



在数字化转型纵深推进的背景下,数据作为新型生产要素已成为驱动企业战略决策、科研创新及智能化运营的核心战略资产。数据治理价值链中的处理环节作为关键价值节点,其本质是通过系统化处理流程将原始观测数据转化为结构化知识产物,以支撑预测性分析、规范性决策及实时业务响应等复杂应用场景。ETL作为经典的数据集成架构,持续在数据工程领域发挥着基础性作用,特别是在构建企业级数据仓库、多模态数据分析平台及OLAP分析系统等场景中,其多阶段处理范式为结构化数据治理提供了标准化方法论。本次我们通过ETLCloud工具,演示ETL中数据处理的方式。
—、 常见的数据处理方法
-
数据清洗:数据清洗是数据处理的首要步骤,旨在去除数据中的噪声和错误,包括消除重复记录、纠正错误数据、填补缺失值等。例如,电商平台可能因系统故障导致部分用户订单信息重复记录,通过数据清洗可精准去除重复项,确保数据的唯一性和准确性。
-
数据转换:数据转换涉及将数据从一种格式或结构转换为另一种格式或结构,以满足特定业务需求。例如,将日期格式统一为“YYYY-MM-DD”、将文本型数字转换为数值型等。在金融数据分析中,将不同来源的财务数据转换为统一的标准化格式,便于后续的财务报表整合和分析。
-
