



正文详见:wow-rag/notebooks/第1课-手搓一个土得掉渣的RAG.ipynb at main · datawhalechina/wow-rag https://github.com/datawhalechina/wow-rag/blob/main/notebooks/%E7%AC%AC1%E8%AF%BE-%E6%89%8B%E6%90%93%E4%B8%80%E4%B8%AA%E5%9C%9F%E5%BE%97%E6%8E%89%E6%B8%A3%E7%9A%84RAG.ipynb
https://github.com/datawhalechina/wow-rag/blob/main/notebooks/%E7%AC%AC1%E8%AF%BE-%E6%89%8B%E6%90%93%E4%B8%80%E4%B8%AA%E5%9C%9F%E5%BE%97%E6%8E%89%E6%B8%A3%E7%9A%84RAG.ipynb
一、前期准备
1、创建环境
安装到一个你想安装的地方,不要让C盘太满了。
conda create --prefix=/home/conda_env/rag python=3.11.52、安装依赖库
首先进入环境:
conda activate /home/conda_env/rag依次安装依赖库:
pip install faiss-cpu scikit-learn scipy faiss-gpu
pip install openai ZHIpuAI
pip install python-dotenv 3、获取智谱API
智谱AI开放平台![]() https://open.bigmodel.cn/usercenter/proj-mgmt/apikeys
https://open.bigmodel.cn/usercenter/proj-mgmt/apikeys
4、导入API
新建一个.env文件存储你的API
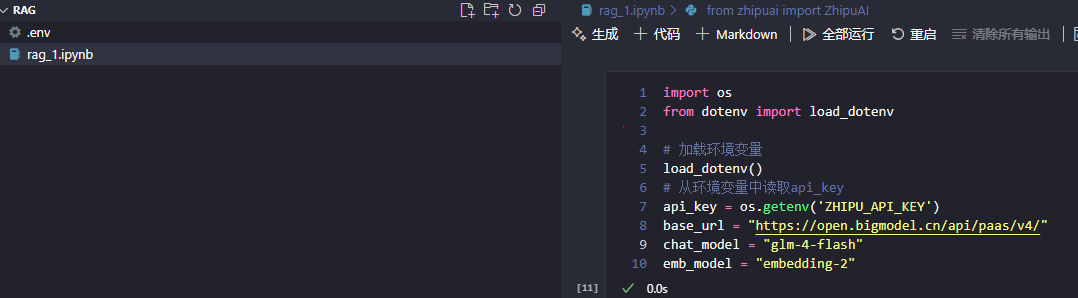
5、定义智谱API
from zhipuai import ZhipuAI
client = ZhipuAI(api_key=api_key) # 请填写您自己的APIKey二、构造知识库
RAG的原理是先在文档中搜索,把搜索到最接近的内容喂给大模型,让大模型根据喂给它的内容进行回答,因此需要存储文档块,便于检索。
1、切分文本文档
将长篇文章切分为小的文本块,方便后续检索。
2、文本块向量化
通过emb_model将文本块向量化并存储到数据库中。
3、数据库检索
数据库检索首先需要将输入文本转化问向量,和文本块转化过程一样。然后通过Faiss库的向量搜索方法寻找数据库中和输入文本最相似的文本块并返回。
三、构造prompt
在数据库中检索到需要的数据后,通过prompt告诉给大模型,让大模型根据该数据回复用户的输入。

















 1815
1815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









