







TCP 粘包/拆包 — Netty
使用 TCP 进行通讯,粘包和拆包是常见的问题。在数据传输过程中,由于 TCP 是面向字节流的协议,没有明确的数据范围的一串数据,可能会导致数据包的合并或拆分。
概念
TCP 是面向字节流的,无论哪个端发送数据,在接收的时候由于 TCP 不清楚上层的业务逻辑,由于 Maximum Segment Size(最大报文段大小)、Maximum Transmission Unit(最大传输单位)、Buffer Size(缓冲区大小),以及 Nagle 算法等指标的影响,也就产生了所谓的粘包和拆包的现象。
粘包和拆包的含义
粘包:发出方的多个数据包被合并成一个包发送,导致接收方无法区分每个数据包的数据范围。

拆包:发出方的一个数据包被拆分成多个包发送,导致接收方无法获取完整的数据。

MSS、MTU 、Buffer、Nagle
Maximum Segment Size(MSS,TCP 协议层上允许的最大数据段大小,指定了 TCP 数据段中的数据部分的最大字节数。) 是基于 Maximum Transmission Unit(MTU,MTU 是网络协议层上能够传输的最大数据包大小,单位是字节) 来设置的。
通常情况下,MSS 的最大值会小于或等于 MTU 减去 TCP 和 IP 头部的大小:通常是 1500 - 20 (IP) - 20 (TCP) = 1460 字节。Jumbo Frame 环境下是 9000 - 20 (IPv4) - 20 (TCP) = 8960 字节
TCP 为提高性能,发送端会将需要发送的数据发送到 Buffer 缓冲区,等待缓冲区满了之后,再将缓冲中的数据发送到接收方。同理,接收方也有缓冲区这样的机制,来接收数据。缓冲区大小是可调整的。
Nagle 算法是一种用于减少小数据包数量的优化策略。目的是通过将多个小的数据包合并成一个大数据包来提高网络性能,减少网络中数据包的数量,从而降低带宽的浪费。不过有的应用对实时性要求较高,Nagle 算法可能不适用(可能会导致延迟)。为了避免这种情况,可以通过关闭 Nagle 算法来强制立即发送数据包。基本原理是:
-
当应用程序发送一个小于 MSS(最大段大小)的数据包时,Nagle 算法会等待一个确认(ACK)包的到来,然后再发送下一个数据包。这是为了避免频繁发送小的数据包。
-
如果发送的数据包已经积累了足够的数据(达到 MSS),或者如果已经收到了之前的数据包的 ACK,Nagle 算法会将这些数据包发送出去。
// 关闭 Nagle 算法
channelHandlerContext.getChannel().socket().setTcpNoDelay(true);
解决方案(Netty)
使用固定长度数据包
最简单的解决方案之一。每个消息的长度是固定的,那么接收方就能清楚地知道每个包的大小,避免了粘包和拆包问题。实现简单,也不需要没有复杂的解码逻辑,容易理解。由于发送方总是发送固定长度的包,接收方根据固定长度来读取。只是消息长度变化较大,会导致浪费或效率较低,不适用于变长数据。
@Slf4j
@Component
public class SocketInitializer extends ChannelInitializer<SocketChannel> {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new FixedLengthFrameDecoder(1024)); // 假设每个消息的固定长度为1024字节
pipeline.addLast(new MyHandler());
}
}
使用消息分隔符
可以在消息之间添加特定的分隔符(例如换行符、空格、特定字符等),接收方通过分隔符来区分不同的消息。可以让发送方和接收方一起约定一个或多个分隔符(如换行符 \n),收到分隔符时解析完整的消息。实现简单且灵活,适用于文本协议(如 FTP、SMTP 等),不需要额外的长度字段。但是分隔符可能会被数据本身使用,导致冲突(例如如果数据中包含分隔符,则无法正确分割消息)。而且对于二进制数据也不适用。
@Slf4j
@Component
public class SocketInitializer extends ChannelInitializer<SocketChannel> {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new DelimiterBasedFrameDecoder(1024, Delimiters.lineDelimiter())); // 使用换行符作为分隔符
pipeline.addLast(new StringDecoder());
pipeline.addLast(new StringEncoder());
pipeline.addLast(new MyHandler());
}
}
使用消息长度字段
这是比较常见的解决方案,在每个消息的开始部分添加一个长度字段(通常是 2 字节、4 字节等),表示接下来的报文大小。接收方首先读取长度字段,然后根据该长度来读取消息体。这种最适用于二进制和文本数据。而且比分隔符方法更灵活,不容易发生冲突。只是增加了额外的开销,因为每个消息都需要一个长度字段。
假设每条消息的前 2 个字节表示消息体的长度,然后接收方读取指定长度的消息体。
@Slf4j
@Component
public class SocketInitializer extends ChannelInitializer<SocketChannel> {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LengthFieldBasedFrameDecoder(
1024, // 最大帧大小
0, // 长度字段的位置
4, // 长度字段的大小(例如4字节的整数)
0, // 跳过长度字段后的字节数
4)); // 长度字段的大小(假设是4字节)
pipeline.addLast(new MyHandler());