数据集成:数据集成是将来自多个不同数据源的数据合并到一个统一的存储中,实现数据的集中管理和共享。例如,企业将来自各个分支机构的销售数据、库存数据等集成到一个数据仓库中,为全面的业务分析提供完整数据基础。
-
数据去重:数据去重顾名思义,是去除数据中的重复记录,避免数据冗余和分析误差。例如,在市场调研数据中,同一受访者的重复回答可能导致分析结果偏离实际,通过数据去重可提高数据质量。
-
数据加密:数据加密是对敏感数据进行加密处理,以确保数据的安全性和保密性。在医疗行业,患者病历等敏感信息通过加密技术进行存储和传输,防止数据泄露风险。
二、ETL中的数据处理案例
1.案例示例图

2.准备数据源:创建MySQL数据源
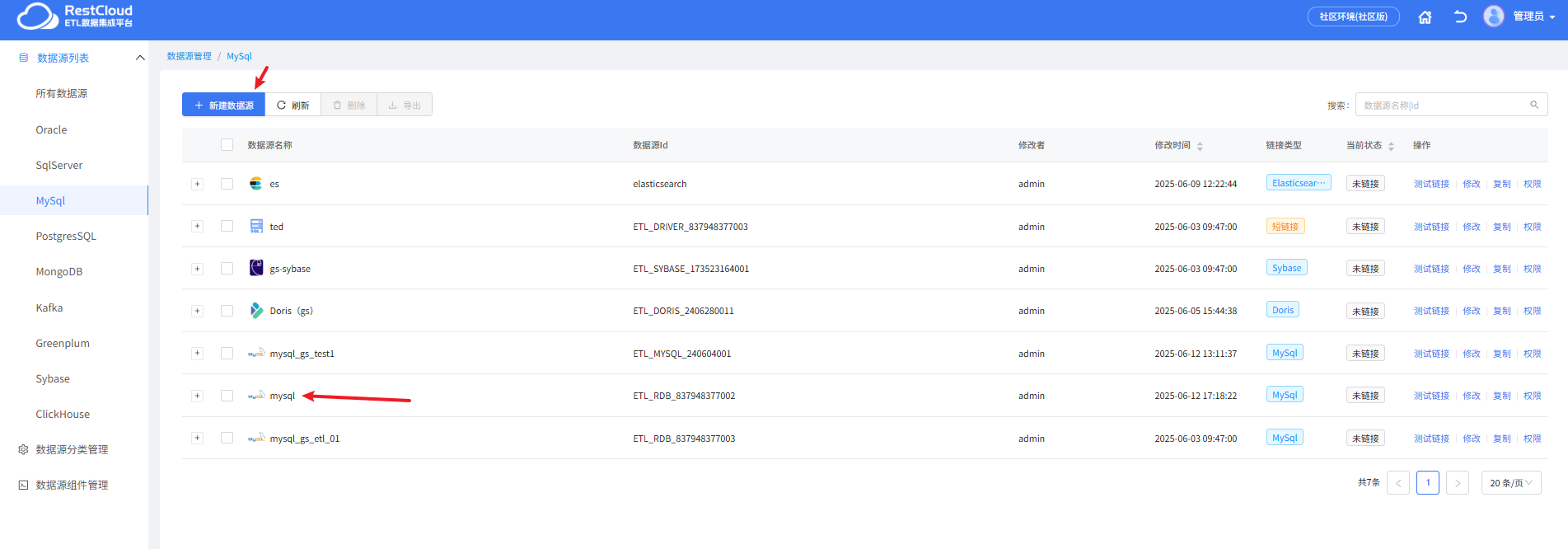
3.创建离线同步流程

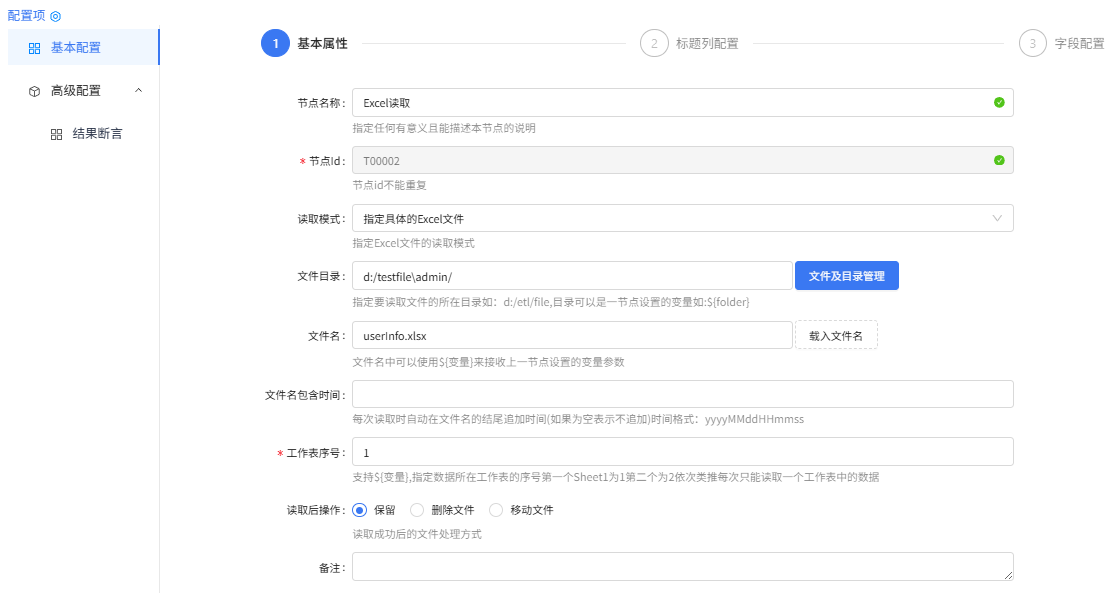
Excel读取组件配置
基本属性配置
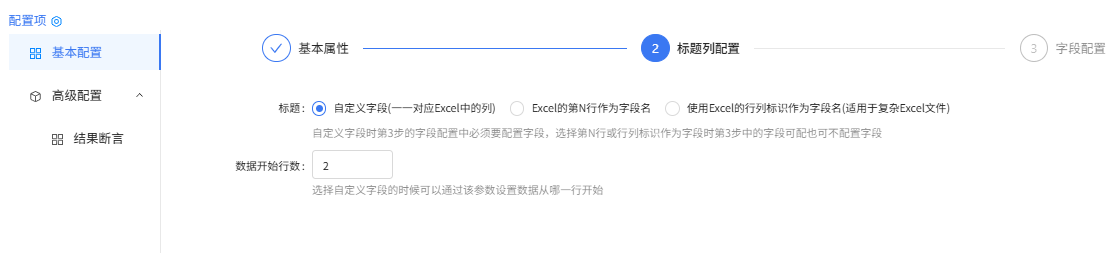
标题列配置
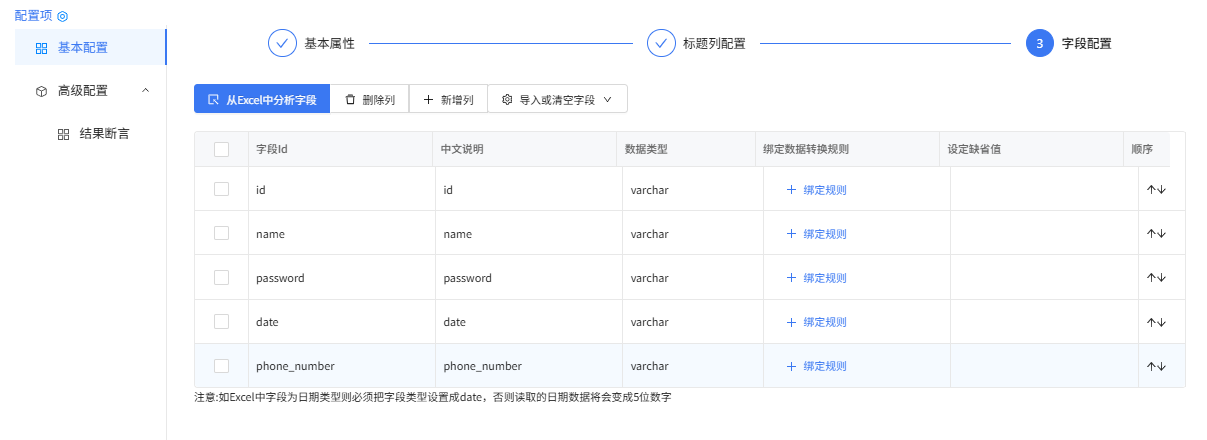
字段配置
库表输入组件配置:
基本属性配置
