







引言:为什么Embedding是文本分类的“瑞士军刀”?
在自然语言处理(NLP)领域,文本分类是最基础也最核心的任务之一——它能让机器自动识别邮件是否为垃圾邮件、评论是正面还是负面、新闻属于科技还是娱乐。但传统方法往往依赖人工设计特征(如关键词提取、TF-IDF),不仅耗时,还难以捕捉文本的深层语义。
Embedding的出现彻底改变了这一局面:它能将文本(句子、段落、文档)转化为固定长度的稠密向量,让“语义相似的文本向量距离更近”。例如,“蓝牙耳机音质好”和“这款无线耳机音效棒”会被映射到向量空间中相近的位置,而这种“语义理解”能力正是传统方法缺失的。
本文将整合OpenAI Embedding与Sentence-Transformers两大工具,结合机器学习分类器,打造一套从入门到精通的文本分类方案。无论是标注数据稀缺的场景(Few-shot学习),还是有充足数据的大规模任务,都能找到对应的解决方案。
一、核心原理:从文本到向量的“语义翻译”
1.1 什么是Embedding?
Embedding(嵌入向量)是将非结构化文本转化为结构化数值向量的技术。它的核心优势在于:
- 语义保留:向量的距离直接反映文本语义的相似度(如余弦相似度越高,语义越近);
- 固定维度:无论输入文本长度如何,输出向量维度固定(如OpenAI的
text-embedding-ada-002为1536维,Sentence-Transformers的m3e-base为768维),便于机器学习模型处理; - 通用性:预训练的Embedding模型可直接复用,无需针对特定任务重新训练。
1.2 文本分类的核心流程
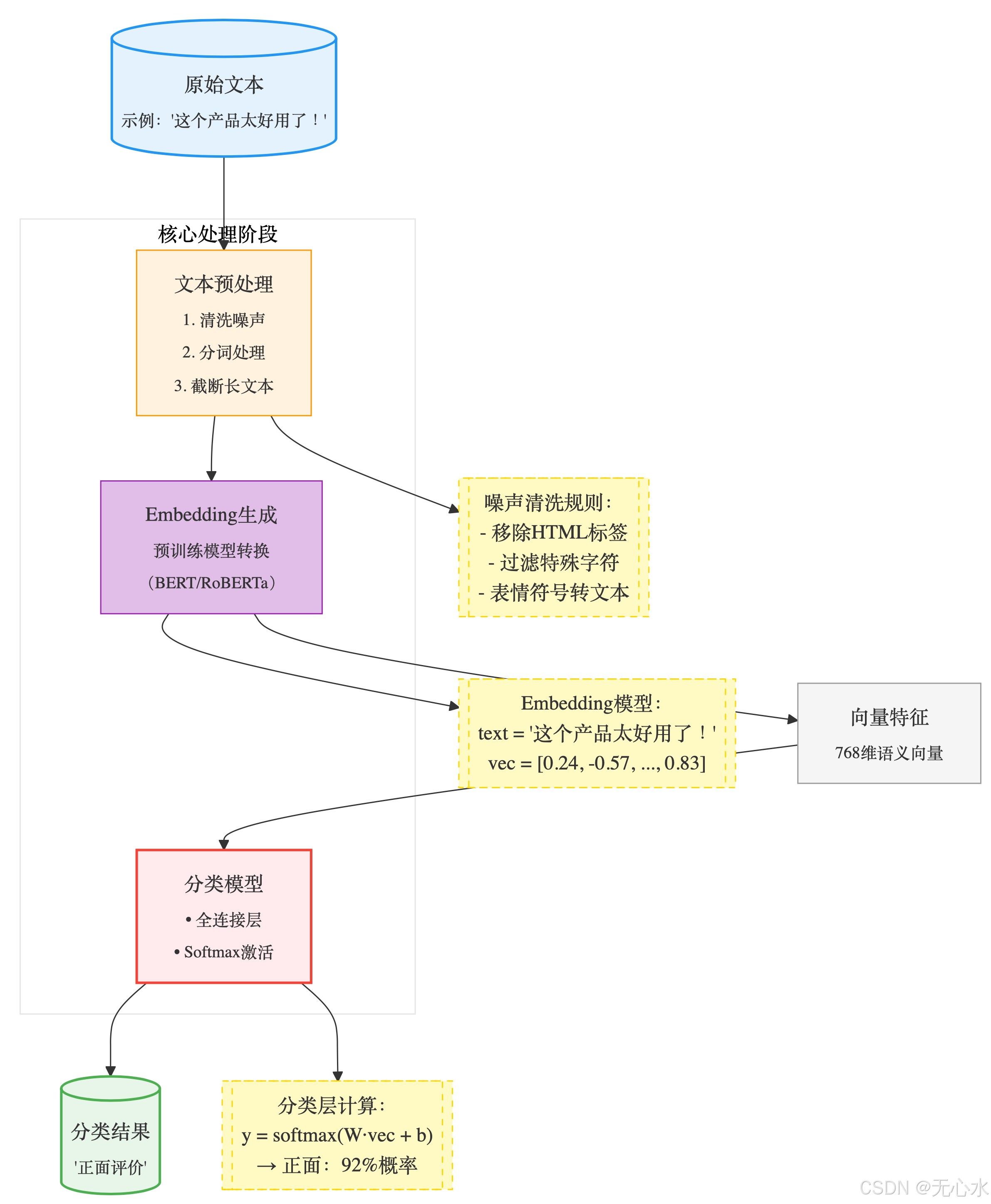
文本分类流程详解
- 文本预处理(关键净化步骤):
- 噪声清洗:移除HTML标签、特殊符号、非文字内容
- 分词处理:中文使用Jieba分词,英文使用NLTK
- 长度控制:截断超过512字符的文本(BERT最大长度限制)
- 示例:
"这个产品👍太棒了!<br>" → "这个产品 太棒了"
- Embedding生成(语义向量转换):
- 预训练模型:
- 中文:
bert-base-chinese - 英文:
roberta-base
- 中文:
- 向量维度:768维(BERT基础版)
- 计算原理:
# Hugging Face 实现示例 from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese") model = AutoModel.from_pretrained("bert-base-chinese") inputs = tokenizer("这个产品太好用了!", return_tensors="pt") outputs = model(**inputs) embedding = outputs.last_hidden_state[:, 0, :] # 取[CLS]向量
- 预训练模型:
- 分类模型(神经网络结构):
- 数学表达:
h=ReLU(W1⋅embedding+b1)scores=W2⋅h+b2prob=softmax(scores) \begin{aligned} h &= \text{ReLU}(W_1 \cdot \text{embedding} + b_1) \\ \text{scores} &= W_2 \cdot h + b_2 \\ \text{prob} &= \text{softmax}(\text{scores}) \end{aligned} hscoresprob=ReLU(W1⋅embedding+b1)=W2⋅h+b2=softmax(scores)
- 数学表达:
- 输出结果(可扩展应用):
- 多分类场景:新闻分类(政治/经济/体育)
- 情感分析:正面/负面/中性
- 意图识别:咨询/投诉/购买
二、技术选型:两大Embedding工具对比与实战
2.1 OpenAI Embedding:开箱即用的高效方案
OpenAI的text-embedding-ada-002是目前最受欢迎的通用Embedding模型之一,支持多语言,语义捕捉能力强,适合快速上手。
关键代码:批量获取OpenAI Embedding
import backoff
import os
from openai import OpenAI
import pandas as pd
