




一、从“大SQL”到“可视化ETL平台”,企业数据处理方式正在变化
在很多企业的数据中台、报表系统或营销数据链条中,数据清洗与转换往往被交由 一堆复杂的SQL脚本来完成:
-
一张清洗表可能对应上千行 SQL
-
多个逻辑依赖散落在不同的数据工程师手中
-
SQL的维护如“踩雷”般,一动就炸
虽然 SQL 足够强大,但当数据清洗任务变得复杂、高频、多源时,SQL方案就会开始暴露一系列问题。

图:大量复杂SQL运维难度极大
二、大SQL vs 可视化ETL平台:优缺点对比
| 对比维度 | 大SQL脚本 | 可视化ETL平台(如 ETLCloud) |
|---|---|---|
| 学习曲线 | 需掌握SQL编程、调优知识 | 拖拽组件,配置式,低代码友好 |
| 开发效率 | 快速起步但结构混乱 | 流程图清晰,便于多人协同 |
| 维护成本 | SQL嵌套多、变量混乱、调试困难 | 所见即所得,流程可视、日志可查 |
| 扩展性 | 新字段、逻辑改动牵一发动全身 | 组件式结构,便于灵活插入与复用 |
| 监控告警能力 | 无内建监控,需手动搭建 | 平台自带运行监控、异常预警、任务回溯 |
| 多源支持 | 支持有限,需自写连接与解析逻辑 | 内建连接器支持数据库、API、文件、对象存储等 |
总结一句话:SQL擅长“战术任务”,ETL平台才适合“战略数据链路”。
三、数据复杂度越高,越应该选择 ETL 平台
当以下场景逐渐增多时,大SQL方案便不再适用:
-
多源异构数据接入:如 MySQL、MongoDB、Excel、API 同时处理
-
多步依赖链路:如清洗 → 合并 → 分组 → 去重 → 再转换 → 分发
-
多团队协作:SQL掌握在特定开发人员手中,风险高
-
出错需回溯:SQL失败无法定位是哪一步、哪条数据异常
-
合规与审计:无法快速追踪流程变更和责任归属
而使用可视化 ETL 平台(如 ETLCloud),能更好地解决这些问题。
四、什么是真正好用的可视化 ETL 平台?
以 ETLCloud 为例,它具备以下关键能力:
- 低代码拖拽式建模
你可以像“搭积木”一样构建清洗流程:
去重、字段拆分、时间格式转换、正则提取只需配置
所有逻辑清晰可视、逻辑链路一目了然
- 多源数据连接器
内置支持包括:
数据库:MySQL、PostgreSQL、SQL Server、Oracle、DM、OB….
数据仓库:GP、ClickHouse、Doris、StarRocks等
文件:CSV、Excel、OSS、S3
API数据流:Restful接口、OAuth鉴权源等
- 日志监控与可追溯性
每个任务状态清晰记录,失败日志自动捕获
全流程版本控制,便于回溯与审计
可设置任务失败通知与自动重试机制
五、实际案例:某消费品牌如何替换 30+张大SQL 表单,实现数据运营自动化
该品牌原使用传统SQL脚本清洗电商平台与ERP数据,用于销售分析与财务预估。
问题包括:
-
多张 SQL 表相互引用,结构混乱
-
逻辑更改后需逐层排查依赖
-
非技术人员完全无法参与流程修改
上线 ETLCloud 后:
| 指标 | 变化前 | 变化后 |
|---|---|---|
| 数据清洗流程梳理耗时 | 2-3天 | 半小时流程图拉通 |
| 清洗任务每日失败报警率 | 10%+ | <0.1% |
| 团队协作能力 | 限定在1-2位工程师 | 产品、业务也可参与 |
| 每月SQL维护成本 | 高 | 降低80%以上 |
流程图示例
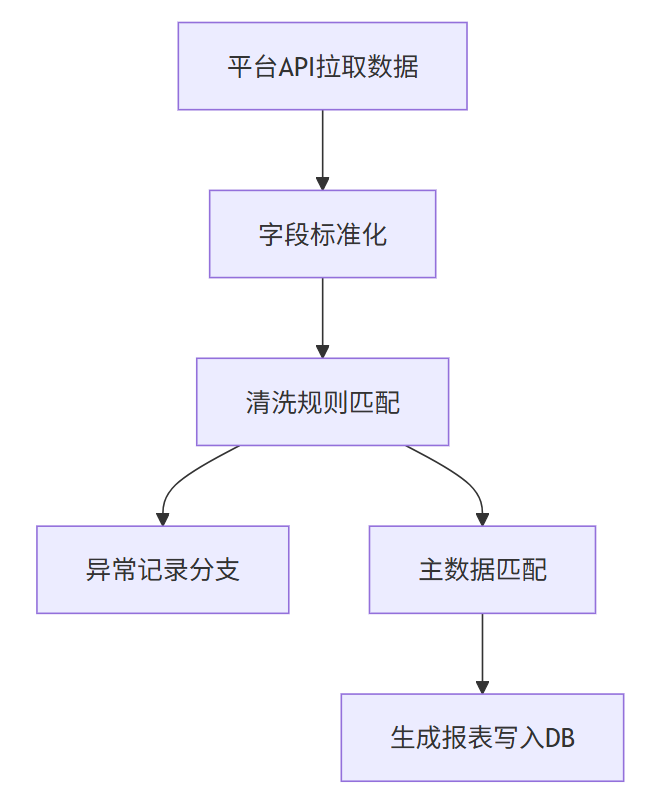
六、别让SQL成为你数据链路的“绊脚石”
SQL 是强大、必不可少的工具,但它不应承担数据清洗流程的全部责任。
当数据工程成为业务增长的核心要素时,我们需要一个:
-
透明可控的流程系统
-
稳定可监控的运行机制
-
跨角色协同的低门槛平台
ETLCloud 正是这样一款专为企业级数据清洗与转换场景打造的可视化ETL平台。
如果你的团队仍在为复杂 SQL 表头痛,或清洗流程无人能维护,不妨尝试一下 ETLCloud,社区版本永久免费下载使用 https://www.etlcloud.cn

















 2771
2771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









