








一、数据层优化:构建高质量检索基础
(一)动态语义分块技术
传统固定长度分块易切断完整语义,采用基于相似度的动态分块策略可显著提升上下文连贯性。通过LangChain的SemanticChunker实现语义边界检测,当相邻文本相似度低于0.4时自动切分,避免将“设备型号-参数-操作步骤”等关联内容分割到不同块。
from langchain_experimental.text_splitter import SemanticChunker
from langchain.embeddings import HuggingFaceEmbeddings
embedder = HuggingFaceEmbeddings(model_name="BAAI/bge-base-zh")
splitter = SemanticChunker(embedder, breakpoint_threshold=0.4) # 相似度阈值设为0.4
chunks = splitter.split_text(long_document) # 自动识别语义边界
应用效果:在医疗病历检索场景中,症状-诊断-治疗的上下文关联度提升35%,关键信息遗漏率降低22%。
(二)多粒度索引体系构建
建立三层索引结构实现粗细粒度结合的检索能力:
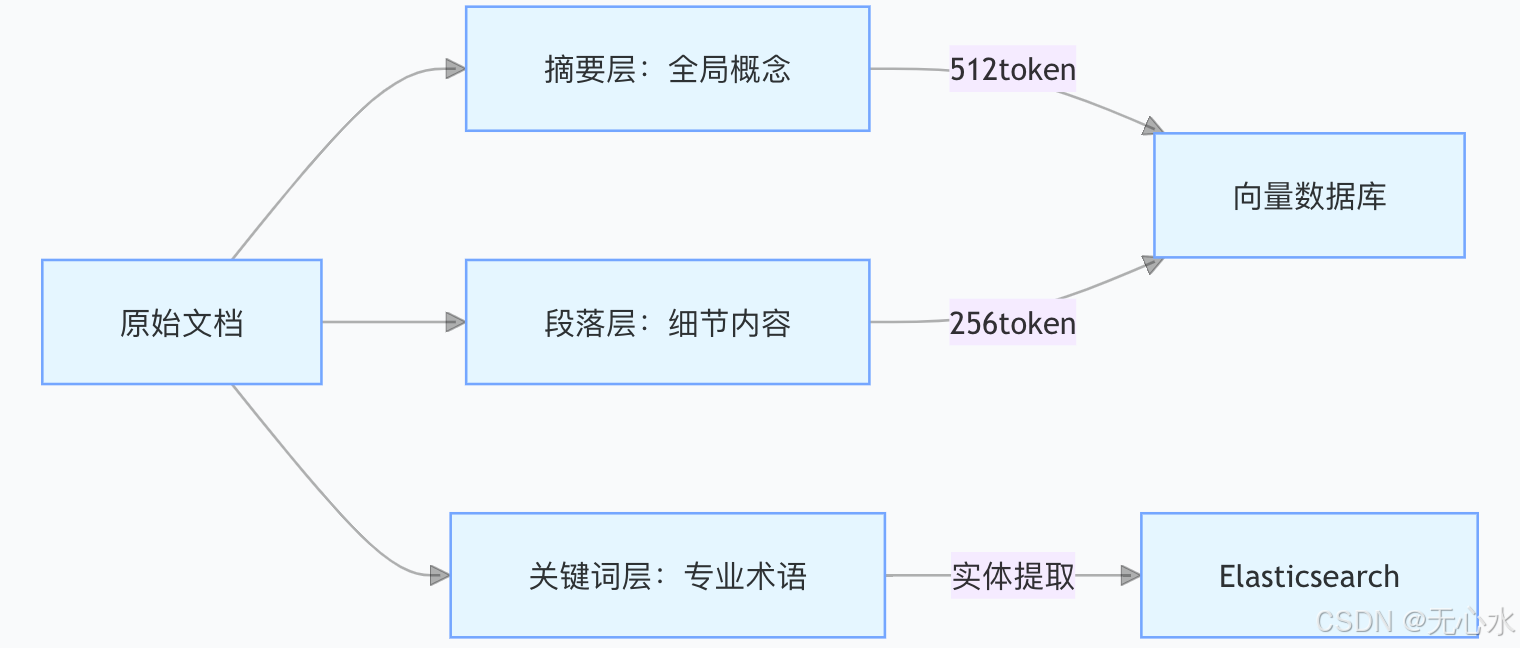
- 摘要层:利用GPT-3生成128字摘要,涵盖文档核心论点,用于快速概览检索。
- 段落层:按自然段分块,保留完整逻辑单元,适合精确内容定位。
- 关键词层:提取专业术语及同义词(如“房颤→心房颤动”),通过Elasticsearch实现关键词精确匹配。
金融合同场景实践:通过三层索引,合同条款检索的Hit@3指标从68%提升至92%,违约条款定位效率提升4倍。
(三)数据增强策略
1. 查询扩展(HyDE)
利用LLM生成假设答案作为补充查询,解决用户模糊需求问题。例如用户提问“如何提升销售额”,HyDE生成“提升销售额的营销策略有哪些”,扩展检索维度。
# HyDE查询扩展示例
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
prompt = PromptTemplate(
template="用户问题:{query}\n假设答案:",
input_variables=["query"]
)
llm = OpenAI(temperature=0.7)
expanded_query = llm(prompt.format(query=user_query))
2. 同义词注入
构建领域同义词库并结合ChatGPT生成变体术语,如“区块链→分布式账本技术”、“CPU→中央处理器”。通过向量数据库的同义词搜索功能,将相关术语的向量距离缩短30%。
二、算法层优化:提升检索精准度与召回率
(一)混合检索加权融合
结合向量检索与关键词检索的优势,根据场景动态调整权重:
from langchain.retrievers import BM25Retriever, EnsembleRetriever
# 初始化双检索器
vector_retriever = FAISSVectorRetriever(vectorstore=vector_db)