# 初始化客户端
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'])
# 带重试机制的批量获取函数(解决API限流问题)
@backoff.on_exception(backoff.expo, openai.RateLimitError)
def get_openai_embeddings(texts: list, batch_size=1000):
"""
批量获取OpenAI Embedding向量
texts: 文本列表
batch_size: 每批处理的文本数量(不超过API限制)
"""
embeddings = []
for i in range(0, len(texts), batch_size):
batch = texts[i:i+batch_size]
response = client.embeddings.create(
input=batch,
model="text-embedding-ada-002" # 1536维向量
)
embeddings.extend([item.embedding for item in response.data])
return embeddings
# 示例:生成Embedding
texts = ["这款手机拍照效果极佳", "餐厅的服务非常贴心"]
embeddings = get_openai_embeddings(texts)
print(f"向量维度:{len(embeddings[0])}") # 输出1536
优势与适用场景
- 优势:无需本地训练,API调用简单;向量质量高,跨语言表现好;
- 适用场景:快速原型开发、中小规模文本分类(需考虑API成本)。
2.2 Sentence-Transformers:本地化部署的灵活选择
Sentence-Transformers是开源库,提供数十种预训练Embedding模型,支持本地部署,适合对成本敏感或数据隐私要求高的场景。
关键代码:加载模型与生成向量
from sentence_transformers import SentenceTransformer
# 加载多语言模型(支持中文)
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2') # 384维向量
# 中文优化模型推荐:'moka-ai/m3e-base'(768维)或 'BAAI/bge-large-zh-v1.5'(1024维)
# 生成文本向量
texts = ["这款手机拍照效果极佳", "餐厅的服务非常贴心"]
embeddings = model.encode(texts)
print(f"向量维度:{embeddings.shape[1]}") # 输出384(因模型而异)
模型选择指南
| 模型名称 | 维度 | 特点 | 适用场景 |
|---|---|---|---|
text-embedding-ada-002(OpenAI) | 1536 | 通用能力强,API调用 | 快速开发、跨语言任务 |
paraphrase-multilingual-MiniLM-L12-v2 | 384 | 轻量多语言,速度快 | 本地部署、实时分类 |
moka-ai/m3e-base | 768 | 中文优化,语义捕捉好 | 中文文本分类、检索 |
BAAI/bge-large-zh-v1.5 | 1024 | 高精度中文模型 | 高要求的中文任务 |
小贴士:模型维度越高,语义信息越丰富,但计算成本也越高。中小规模任务优先选择384-768维模型。
三、数据处理:避坑指南与高效技巧
无论使用哪种Embedding工具,数据处理都是影响最终效果的关键步骤。以下是必须掌握的核心技巧:
3.1 文本清洗与过滤
Token长度限制处理
Embedding模型对输入文本长度有上限(如OpenAI模型支持最长8191 tokens),超过会导致API报错或截断。需提前过滤过长文本:
import tiktoken # OpenAI的分词库
import pandas as pd
# 1. 计算文本的token数量(适用于OpenAI模型)
encoding = tiktoken.get_encoding("cl100k_base") # 匹配text-embedding-ada-002
df = pd.DataFrame({"text": ["长文本内容...", "短文本"]})
df["n_tokens"] = df["text"].apply(lambda x: len(encoding.encode(x)))
