



 本文探讨了数据脱敏的概念,介绍了常见的脱敏方法如匿名化、删除和加密等,以及它在法律合规、数据安全和业务需求中的重要性。同时,针对企业实践中遇到的挑战,如系统复杂性和用户影响,提供了ETLCloud中的数据脱敏案例作为参考。
本文探讨了数据脱敏的概念,介绍了常见的脱敏方法如匿名化、删除和加密等,以及它在法律合规、数据安全和业务需求中的重要性。同时,针对企业实践中遇到的挑战,如系统复杂性和用户影响,提供了ETLCloud中的数据脱敏案例作为参考。
数据脱敏是什么?
数据脱敏是在数据处理过程中采用各种技术手段去除或替换敏感信息,以保障个人隐私和敏感信息的安全措施。通常应用于数据共享、数据分析和软件测试等场景,其目的在于减少数据泄露和滥用的风险。
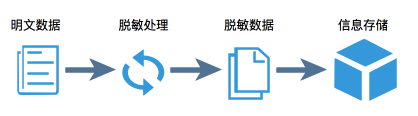
常见的数据脱敏方法包括:
-
匿名化/泛化:通过对数据进行聚合、概括或者模糊处理,例如将具体的数值转换成范围值,以减少数据的精确性,从而保护个人隐私。
-
删除:直接删除数据中的敏感信息,确保敏感字段完全不可见。
-
加密:使用加密算法对数据进行加密处理,只有授权的用户才能解密获取原始信息。
-
替换:用虚拟的、无意义的数据替代真实的敏感信息,例如使用通用的标识符或者随机生成的数据。
-
脱敏工具:利用专门的脱敏工具或软件对数据进行处理,保证操作的规范性和可追溯性。
数据脱敏需求主要来源于以下几个方面?
-
法律合规:随着个人隐私保护法规的不断完善,企业需要遵守相关法律规定,对用户数据进行脱敏处理以确保遵从法律法规,保护用户隐私。
-
数据安全保障:信息安全意识的提高使得企业更加重视数据安全,通过数据脱敏可以有效防止敏感信息泄露,维护数据的机密性和完整性。
-
业务需求:在数据驱动的背景下,企业需要使用真实数据进行分析和开发工作,而数据脱敏可以帮助平衡数据的可用性和安全性,满足业务需求。
-
防范数据泄露:员工操作失误、黑客攻击等威胁都可能导致数据泄露,因此数据脱敏是一种重要的措施,可以最大限度地减少数据泄露风险,保障数据安全。
数据脱敏的出现是由于个人隐私保护法律法规的要求、企业对数据安全的重视、数据驱动决策的需求以及防范数据泄露风险的考量等多方面因素的综合作用。通过数据脱敏,可以在保护用户隐私的前提下,满足数据的使用和共享需求,确保数据的安全性和合规性。
企业对脱敏技术的需求程度很高。尽管许多文章都提到了脱敏方式和特定数据类型的建议,但实际推动产品研发部门进行合理脱敏时,安全人员会面临一些挑战。这些挑战并不是因为业务研发不了解如何进行脱敏,而是因为安全要求引起的改造成本以及对用户的影响。
比如,脱敏可能引发以下问题:
-
系统庞大复杂,包含大量页面和接口涉及敏感数据,需要大规模的代码改造。
-
系统不断迭代更新,业务研发需要增加安全内容,导致正常产品迭代周期的延长。
-
如果系统是购买的第三方产品且没有源代码,难以进行改造。
-
用户在某些情况下需要访问敏感数据,若受限则会影响其工作效率。
因此,在进行数据脱敏处理之前,企业需要仔细选择合适的方案并做好充分的规划。
实践案例
以ETLCloud社区版为例,新建流程拉取MySQL表中用户数据进行手机号脱敏处理:
库表输入
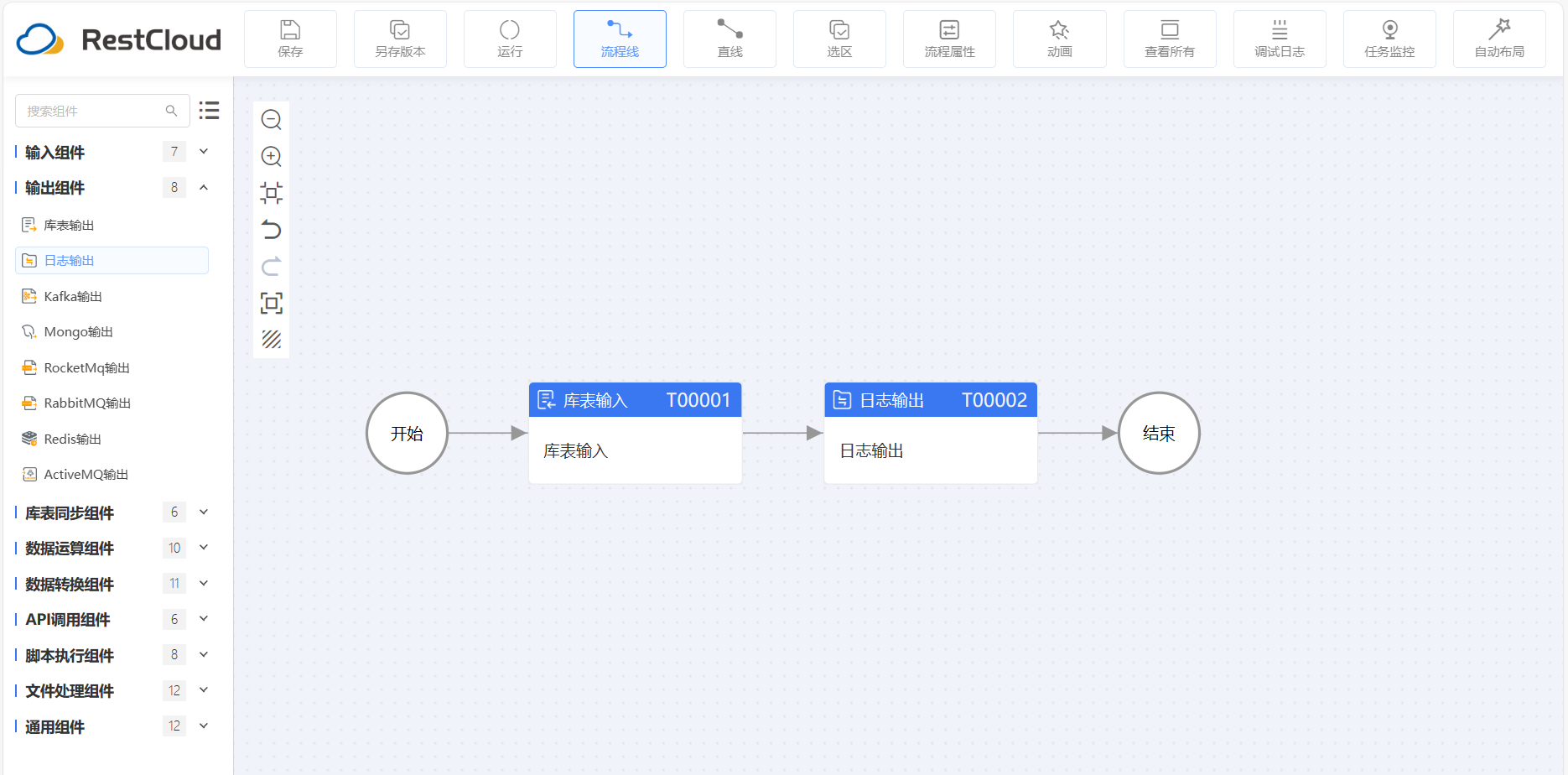
输入字段
日志输出打印效果