}
}
自定义协议(云快充协议)
一般大多数情况下,使用消息长度字段就足够解决大部分的拆包粘包问题了。但是实际开发过程中,公司的数据传输都会自定义一种自己协议,来指定如何打包和解析消息。这通常涉及在消息中使用长度字段、校验和、结束标志等元素。这样提供更大的灵活性,符合特定需求的协议。也可支持复杂的消息结构。只是实现复杂,需要定义清晰的协议格式,如果协议设计不当,大部分情况会导致解析错误,而且修改起来超级麻烦。这里以云快充协议为例:
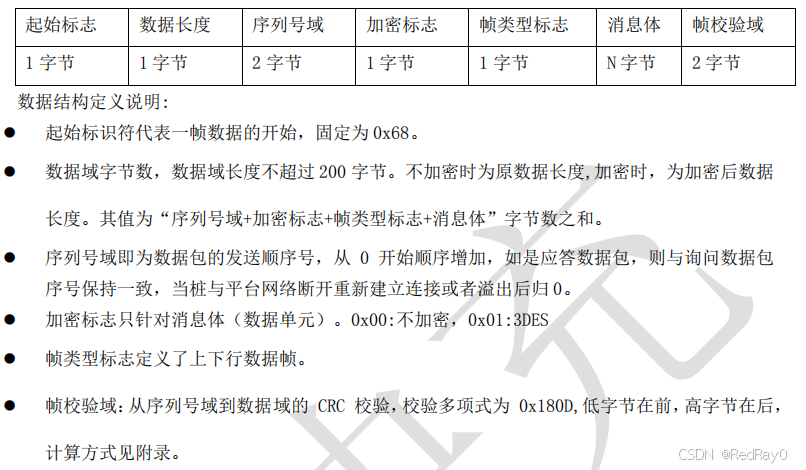
@Slf4j
@Component
public class SocketInitializer extends ChannelInitializer<SocketChannel> {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
// 超时
pipeline.addLast("idleStateHandler", new IdleStateHandler(15, 0, 0, TimeUnit.MINUTES));
pipeline.addLast(new YKCMessageDecoder()); // 解码
pipeline.addLast(new YKCMessageEncoder()); // 编码
pipeline.addLast(new YKCDataHandler()); // 编码
}
}
@Slf4j
@Component
public class MyFrameDecoder extends ByteToMessageDecoder {
public static final int PROTOCOL_HEAD_BASE_LENGTH = 2; // 基础数据长度
public static final byte PROTOCOL_HEAD = 0x68; // 协议标志
@Override
protected void decode(ChannelHandlerContext channelHandlerContext, ByteBuf byteBuf, List<Object> list) throws Exception {
// 最基础长度(协议头和消息体长度)都不够,
if (byteBuf.readableBytes() < PROTOCOL_HEAD_BASE_LENGTH) {
return;
}
// 标记当前 readerIndex 位置,如果读到后面发现只有一半,使用 resetReaderIndex 重置回来
byteBuf.markReaderIndex();
byte head = byteBuf.readByte();
if (head == PROTOCOL_HEAD) {
int bodyLen = 0xFF & byteBuf.readByte(); // 转成无符号的int,Byte.toUnsignedInt(byteBuf.readByte()) 写法可能更能提高代码可读性
if (byteBuf.readableBytes() <= bodyLen + 2) { // 剩余长度是 bodyLen + 2(帧校验域)
byteBuf.resetReaderIndex(); // 数据长度与协议里总长度不符
return;
}
// 长度足够,重置读取起始位置
byte[] body = new byte[bodyLen]; // 刚好前面2个字节(头和长度)抵去后面2个字节(帧校验域)
byteBuf.readBytes(body);
byte[] crcData = YKCCrcUtil.calculateCrc(body);
byte lowByte = byteBuf.readByte();
byte hiByte = byteBuf.readByte();
if (hiByte == crcData[0] && lowByte == crcData[1]) {
list.add(body);
} else {
log.error("crc校验失败.数据错误");
}
}else {
channelHandlerContext.channel().close(); // 不是云快充协议,直接关闭
}
}
}
@Slf4j
@Component
public class YKCMessageEncoder extends MessageToByteEncoder<String[]> {
@Override
protected void encode(ChannelHandlerContext channelHandlerContext, String[] bytes, ByteBuf out) throws Exception {
log.info("发送数据给客户端:{}", (Object) bytes);
byte[] res = ConvertUtil.hexArrToByteArr(bytes);
out.writeBytes(res);
}
}
总结
TCP 传输过程中,由于 MMS、MTU、Buffer、以及 Nagle 造成的粘包/拆包是很正常的,一般可使用 Netty 提供的一些内置解码器,例如:DelimiterBasedFrameDecoder、LengthFieldBasedFrameDecoder、FixedLengthFrameDecoder 来解决,也可使用自定义的解码器来处理复杂的传输协议。
使用过程中,通过合理配置缓冲区大小、优化发送和接收逻辑、以及使用合适的协议(如长度字段或分隔符),可以有效提高 TCP 通信的效率和稳定性。
另外,Nagle 算法会对 TCP 的粘包和拆包影响取决于应用层的数据发送模式。如果需要精细控制 TCP 包的发送行为,可以考虑根据需求调整是否启用 Nagle 算法。

















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