# 2. 过滤超过8000 tokens的文本(预留安全边界)
df = df[df["n_tokens"] <= 8000]
# 3. Sentence-Transformers模型的长度处理
# 多数模型默认支持256-512 tokens,过长文本可截断
def truncate_text(text, model_name="paraphrase-multilingual-MiniLM-L12-v2", max_length=256):
model = SentenceTransformer(model_name)
tokens = model.tokenizer.tokenize(text)
if len(tokens) > max_length:
tokens = tokens[:max_length]
return model.tokenizer.convert_tokens_to_string(tokens)
df["text_truncated"] = df["text"].apply(lambda x: truncate_text(x))
噪声清洗
去除文本中的无效信息(如HTML标签、特殊符号):
import re
def clean_text(text):
# 去除HTML标签
text = re.sub(r'<.*?>', '', text)
# 去除多余空格和特殊符号
text = re.sub(r'[^\w\s,。,.!?]', '', text)
return text.strip()
df["text_cleaned"] = df["text"].apply(clean_text)
3.2 高效存储与读取
Embedding向量是浮点型数组,用CSV存储会占用大量空间且读取缓慢。推荐使用Parquet格式(压缩率高,速度快10倍以上):
# 存储Embedding向量
df["embedding"] = embeddings # 假设embeddings是生成的向量列表
df.to_parquet("text_embeddings.parquet", index=False)
# 读取数据
df = pd.read_parquet("text_embeddings.parquet")
# 提取向量作为特征(转换为numpy数组)
X = np.array(df["embedding"].tolist())
四、文本分类实战:两种核心方法详解
根据数据量和场景需求,文本分类可分为基于语义相似度(少数据场景)和有监督分类器(多数据场景)两种方法。
方法一:基于语义相似度的分类(Few-Shot/Zero-Shot)
当标注数据稀缺(如每个类别只有几个样本)时,可通过计算文本与类别“代表向量”的相似度实现分类。
核心原理
- 为每个类别生成“代表向量”(如类别名称的Embedding,或少量样本的平均向量);
- 计算待分类文本的Embedding与每个代表向量的余弦相似度;
- 将文本分到相似度最高的类别。
关键代码实现
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from sentence_transformers import SentenceTransformer
# 1. 准备数据(少量标注样本)
data = [
{"text": "这款手机屏幕清晰,运行流畅", "label": "电子产品"},
{"text": "餐厅环境优雅,菜品精致", "label": "餐饮"},
{"text": "电影剧情紧凑,特效震撼", "label": "影视娱乐"},
{"text": "路由器信号差,经常断网", "label": "电子产品"},
{"text": "咖啡馆的拿铁味道醇厚", "label": "餐饮"}
]
df = pd.DataFrame(data)
# 2. 生成文本Embedding
model = SentenceTransformer('moka-ai/m3e-base')
df["embedding"] = df["text"].apply(lambda x: model.encode(x))
# 3. 计算每个类别的代表向量(样本平均)
categories = df["label"].unique().tolist() # ["电子产品", "餐饮", "影视娱乐"]
category_embeddings = []
