







目录
模型结构评价:用较为简单的结构和较少的可调参数实现了高并行,泛用性强的模型。
一. 使用layer normalization而不是batch normalization,变长应用中一般 不用batch norm。原理:
文章信息:
题目:Attention Is All You Need
背景:
之前的时间序列预测模型多采用RNN或CNN。 RNN的模型运算高度序列化,必须从前往后依次计算,很难使用并行加速运算。同时RNN信息仅能由前方 相邻节点向后方传递,这导致处理长距离序列时RNN容易损失前方远距离的信息。为了解决RNN的低并行问题,一些研究试图使用CNN处理序列预测,这解决 了并行问题。但CNN有限的感受野导致需要多层卷积才能将前方远距离的信息传 到后方,没有解决处理长距离序列的问题。目的:解决现有时间序列预测模型低 并行性和长距离序列信息传递困难的问题
结论:
通过使用注意力机制实现了信息任意点传输仅需一步的功能,解决了处理长 距离序列信息传递困难的问题。使用多头注意力机制使模型具有高并行性, 同时 模仿了CNN多通道输出的效果,解决了低并行性的问题。表现效果上,在WMT2014英语翻译德语和WMT 2014英语翻译法语标准数据集上都实现了SOTA。
结果与讨论:
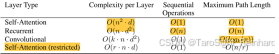
自注意力:增加关注文本长度开销大,增加投影维数开销小
RNN :增加文本长度开销小,增加投影维数开销大
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