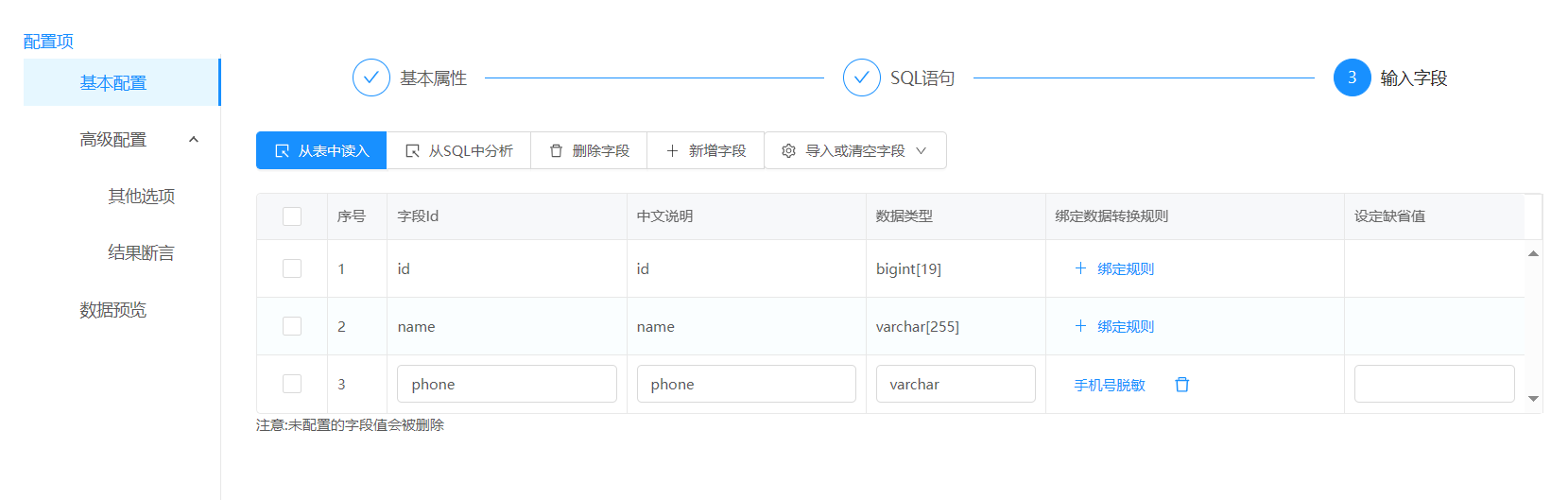
字段绑定规则
再次运行打印

从上面图片可以看出,使用ETL工具进行数据脱敏,通过绑定数据脱敏规则,可以把流程中的数据流的手机号码进行脱敏处理。
企业在面对庞大复杂的信息系统和严格的数据安全要求时,必须精心设计并实施数据脱敏方案。尤其是在ETL流程中,嵌入式的数据脱敏机制能够自动化地完成敏感信息的处理,降低因大规模代码改造带来的成本压力,同时也能适应快速迭代的业务需求,确保数据在整个生命周期内的安全流转和合规使用。

















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