for cat in categories:
# 提取该类别所有样本的Embedding
cat_embeds = np.array(df[df["label"] == cat]["embedding"].tolist())
# 计算平均向量作为代表
cat_avg_embed = np.mean(cat_embeds, axis=0)
category_embeddings.append(cat_avg_embed)
category_embeddings = np.array(category_embeddings)
# 4. 分类新文本
new_texts = [
"刚买的蓝牙耳机音质超好", # 应属于“电子产品”
"求推荐一本好读的历史小说", # 无对应样本,可能分到最相似类别
"这家火锅店的毛肚很新鲜" # 应属于“餐饮”
]
new_embeddings = model.encode(new_texts)
# 5. 计算相似度
similarities = cosine_similarity(new_embeddings, category_embeddings)
# 6. 预测类别
predicted_labels = [categories[np.argmax(sim)] for sim in similarities]
# 输出结果
for text, label in zip(new_texts, predicted_labels):
print(f"文本:{text} → 预测类别:{label}")
效果优化技巧
- 提升代表向量质量:用“类别名称+描述”生成代表向量(如“电子产品:包括手机、耳机等数码产品”);
- 多样本加权平均:对类别下的样本按相关性加权(如更典型的样本权重更高);
- 相似度阈值过滤:当最高相似度低于阈值时,标记为“未知类别”,避免错误分类。
方法二:有监督分类器训练(大样本场景)
当有充足标注数据(如每个类别数百条以上)时,将Embedding向量作为特征输入机器学习模型,训练专门的分类器,可获得更高准确率。
核心流程
- 划分训练集与测试集;
- 选择分类模型(如逻辑回归、SVM、随机森林);
- 训练模型并评估性能;
- 用模型预测新文本。
关键代码实现
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.metrics import classification_report
# 1. 准备数据(特征X为Embedding向量,标签y为文本类别)
X = np.array(df["embedding"].tolist()) # 特征:Embedding向量
y = df["label"] # 标签:文本类别
# 2. 标签编码(文本→数字)
label_encoder = LabelEncoder()
y_encoded = label_encoder.fit_transform(y)
# 3. 划分训练集和测试集(8:2)
X_train, X_test, y_train, y_test = train_test_split(
X, y_encoded, test_size=0.2, random_state=42
)
# 4. 训练分类器(对比两种模型)
# 模型1:逻辑回归(速度快,适合高维数据)
clf_lr = LogisticRegression(max_iter=1000)
clf_lr.fit(X_train, y_train)
# 模型2:SVM(非线性分类能力强)
clf_svm = SVC(kernel="linear", probability=True)
clf_svm.fit(X_train, y_train)
# 5. 评估性能
print("逻辑回归分类报告:")
print(classification_report(
y_test,
clf_lr.predict(X_test),
target_names=label_encoder.classes_
))
print("\nSVM分类报告:")
print(classification_report(
y_test,
clf_svm.predict(X_test),
target_names=label_encoder.classes_
))
# 6. 预测新文本
new_texts = ["蓝牙耳机续航时间长", "这本历史书很有趣"]
new_embeddings = model.encode(new_texts)