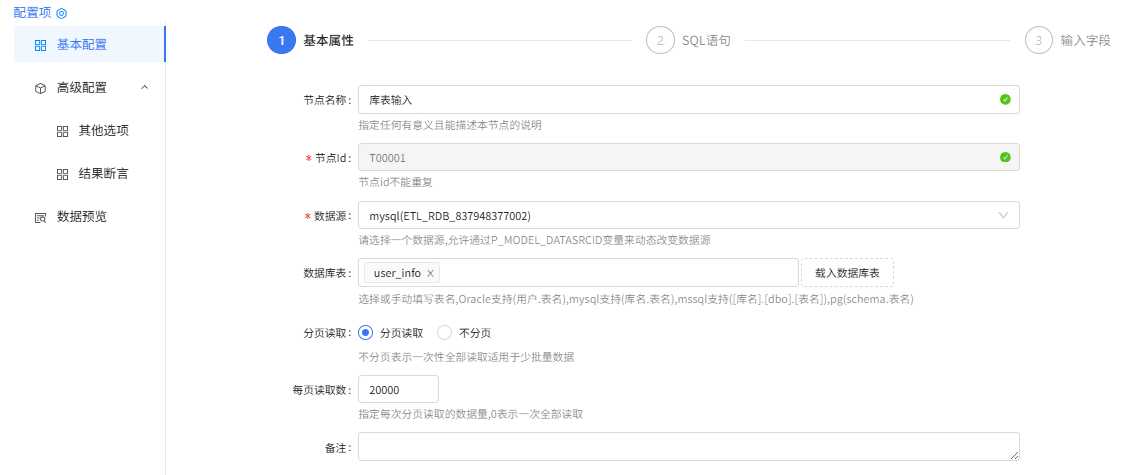
SQL语句配置
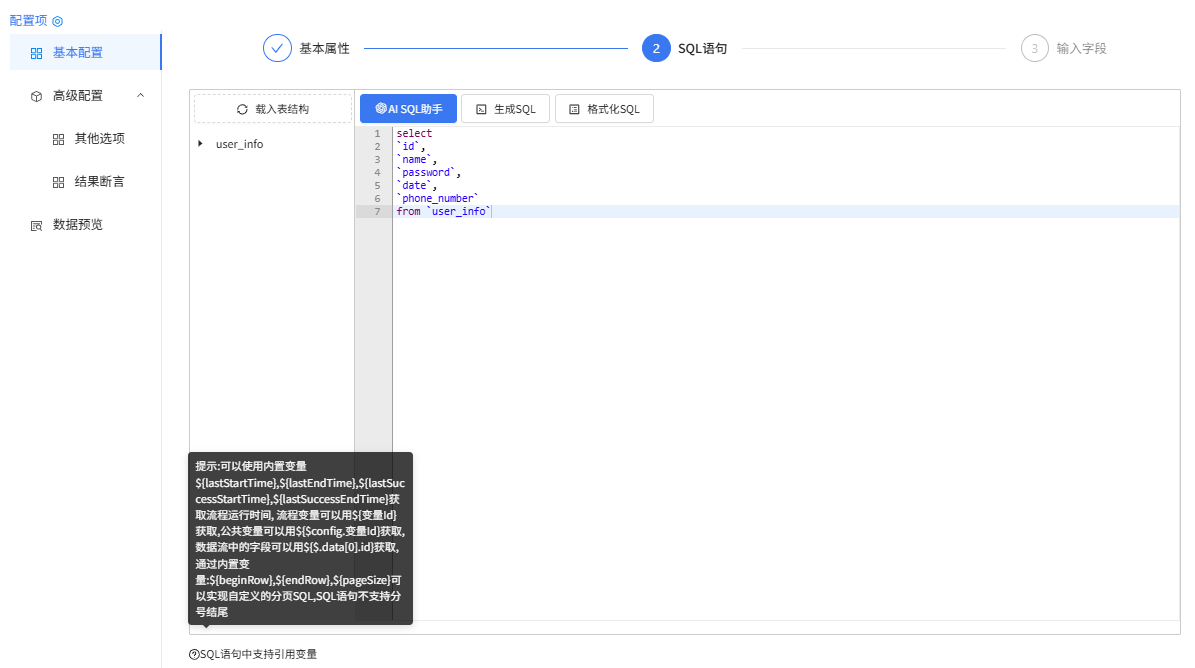
输入字段配置
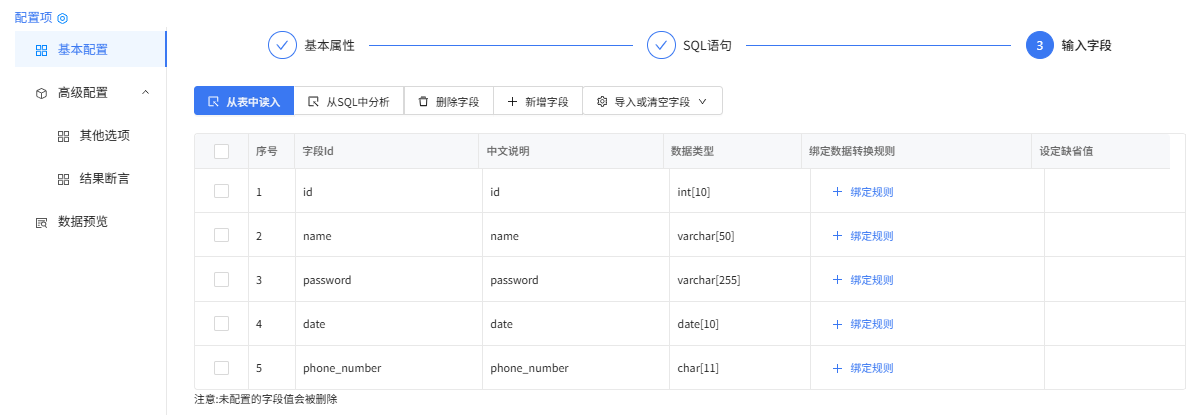
多流Union合并配置:
基本属性配置
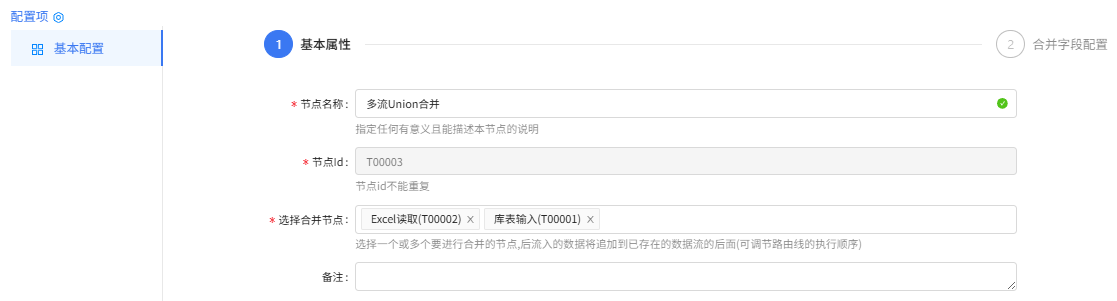
合并字段配置
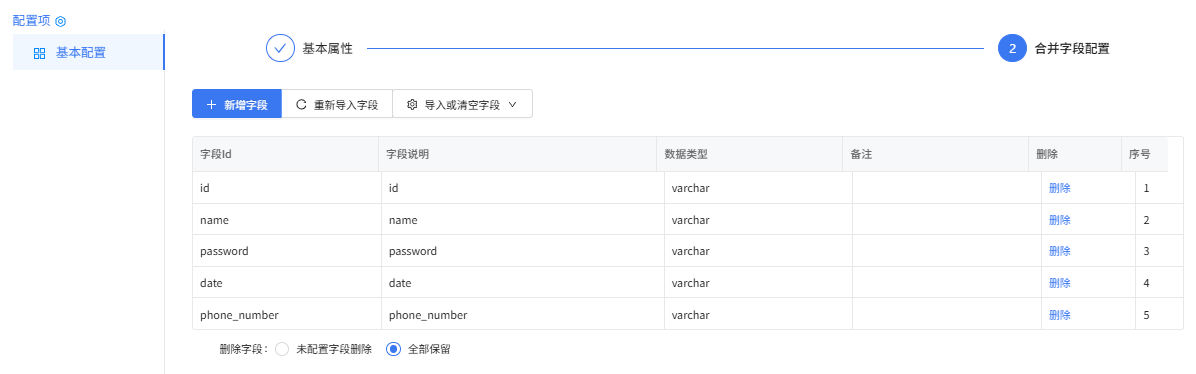
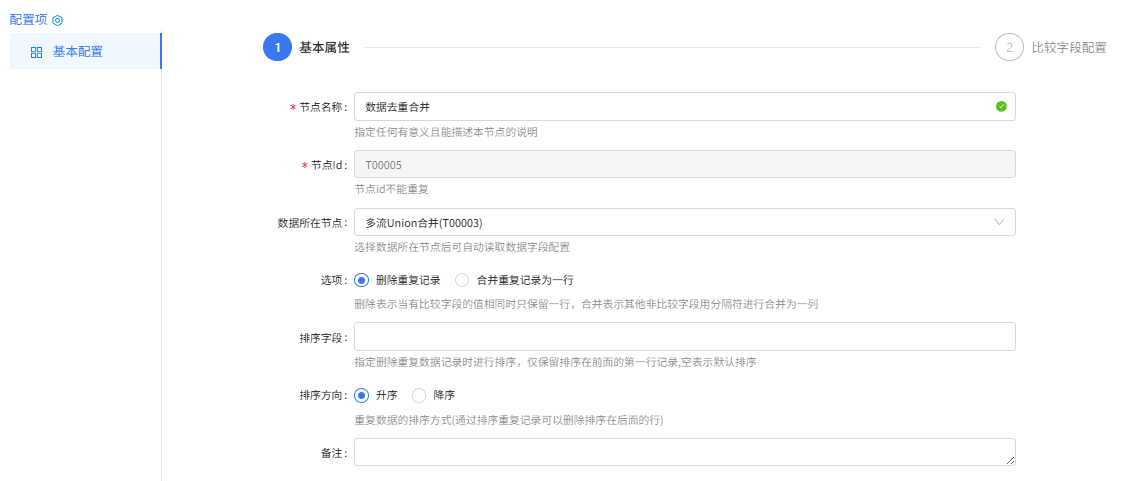