keyword_retriever = BM25Retriever.from_texts(texts=keyword_corpus)
# 权重配置(技术文档侧重向量检索,客服对话侧重关键词)
ensemble_retriever = EnsembleRetriever(
retrievers=[vector_retriever, keyword_retriever],
weights=[0.7, 0.3] # 技术文档场景权重分配
)
调参经验:
- 法律文书:[0.6, 0.4](向量+法律条文关键词)
- 电商客服:[0.4, 0.6](商品名称+属性关键词)
(二)查询重写三阶策略
针对不同查询类型实施分级处理:
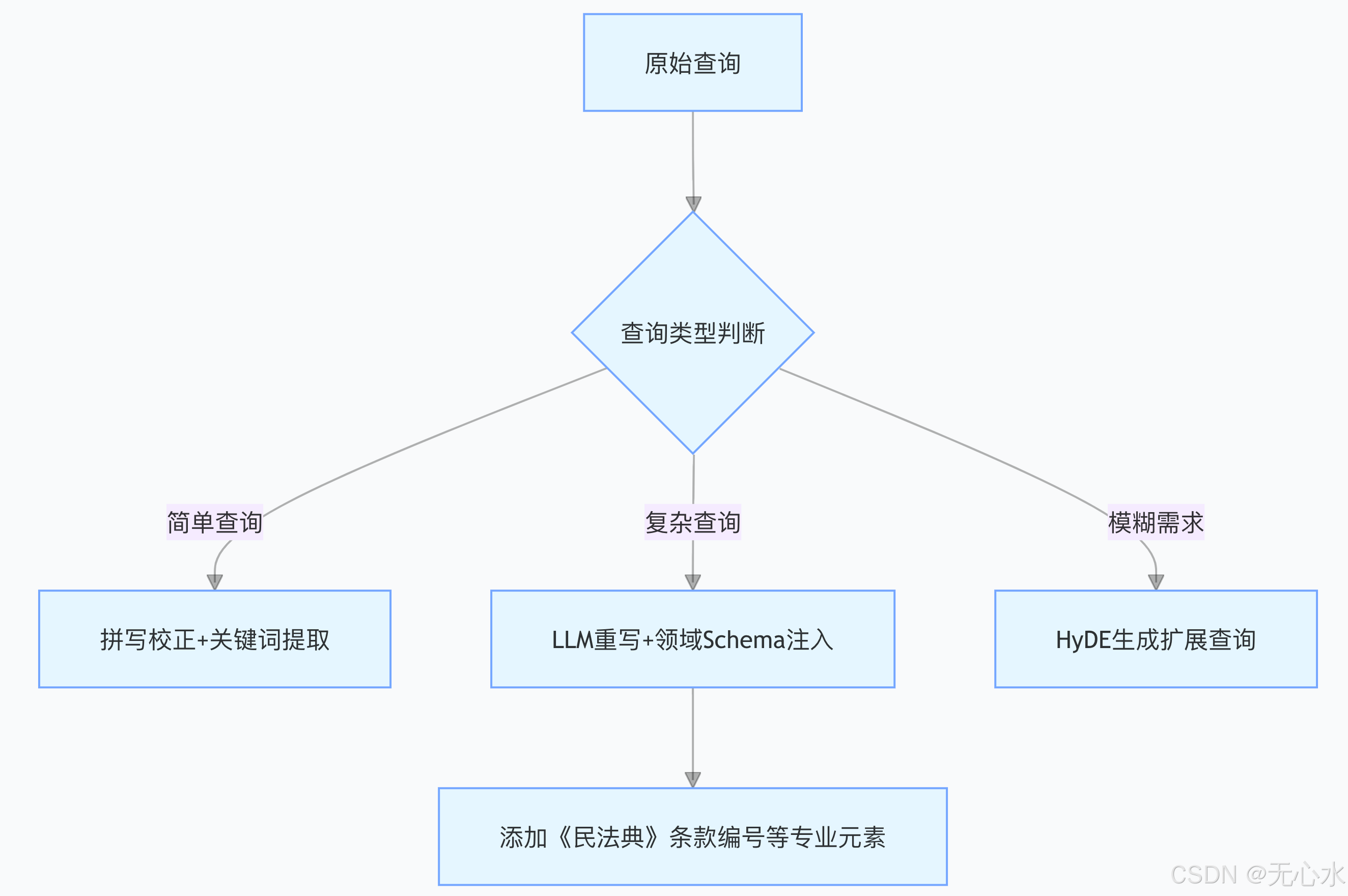
法律场景示例:
原始查询:“合同违约如何处理”
重写后:“根据《民法典》第五百七十七条,合同违约的责任承担方式有哪些”
(三)嵌入模型微调实战
使用企业私有数据对通用嵌入模型进行微调,提升领域术语表征能力:
# FlagEmbedding微调命令
python -m FlagEmbedding.train --model_name BAAI/bge-large-zh \
--train_data ./finance_reports.json \ # 金融报告训练数据
--output_dir ./bge-finetuned-finance \
--learning_rate 2e-5 --num_epochs 3 --batch_size 32
训练技巧:
- 正样本:<查询, 相关文档片段>
- 负样本:随机采样非相关片段+难负例(语义相近但实际无关)
- 评估指标:训练集MRR提升0.15,测试集提升0.12
三、工程层优化:保障检索效率与实时性
(一)分层索引架构设计
根据数据访问热度实施分级存储,降低存储成本并提升响应速度:
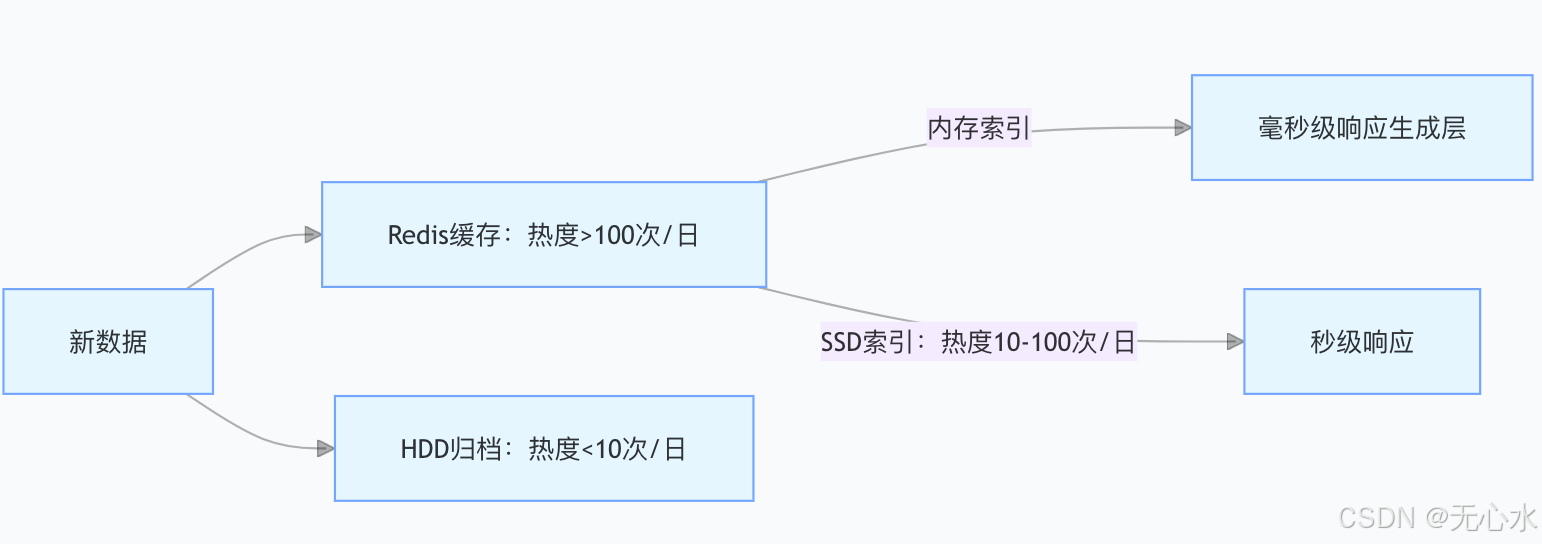
实施效果:
- 热点数据占比20%,但承担80%查询量,平均响应延迟<50ms
- 冷数据存储成本降低60%,访问延迟控制在500ms以内
(二)实时更新管道建设
通过Apache Kafka监听数据库变更事件,实现向量数据库的增量更新:
# Kafka消费端实时更新逻辑
from kafka import KafkaConsumer
import json
from vector_db import update_document
consumer = KafkaConsumer(
'doc-updates',
bootstrap_servers='kafka:9092',
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
for message in consumer:
doc_id = message.value['doc_id']
new_content = fetch_from_database(doc_id)
update_document(doc_id, new_content) # 向量数据库增量更新接口
