




Python列表vs元组终极指南:性能对比+实战场景全解析
资深工程师告诉你什么时候该用列表,什么时候该用元组
前言:为什么选择很重要?
在Python编程中,列表和元组是最常用的两种数据结构。很多开发者在选择时感到困惑,其实选择正确的数据结构能让代码性能提升20%以上。本文将通过深度对比和实际案例,帮你彻底理清两者的区别和应用场景。
核心概念:可变性决定一切
基本语法对比
# 列表 - 可变 (Mutable)
my_list = [1, 2, 3, "hello"]
my_list[0] = 10 # ✅ 可以修改
my_list.append(4) # ✅ 可以添加
my_list.remove(2) # ✅ 可以删除
print(my_list) # [10, 3, 'hello', 4]
# 元组 - 不可变 (Immutable)
my_tuple = (1, 2, 3, "world")
# my_tuple[0] = 10 # ❌ TypeError: 不支持修改
# my_tuple.append(4) # ❌ 没有append方法
共同特征
- 有序集合,可存放任意数据类型
- 支持负数索引和切片操作
- 可以相互嵌套和类型转换
# 混合数据类型示例
l = [1, 2, 'hello', 'world'] # 列表
tup = ('jason', 22) # 元组
# 切片操作
l[1:3] # 返回 [2, 'hello']
tup[1:3] # 返回 (22,)
# 负数索引
l[-1] # 'world'
tup[-1] # 22
# 类型转换
tuple([1, 2, 3]) # (1, 2, 3)
list((1, 2, 3)) # [1, 2, 3]
性能深度剖析:元组为什么更快?
内存占用对比
import sys
# 内存占用测试
l = [1, 2, 3]
tup = (1, 2, 3)
print(f"列表占用内存: {sys.getsizeof(l)} 字节") # 64字节
print(f"元组占用内存: {sys.getsizeof(tup)} 字节") # 48字节
内存差异原因:
- 列表需要额外空间存储指针和分配长度
- 元组存储空间固定,不需要过度分配机制
速度性能实测
import timeit
# 初始化速度测试
list_time = timeit.timeit('x=[1,2,3,4,5,6]', number=1000000)
tuple_time = timeit.timeit('x=(1,2,3,4,5,6)', number=1000000)
print(f"列表初始化时间: {list_time:.4f}秒")
print(f"元组初始化时间: {tuple_time:.4f}秒")
print(f"元组比列表快: {list_time/tuple_time:.1f}倍")
性能测试结果:
- 初始化速度:元组比列表快5-10倍
- 索引操作:两者几乎无差别
- 迭代速度:元组比列表快10-15%
选择决策流程图
实战场景选择指南
应该使用列表的场景
1. 动态数据集合
# 用户行为日志记录
user_actions = []
user_actions.append("login")
user_actions.append("view_product")
user_actions.append("add_to_cart")
user_actions.remove("login") # 动态修改
# 待办事项列表
todo_list = ["学习Python", "写项目", "阅读文档"]
todo_list.append("练习编程") # 添加新任务
todo_list[1] = "重构项目" # 修改任务
2. 相同类型的数据序列
# 数字计算
numbers = [1, 2, 3, 4, 5]
squares = [x**2 for x in numbers] # 列表推导式
# 字符串处理
names = ["Alice", "Bob", "Charlie"]
names.sort() # 原地排序
3. 需要丰富列表操作的场景
data = [1, 2, 3]
data.extend([4, 5, 6]) # 扩展列表
data.insert(0, 0) # 插入元素
popped = data.pop() # 弹出元素
data.reverse() # 反转列表
应该使用元组的场景