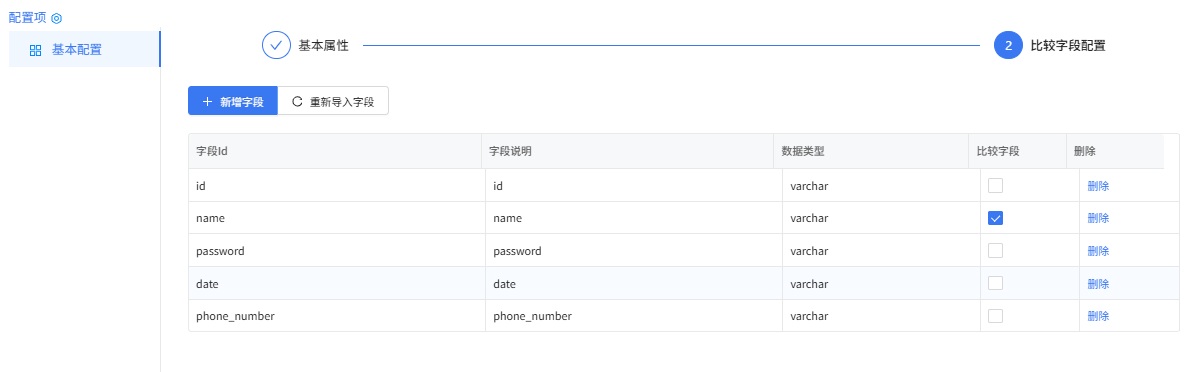
数据去重合并组件配置:
基本属性
比较字段配置
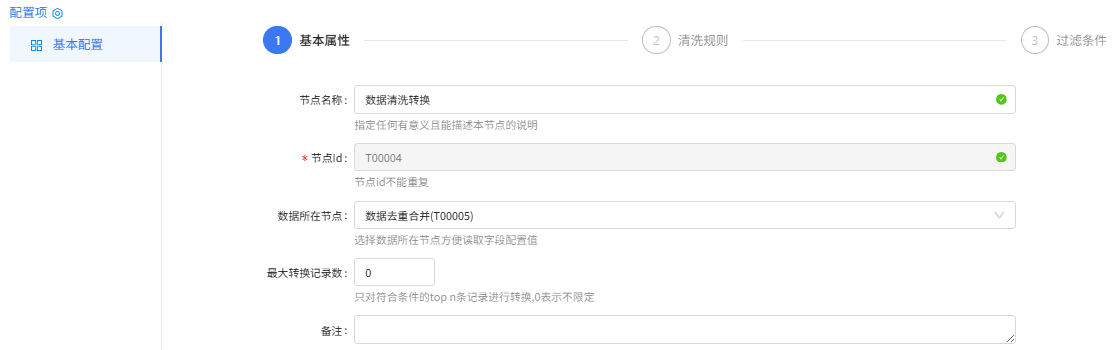
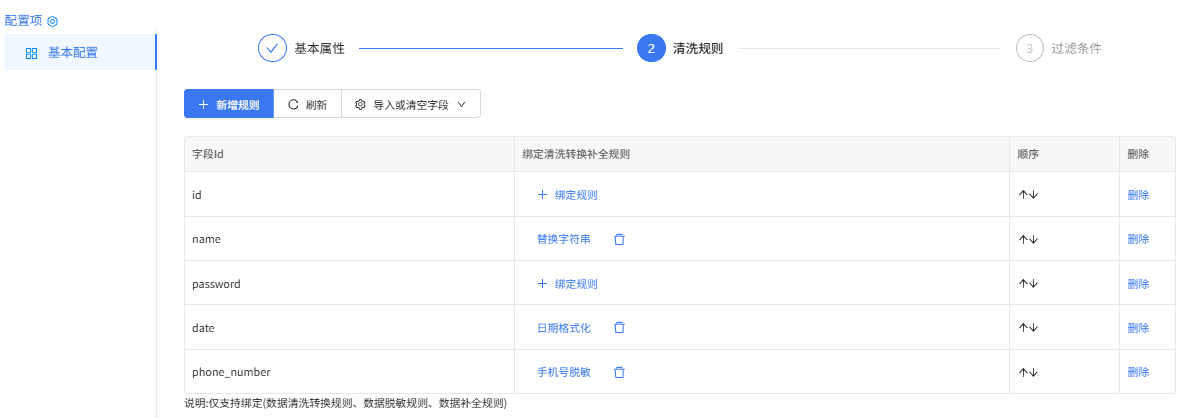
数据清洗转换组件配置:
基本属性
清洗规则配置
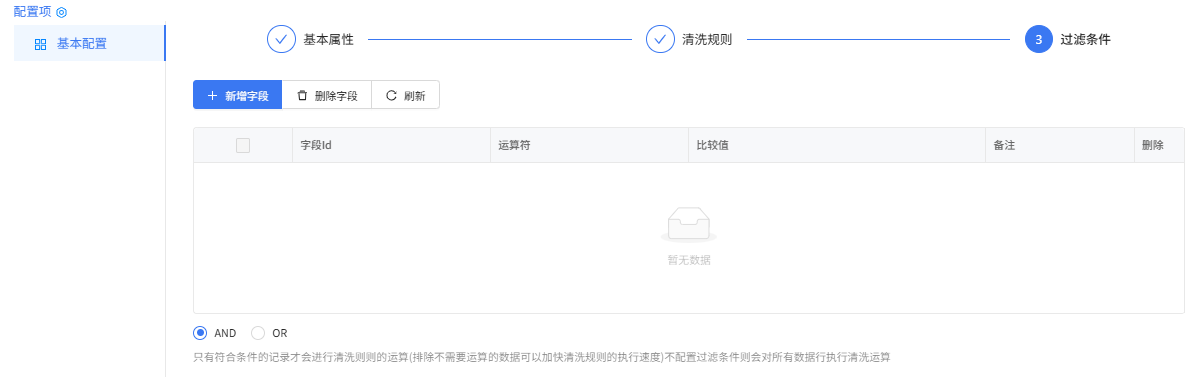
过滤条件配置
数据加解密组件配置:
基本属性
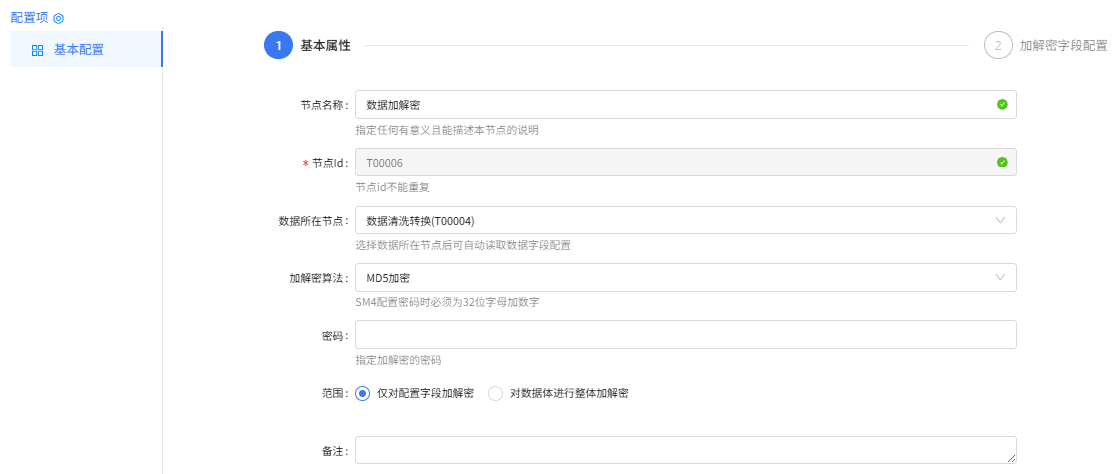