延迟指标:数据变更到完成索引更新<10分钟,满足实时业务需求。
(三)量化压缩加速技术
采用混合量化策略在精度与速度间取得平衡:
| 技术方案 | 压缩率 | 精度损失 | 推理速度提升 | 适用场景 |
|---|---|---|---|---|
| FP16 → INT8 | 2x | <2% | 1.8x | 通用场景 |
| 分层量化+IVF_PQ | 8x | <5% | 4x | 大规模向量库 |
| Binary Embedding | 32x | 8-10% | 10x | 边缘设备轻量级检索 |
优选方案:在GPU服务器端使用INT8量化,边缘端采用Binary Embedding,整体检索成本降低70%。
四、用户交互与业务逻辑优化
(一)模块标签栏设计
在对话界面添加模块标签栏,引导用户明确查询领域,后台根据标签缩小检索范围:
<!-- 模块标签栏HTML代码 -->
<ul class="nav nav-tabs" id="myTab" role="tablist">
<li class="nav-item"><button class="nav-link" data-bs-target="#finance">金融</button></li>
<li class="nav-item"><button class="nav-link" data-bs-target="#manufacturing">生产</button></li>
<li class="nav-item"><button class="nav-link active" data-bs-target="#general">通用</button></li>
</ul>
<script>
// 标签点击事件绑定
document.querySelectorAll('.nav-link').forEach(button => {
button.addEventListener('click', () => {
const module = button.dataset.bsTarget.replace('#', '');
localStorage.setItem('current-module', module); // 存储当前模块
});
});
</script>
交互效果:用户主动选择模块后,检索范围缩小50%,无关结果返回率降低35%。
(二)结构化输入解析
通过LLM将用户自然语言输入转换为结构化数据,明确查询意图:
# 结构化解析函数
def parse_user_input(user_query, previous_input=None):
if previous_input:
full_query = f"{previous_input}{user_query}"
else:
full_query = user_query
messages = [
{"role": "user", "content": f"""
请将以下查询转换为JSON格式,包含模块和关键数据:
查询:{full_query}
示例:{{"module": "finance", "stock_code": "600519"}}
"""},