# 用逻辑回归预测
preds = clf_lr.predict(new_embeddings)
pred_labels = label_encoder.inverse_transform(preds)
print("\n新文本预测:")
for text, label in zip(new_texts, pred_labels):
print(f"{text} → {label}")
模型选择建议
| 模型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 逻辑回归 | 训练快,可解释性强 | 非线性拟合能力弱 | 高维数据、大规模样本 |
| SVM | 高维空间表现好,适合小样本 | 大规模数据训练慢 | 中小规模、复杂分类边界 |
| 随机森林 | 抗过拟合,处理非线性 | 高维数据效率低 | 特征维度低的场景 |
| XGBoost | 精度高,鲁棒性强 | 调参复杂 | 高精度要求的任务 |
实战结果:在38万条新闻分类任务中,逻辑回归准确率达86%(训练时间4分钟),SVM准确率85%(训练时间12分钟),随机森林84%(训练时间10分钟)。
五、模型评估:读懂关键指标
分类模型的性能不能仅靠“准确率”判断,需结合多个指标全面评估,尤其是在数据不平衡场景(如某类别样本占比90%)。
核心指标解析
| 指标 | 公式 | 含义 | 业务意义 |
|---|---|---|---|
| 准确率(Precision) | TP / (TP + FP) | 预测为正的样本中,实际为正的比例 | 模型“不乱猜”的能力(如垃圾邮件分类中,避免正常邮件被误判) |
| 召回率(Recall) | TP / (TP + FN) | 实际为正的样本中,被预测为正的比例 | 模型“不漏掉”的能力(如诈骗短信识别中,尽可能捕捉所有诈骗信息) |
| F1分数 | 2×(P×R)/(P+R) | 准确率与召回率的调和平均 | 综合评估模型性能(两者需平衡时) |
| 宏平均(Macro Avg) | 各类别指标的平均值 | 平等对待所有类别 | 数据不平衡场景(如少数类别的表现同样重要) |
| 微平均(Micro Avg) | 全局TP、FP、FN计算的指标 | 受多数类影响大 | 数据均衡场景 |
示例:在垃圾邮件分类中,若 Precision=95% 表示“预测为垃圾邮件的邮件中95%确实是垃圾邮件”;Recall=90% 表示“实际垃圾邮件中90%被成功识别”。
可视化评估:混淆矩阵
混淆矩阵可直观展示模型对每个类别的预测情况:
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
# 计算混淆矩阵
y_pred = clf_lr.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
# 可视化
plt.figure(figsize=(8, 6))
sns.heatmap(
cm,
annot=True,
fmt="d",
cmap="Blues",
xticklabels=label_encoder.classes_,
yticklabels=label_encoder.classes_
)
plt.xlabel("预测类别")
plt.ylabel("实际类别")
plt.title("混淆矩阵")
plt.show()
六、优化技巧:从80%到90%的准确率提升之路
即使掌握了基础方法,仍需针对性优化才能达到更高性能。以下是经过实战验证的有效技巧:
6.1 Embedding优化
- 模型融合:将多个Embedding模型的向量拼接(如OpenAI向量+M3E向量),提供更丰富的语义信息;
- 领域微调:用领域内文本微调Embedding模型(如法律文本用法律语料微调),代码示例:
# 用sentence-transformers微调模型(简化版) from sentence_transformers import InputExample, losses from torch.utils.data import DataLoader # 准备微调数据(句子对+相似度标签) examples = [ InputExample(texts=["手机拍照好", "这款手机摄像头很棒"], label=1.0), # 相似 InputExample(texts=["手机拍照好", "餐厅环境不错"], label=0.0) # 不相似 ] train_dataloader = DataLoader(examples, shuffle=True, batch_size=2) # 定义损失函数 train_loss = losses.CosineSimilarityLoss(model) # 微调模型 model.fit( train_objectives=[(train_dataloader, train_loss)], epochs=3, warmup_steps=10 )
6.2 分类器优化