加解密字段配置

库表输出组件配置:
基本属性
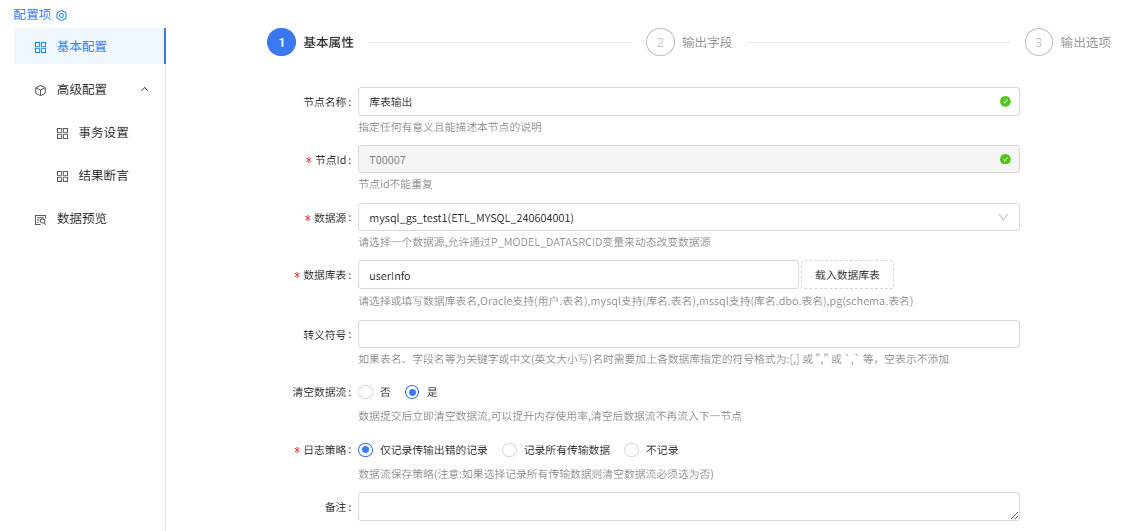
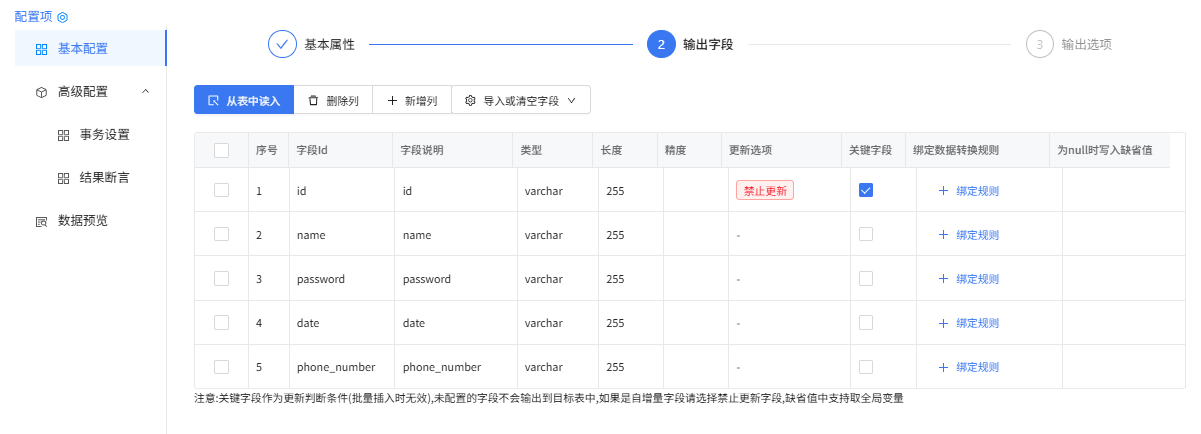
输出字段
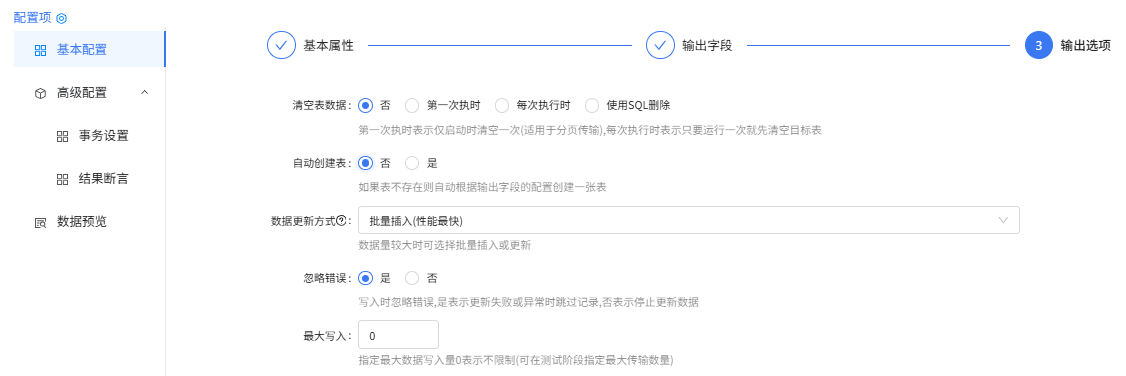
输出选项
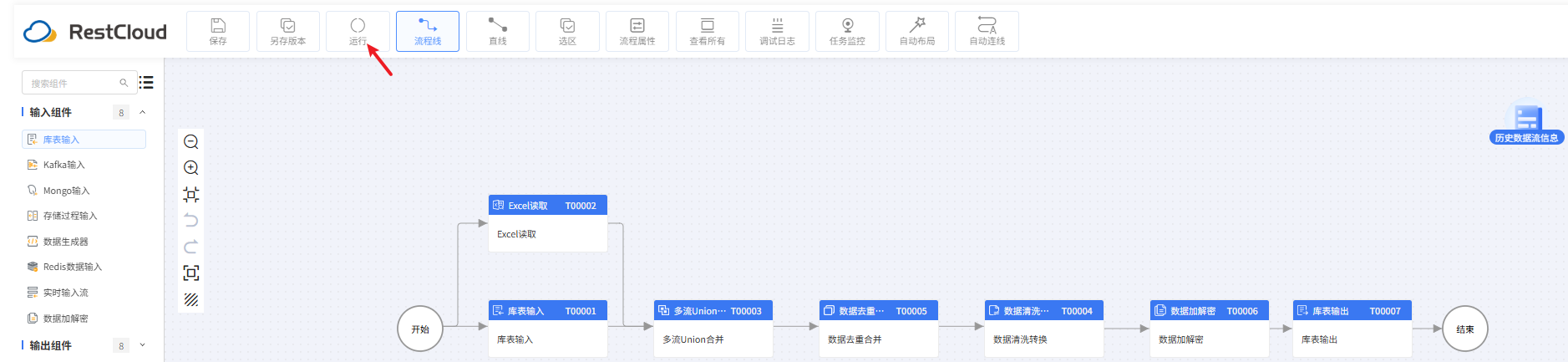
4.运行流程
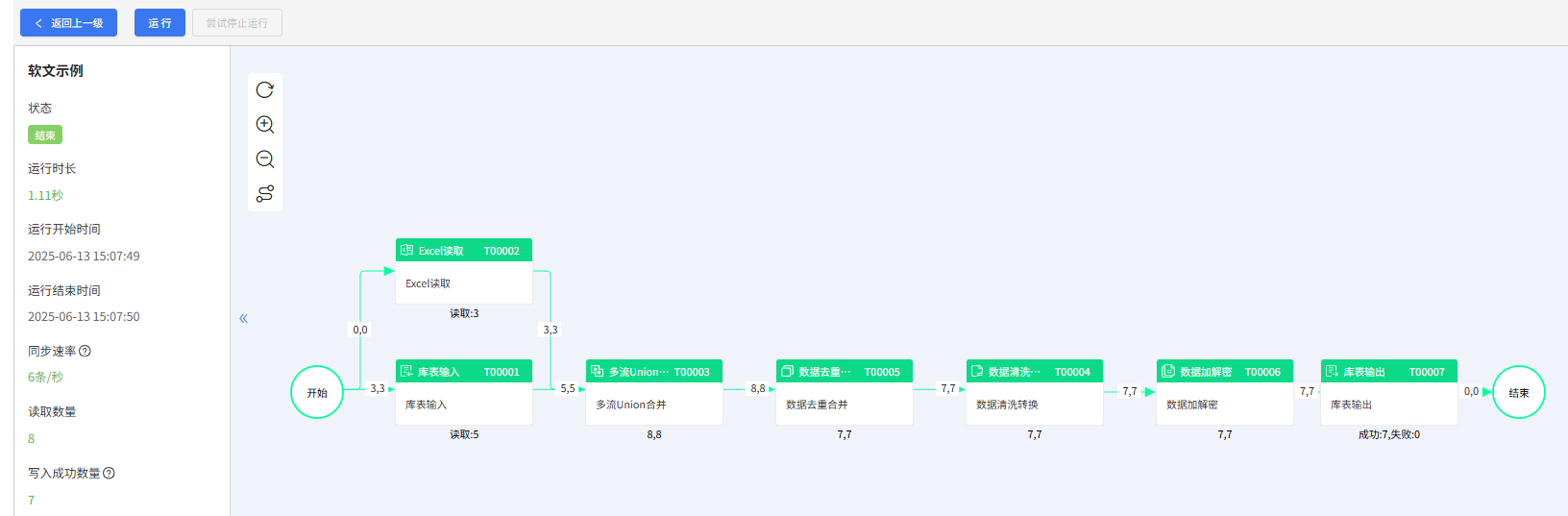
流程监控
查看源数据:excel文件和库表输入的表数据