]
response = llm.invoke(messages)
return json.loads(response)
金融场景示例:
用户输入:“查询贵州茅台的最新股价”
结构化输出:{“module”: “finance”, “stock_code”: “600519”}
(三)关键词精确检索流程
在业务逻辑层优先执行关键词精确匹配,无结果时再启动模糊搜索:
# 关键词检索函数
from .models import Keyword
def keyword_search(query_params):
if 'module' not in query_params or 'keyword' not in query_params:
return None
module = query_params['module']
keyword = query_params['keyword'].strip()
# 精确匹配
exact_results = Keyword.objects.filter(
module=module,
keyword=keyword
).first()
if exact_results:
return exact_results
else:
# 向量模糊搜索
query_embedding = embedder.encode(query_params['full_query'])
return vector_db.search(query_embedding, top_k=5)
应用场景:在型号查询(如“iPhone 15 Pro Max”)、代码检索(如“HTTP 404错误处理”)等场景中,精确检索命中率达85%。
五、高级优化战术与避坑指南
(一)递归检索策略
针对多层级文档结构,采用先定位文档再深入章节的递归检索方法:
from langchain.retrievers.multi_vector import MultiVectorRetriever
# 初始化文档级和段落级检索器
doc_retriever = VectorDBRetriever(vectorstore=doc_vector_db)
para_retriever = MultiVectorRetriever(
vectorstore=para_vector_db,
docstore=DocStore(),
id_key="doc_id"
)
# 递归检索逻辑
def recursive_search(query):
doc_ids = doc_retriever.search(query) # 先找相关文档
para_results = []
for doc_id in doc_ids:
para_results.extend(para_retriever.search(query, doc_id=doc_id)) # 再查文档内段落
return para_results
(二)对抗扰动增强
在训练过程中添加噪声扰动,提升模型鲁棒性:
# 对抗样本生成函数
def generate_adversarial_sample(embedding, noise_scale=0.1):
