
- 元素插入阶段:
- 将新元素的指针存入
ob_item[ob_size]位置 - 逻辑长度
ob_size增加1
- 将新元素的指针存入
性能特点:
- 平摊时间复杂度:虽然单次扩容是O(n),但经过多次操作平摊后,平均每次append操作仍是O(1)
- 空间复杂度:由于过度分配,空间复杂度为O(n),但常数因子比实际元素数量大
- 内存使用:在扩容时会有短暂的内存峰值,旧数组和新数组同时存在
这种设计使得Python列表在动态增长时保持了较好的性能表现。
实战代码:分析列表扩容过程
import sys
def analyze_list_expansion():
"""分析列表扩容时的容量变化"""
lst = []
print(f"初始状态 - 长度: {len(lst)}, 容量(字节): {sys.getsizeof(lst)}")
for i in range(10):
lst.append(i)
print(f"添加元素{i}后 - 长度: {len(lst)}, 容量(字节): {sys.getsizeof(lst)}")
analyze_list_expansion()
# 输出示例(CPython 3.11):
# 初始状态 - 长度: 0, 容量(字节): 40
# 添加元素0后 - 长度: 1, 容量(字节): 72
# 添加元素1后 - 长度: 2, 容量(字节): 72
# 添加元素2后 - 长度: 3, 容量(字节): 72
# 添加元素3后 - 长度: 4, 容量(字节): 72
# 添加元素4后 - 长度: 5, 容量(字节): 104 # 扩容(4→8)
2. 元组的缓存机制(Free List)
元组的不可变性使其能被CPython激进缓存,尤其是长度≤20的“小元组”,复用率极高:
缓存原理
- CPython维护全局缓存数组
free_list[20],存储不同长度的空闲元组; - 创建元组时,优先从缓存中取,避免频繁调用
malloc; - 元组被销毁时,不会释放内存,而是放回对应长度的缓存槽位。
实战代码:验证元组缓存
def verify_tuple_cache():
"""验证小元组的缓存复用"""
t1 = (1, 2)
t2 = (1, 2)
print(f"t1 ID: {id(t1)}, t2 ID: {id(t2)}")
print(f"t1与t2是否为同一对象: {t1 is t2}") # 输出True(大概率)
verify_tuple_cache()
三、性能对比:列表 vs 元组(实战代码)
1. 内存占用对比
import sys
def compare_memory():
"""对比相同元素的列表和元组内存占用"""
data = range(100)
lst = list(data)
tup = tuple(data)
print(f"列表内存占用: {sys.getsizeof(lst)} 字节") # 约904字节
print(f"元组内存占用: {sys.getsizeof(tup)} 字节") # 约808字节
print(f"元组比列表省内存: {sys.getsizeof(lst) - sys.getsizeof(tup)} 字节")
compare_memory()
结论:元组无allocated字段和额外指针数组开销,内存占用比列表少10%左右。
2. 创建与访问速度对比
import timeit
def compare_performance():
"""对比创建和访问速度"""
# 1. 创建速度
list_create = timeit.timeit('list(range(1000))', number=10000)
tuple_create = timeit.timeit('tuple(range(1000))', number=10000)
print(f"列表创建时间: {list_create:.4f}s")
print(f"元组创建时间: {tuple_create:.4f}s")
print(f"元组创建比列表快: {list_create/tuple_create:.2f}倍")
# 2. 访问速度
setup = """
lst = list(range(1000))
tup = tuple(range(1000))
"""
list_access = timeit.timeit('x = lst[500]', setup=setup, number=10000000)
tuple_access = timeit.timeit('x = tup[500]', setup=setup, number=10000000)
print(f"\n列表访问时间: {list_access:.4f}s")
print(f"元组访问时间: {tuple_access:.4f}s")
print(f"访问速度差异: {abs(list_access - tuple_access):.4f}s")
compare_performance()
结论:元组创建速度比列表快10-20%,访问速度几乎无差异(均为O(1))。
3. 增删改性能对比
def compare_modify_performance():
"""对比增删改操作性能"""
# 列表append(O(1)均摊)
list_append = timeit.timeit('lst.append(999)', setup='lst = [1,2,3]', number=1000000)
# 元组拼接(O(n),创建新元组)
tuple_concat = timeit.timeit('tup + (999,)', setup='tup = (1,2,3)', number=1000000)
print(f"列表append时间: {list_append:.4f}s")
print(f"元组拼接时间: {tuple_concat:.4f}s")
print(f"列表append比元组拼接快: {tuple_concat/list_append:.2f}倍")
compare_modify_performance()
结论:列表原地修改(append)极快,元组拼接需创建新对象,性能差距巨大。
四、不可变性的深层解析
1. 元组的“浅层不可变”
元组的不可变是“指针不可变”,而非元素本身不可变:
def tuple_shallow_immutable():
"""元组的浅层不可变性"""
t = ([1, 2], 'a')
t[0].append(3) # 允许!列表元素本身可变
print(f"修改后元组: {t}") # 输出:([1,2,3], 'a')
# t[1] = 'b' # 报错:TypeError(无法修改指针指向)
tuple_shallow_immutable()
2. 列表的“动态可变”本质
列表的可变源于ob_item指针数组可修改:
- 追加元素:修改指针数组的空闲槽位;
- 插入/删除:移动指针数组中的元素指针;
- 改变元素:直接修改指针指向的对象(或替换指针)。
五、实战建议:何时用列表,何时用元组?
1. 用列表的场景
- 元素数量动态变化(增删改频繁);
- 存储同质数据(如
['apple', 'banana']); - 作为栈/队列使用(
append/pop)。
# 列表典型场景:动态收集日志
logs = []
with open('app.log', 'r') as f:
for line in f:
if 'ERROR' in line:
logs.append(line.strip())
2. 用元组的场景
- 数据不可变(如配置常量、坐标点);
- 作为字典键/集合元素(需哈希稳定);
- 函数返回多个值(语义清晰);
- 存储异质数据(如
(name, age, score))。
# 元组典型场景:字典键(坐标点)
locations = {(10.2, 20.3): '办公区', (30.5, 40.1): '休息区'}
# 函数返回多值(自动打包为元组)
def get_user_info():
return 'Alice', 25, 95.5 # 返回元组
name, age, score = get_user_info() # 解包
3. 性能陷阱规避
- ❌ 避免用元组拼接创建大对象(O(n²)时间复杂度);
- ✅ 用列表构建后转元组(O(n)时间复杂度):
# 高效创建大元组 lst = [] for i in range(1000): lst.append(i) tup = tuple(lst) # 比tup += (i,)快100倍
六、总结:从底层到实战的核心差异
| 维度 | 列表(List) | 元组(Tuple) |
|---|---|---|
| 底层结构 | 动态数组(PyListObject) | 固定内联数组(PyTupleObject) |
| 容量管理 | 过度分配+动态扩容 | 固定大小,无扩容 |
| 内存开销 | 较高(含allocated字段) | 较低(内联存储) |
| 创建速度 | 较慢(需初始化扩容逻辑) | 较快(缓存复用) |
| 可变特性 | 完全可变(增删改) | 浅层不可变(指针不可改) |
| 适用场景 | 动态数据集合 | 静态数据、字典键、多值返回 |
理解列表和元组的底层差异,不仅能帮你写出更高效的代码,更能让你在面试中从容应对“列表元组区别”“Python动态数组实现”等深度问题。
思考题:为什么list.insert(0, x)比list.append(x)慢得多?(提示:插入需移动所有元素指针)
如果在实际开发中遇到列表/元组的性能瓶颈,欢迎在评论区留言交流!



















 71万+
71万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