Excel文件数据

库表输入表数据
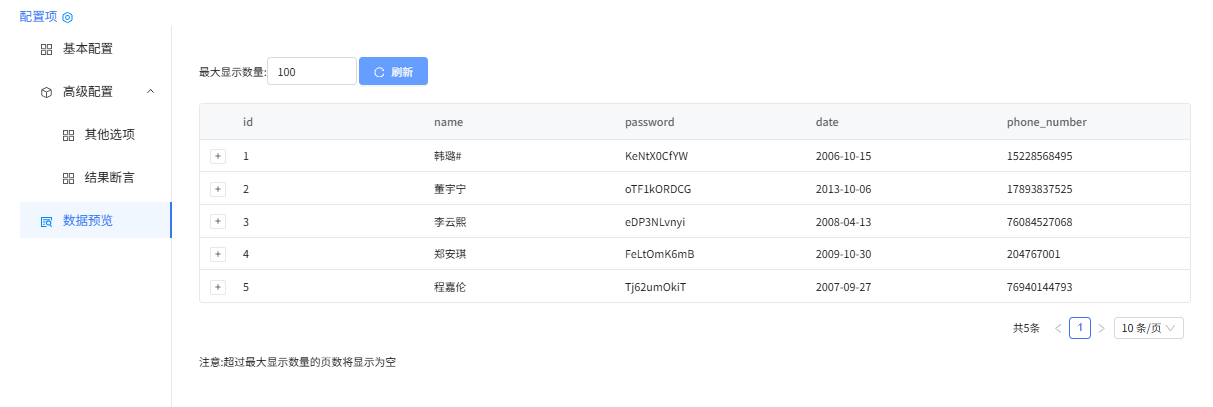
库表输出表数据
三、最后
随着数据量的不断增长和数据复杂性的提升,数据处理方法和工具将不断创新和演进。未来,ETL工具将更加智能化、自动化,能够处理更复杂、更海量的数据,为企业提供更高效、更精准的数据处理解决方案,助力企业在数字化浪潮中脱颖而出。

















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