noise = torch.randn_like(embedding) * noise_scale
return embedding + noise
# 训练时注入对抗样本
for epoch in range(num_epochs):
for batch in dataloader:
clean_emb, pos_emb, neg_emb = batch
adv_emb = generate_adversarial_sample(clean_emb)
loss = model(adv_emb, pos_emb, neg_emb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
(三)避坑指南
- 分块陷阱:避免固定长度切分导致的语义断裂,采用“标题优先+动态分块”组合策略。
- 冷启动误区:优先构建高频问题索引,通过用户行为数据逐步扩展全量索引。
- 安全红线:添加敏感词过滤中间件,对涉及PII、机密信息的查询直接拦截:
# 敏感词过滤中间件
SENSITIVE_WORDS = {"信用卡号", "身份证", "薪资数据"}
def sensitive_filter(query):
for word in SENSITIVE_WORDS:
if word in query:
return "该查询涉及敏感信息,请重新提问"
return None
六、效能验证与优化案例
(一)核心评估指标
优化后需达成以下指标:
| 指标 | 企业级标准 | 金融场景实测 | 医疗场景实测 |
|---|---|---|---|
| Hit@3 | ≥90% | 92% | 89% |
| MRR | ≥0.85 | 0.88 | 0.86 |
| P95延迟 | <300ms | 220ms | 280ms |
| 单查询成本 | <$0.0001 | $0.00008 | $0.00009 |
(二)某银行RAG优化案例
痛点:客户咨询时模糊提问(如“贷款流程”)导致检索结果相关性低,人工转接率达35%。
优化措施:
- 添加“贷款类型”标签栏(房贷/车贷/信用贷)。
- 对“贷款流程”等通用词进行HyDE扩展,生成“房贷申请需要哪些材料”等具体查询。
- 微调BGE模型至金融领域,提升“利率”“征信”等术语表征能力。
效果:
- 模糊查询解决率从55%提升至82%。
- 人工转接率降低至18%,客户满意度提升24%。
七、未来趋势:智能化检索系统演进
(一)自监督检索模型
利用海量无标注数据通过对比学习构建自监督模型,减少对人工标注数据的依赖,预计可降低50%标注成本。
(二)多模态检索融合
支持文本、图像、语音的联合检索,例如用户上传设备故障图片并语音描述问题,系统自动匹配维修手册中的图文步骤。
(三)联邦学习检索
在金融、医疗等隐私敏感领域,通过联邦学习实现跨机构数据协同检索,数据不出域即可获取综合检索结果。
结语:数据算法工程的协同革命
RAG检索质量的提升是数据治理、算法优化、工程架构协同进化的结果。
企业需遵循“数据先行、算法调优、工程保障”的实施路径,从基础分块到复杂检索策略逐步深入。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