1. 固定数据记录
# 像数据库中的一行记录
person = ("张三", 25, "工程师") # 姓名, 年龄, 职业
point = (100, 200) # 坐标点 (x, y)
color = (255, 128, 0) # RGB颜色
# 配置信息(不应该被修改)
DATABASE_CONFIG = ("localhost", 5432, "my_database")
API_ENDPOINTS = ("/users", "/products", "/orders")
2. 作为字典的键
# 坐标位置映射
locations = {
(40.7128, -74.0060): "纽约", # 坐标作为键
(35.6895, 139.6917): "东京",
(48.8566, 2.3522): "巴黎"
}
# 缓存键
cache = {}
key = (user_id, "profile_data") # 元组作为复合键
cache[key] = user_data
3. 函数返回多个值
def analyze_data(data):
"""分析数据并返回多个统计值"""
total = sum(data)
average = total / len(data)
maximum = max(data)
minimum = min(data)
return total, average, maximum, minimum # 自动打包为元组
# 调用时解包
sum_val, avg_val, max_val, min_val = analyze_data([1, 2, 3, 4, 5])
# 如果只需要部分值
_, average, _, _ = analyze_data([1, 2, 3, 4, 5]) # 只关心中间值
4. 保护数据不被意外修改
# 数学常数
CONSTANTS = (3.14159, 2.71828, 1.41421)
# 枚举类型的替代
STATUS_CODES = (200, 404, 500)
COLORS = ("RED", "GREEN", "BLUE")
内置函数与方法大全
列表专属函数
l = [3, 2, 3, 7, 8, 1]
l.count(3) # 2 → 统计元素出现次数
l.index(7) # 3 → 返回首次出现索引
l.reverse() # 原地倒转 → [1, 8, 7, 3, 2, 3]
l.sort() # 原地排序 → [1, 2, 3, 3, 7, 8]
l.append(9) # 添加元素 → [1, 2, 3, 3, 7, 8, 9]
l.extend([10, 11]) # 扩展列表 → [1, 2, 3, 3, 7, 8, 9, 10, 11]
l.pop() # 弹出最后一个元素 → 11
l.remove(3) # 移除第一个匹配元素 → [1, 2, 3, 7, 8, 9, 10]
元组可用函数
tup = (3, 2, 3, 7, 8, 1)
tup.count(3) # 2 → 统计出现次数
tup.index(7) # 3 → 返回首次出现索引
list(reversed(tup)) # [1, 8, 7, 3, 2, 3] → 返回新列表
sorted(tup) # [1, 2, 3, 3, 7, 8] → 返回新列表
实际项目中的最佳实践
数据处理典型模式
# 原始数据 - 使用元组保证数据完整性
raw_students = [
("Alice", 85, "Math"),
("Bob", 92, "Science"),
("Charlie", 78, "History")
]
# 处理过程 - 使用列表进行动态操作
students_list = list(raw_students) # 转换为列表进行处理
# 添加新数据
students_list.append(("Diana", 88, "Art"))
# 过滤和转换数据
top_students = [
(name, score, subject)
for name, score, subject in students_list
if score > 80
]
# 按成绩排序
top_students.sort(key=lambda x: x[1], reverse=True)
# 最终结果 - 如果需要保护数据,转回元组
final_results = tuple(top_students)
函数设计中的高级用法