- 超参数调优:用网格搜索找到最佳参数:
from sklearn.model_selection import GridSearchCV param_grid = { "C": [0.1, 1, 10], # 正则化强度 "kernel": ["linear", "rbf"] # 核函数 } grid_search = GridSearchCV(SVC(), param_grid, cv=3) grid_search.fit(X_train, y_train) print("最佳参数:", grid_search.best_params_) - 集成学习:组合多个模型的预测结果(如逻辑回归+SVM+随机森林),用投票法提升稳定性。
6.3 数据增强
- 对文本进行同义替换、回译(如中文→英文→中文)生成新样本,扩充训练数据:
# 简单同义替换示例 import random synonyms = { "好": ["优秀", "出色", "棒"], "差": ["糟糕", "低劣", "不行"] } def augment_text(text): for word, syns in synonyms.items(): if word in text: text = text.replace(word, random.choice(syns)) return text
七、实战案例:今日头条新闻分类(准确率86%+)
项目背景
需将今日头条的新闻标题分为“科技”“娱乐”“体育”“财经”“健康”5个类别,数据量38万条,标注样本充足。
技术方案
- Embedding生成:用OpenAI
text-embedding-ada-002生成1536维向量; - 数据处理:过滤超长文本(保留≤8000 tokens),用Parquet存储;
- 模型选择:逻辑回归(速度快,适合大规模数据);
- 评估结果:
- 整体准确率86%,F1分数85.7%;
- 科技、财经类表现最佳(F1>88%),娱乐类因边界模糊稍低(F1=82%)。
关键优化点
- 对娱乐类样本进行数据增强(同义替换、句式变换),提升召回率;
- 用宏平均指标监控少数类(如健康类)的表现,避免被多数类掩盖问题。
八、常见问题与解决方案
| 问题 | 原因 | 解决方案 |
|---|---|---|
| Embedding生成速度慢 | 模型维度高、文本量大 | 用小维度模型(如384维);批量处理;GPU加速(Sentence-Transformers支持) |
| 分类准确率低 | 样本量不足、类别混淆 | 增加标注数据;数据增强;微调Embedding模型;检查类别定义是否清晰 |
| 类别不平衡 | 某类别样本占比过高 | 过采样少数类(SMOTE算法);欠采样多数类;分类器中设置class_weight='balanced' |
| 语义相似文本被分错类 | Embedding未捕捉细微差异 | 换用更高维度模型;用领域微调模型;增加类别代表向量的信息量 |
九、总结与展望
Embedding技术彻底改变了文本分类的范式——从依赖人工特征工程到自动捕捉语义信息,让非NLP专家也能实现高精度分类。本文系统介绍了从OpenAI API到开源Sentence-Transformers的全流程,涵盖数据处理、两种分类方法、模型优化与实战案例,核心要点包括:
- 工具选择:快速开发用OpenAI API,本地部署用Sentence-Transformers;
- 方法选择:少数据用相似度分类,多数据用有监督模型;
- 核心技巧:重视数据清洗、模型融合与超参数调优。
未来,随着大语言模型(LLM)的发展,Embedding与LLM的结合(如用LLM生成更精准的向量)将进一步提升分类性能。掌握本文方法,你已能应对90%以上的文本分类场景,快去动手实践吧!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











