



Iris 数据可视化
下载seaborn库
pip install seaborn
读取文件
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df_Iris = pd.read_csv(r'iris.data.txt')
数据可视化
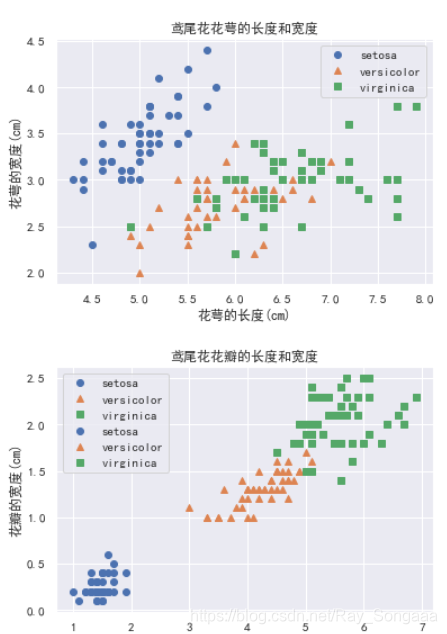
花萼长度与宽度/花瓣长度与宽度的可视化
from collections import Counter, defaultdict
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
style_list = ['o', '^', 's'] # 设置点的不同形状,不同形状默认颜色不同,也可自定义
data = iris_datas.data
labels = iris_datas.target_names
cc = defaultdict(list)
for i, d in enumerate(data):
cc[labels[int(i/50)]].append(d)
p_list = []
c_list = []
for each in [0, 2]:
for i, (c, ds) in enumerate(cc.items()):
draw_data = np.array(ds)
p = plt.plot(draw_data[:, each], draw_data[:, each+1], style_list[i])
p_list.append(p)
c_list.append(c)
plt.legend(map(lambda x: x[0], p_list), c_list)
plt.title('鸢尾花花瓣的长度和宽度') if each else plt.title('鸢尾花花萼的长度和宽度')
plt.xlabel('花瓣的长度(cm)') if each else plt.xlabel('花萼的长度(cm)')
plt.ylabel('花瓣的宽度(cm)') if each else plt.ylabel('花萼的宽度(cm)')
plt.show()
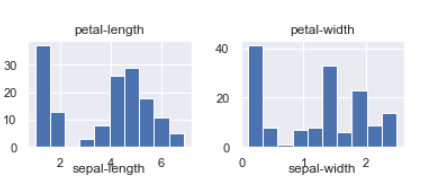
数据直方图
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = pd.read_csv(url, names=names)
dataset.hist()
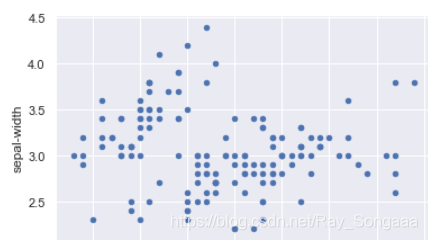
散点图
dataset.plot(x='sepal-length', y='sepal-width', kind='scatter')
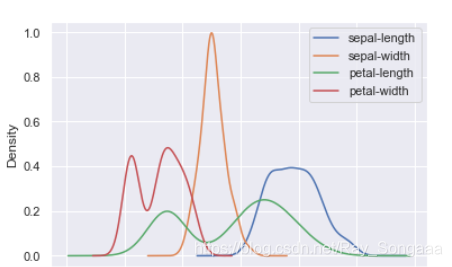
KDE图
KDE图也被称作密度图(Kernel Density Estimate,核密度估计)。
dataset.plot(kind='kde')
箱线图
dataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)

……
博客刚开,多多包涵,以后会尽量完善的
I’m Ray.I’m ok.

















 1060
1060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