def process_user_data(user_id):
"""处理用户数据并返回多个结果"""
# 模拟数据查询
user_info = get_user_from_db(user_id)
user_stats = calculate_user_stats(user_id)
recommendations = generate_recommendations(user_id)
# 返回元组,明确表示这是固定的一组数据
return user_info, user_stats, recommendations
# 使用星号操作符处理部分解包
info, *other_data = process_user_data(123)
# info 包含用户信息
# other_data 包含 [用户统计, 推荐内容]
# 或者使用字典解包提高可读性
def get_coordinates():
return 100, 200, 50 # x, y, z坐标
x, y, z = get_coordinates()
coordinates = {"x": x, "y": y, "z": z}
性能优化技巧
空集合创建选择
# 创建空列表
empty_list = [] # ✅ 推荐:更简洁高效
empty_list = list() # ⚠️ 可用:多一步函数调用
# 创建空元组
empty_tuple = () # ✅ 推荐
empty_tuple = tuple() # ⚠️ 可用
元组"修改"技巧
# 虽然元组不可变,但可以通过创建新元组实现"修改"
tup = (1, 2, 3, 4)
# 添加元素
new_tup = tup + (5,) # (1, 2, 3, 4, 5)
# "修改"特定位置(实际上是创建新元组)
new_tup = tup[:2] + (99,) + tup[3:] # (1, 2, 99, 4)
# 合并元组
combined = tup + (5, 6, 7) # (1, 2, 3, 4, 5, 6, 7)
列表性能优化
# 预分配列表大小(已知长度时)
size = 1000
my_list = [None] * size # 避免频繁扩容
# 使用列表推导式代替循环
# ❌ 较慢的方式
result = []
for i in range(1000):
if i % 2 == 0:
result.append(i * 2)
# ✅ 更快的方式
result = [i * 2 for i in range(1000) if i % 2 == 0]
全面对比总结表
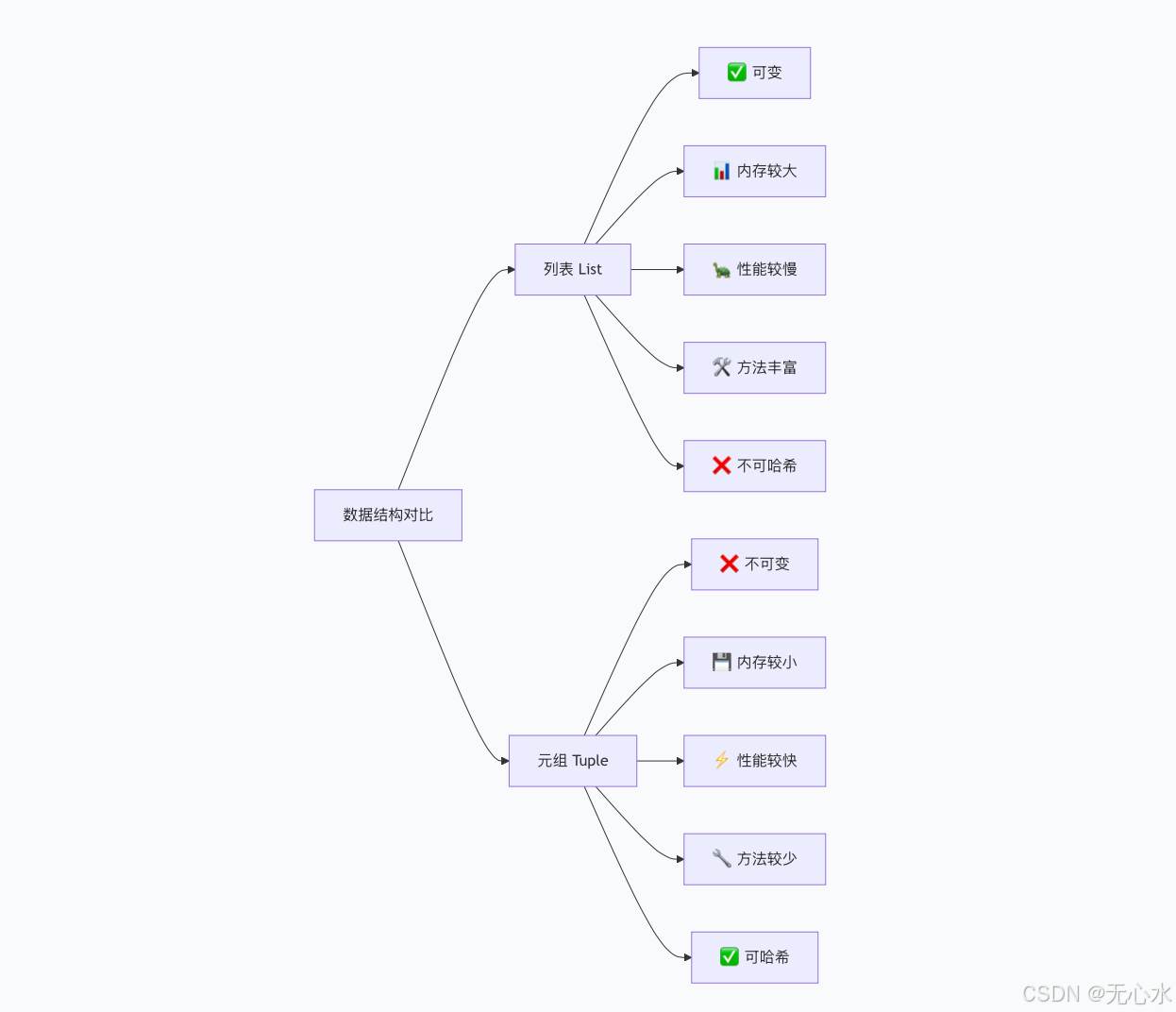
| 特性 | 列表 (List) | 元组 (Tuple) | 优势方 |
|---|---|---|---|
| 可变性 | ✅ 可变 | ❌ 不可变 | 视场景 |
| 语法 | [1, 2, 3] | (1, 2, 3) | - |
| 内存占用 | 较大 | 🎯 较小 | 元组 |
| 创建速度 | 较慢 | ⚡ 较快 | 元组 |
| 迭代速度 | 较慢 | ⚡ 较快 | 元组 |
| 作为字典键 | ❌ 不能 | ✅ 可以 | 元组 |
| 内置方法 | 🛠️ 丰富 | 较少 | 列表 |
| 数据安全 | 较低 | 🛡️ 较高 | 元组 |
| 使用场景 | 动态数据集合 | 固定数据记录 | - |
经验法则总结
选择列表当:
- ✅ 数据需要被修改、添加、删除
- ✅ 处理同质类型的数据集合
- ✅ 需要丰富的内置方法进行操作
- ✅ 数据量会动态变化
选择元组当:
- ✅ 数据是固定的、不应该被修改
- ✅ 数据是异质的(不同类型组成一个逻辑单元)
- ✅ 需要作为字典的键使用
- ✅ 性能敏感的场景
- ✅ 想要明确表达"这些数据不应该被改变"的意图
一句话总结
用列表来处理会变化的数据集合,用元组来表示固定的数据记录。
记住这个简单的原则,你就能在95%的情况下做出正确的选择。在实际开发中,当你犹豫不决时,可以先使用元组,因为从元组转换到列表的成本很低,而且元组更安全、更高效。
掌握了列表和元组的正确使用方法,你的Python代码将更加高效、安全和易于维护。现在就开始在实践中应用这些知识吧!




















 71万+
71万+


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










