




SUMX 在 SUMARIZECOLUMNS 非总计行的底层计算过程
上一篇介绍了在总计行中出现与理论预期不符的结果,通过物理查询计划了解其底层计算过程,猜想是否 SUMMARIZECOLUMNS函数对总计行的计算存在什么特殊算法,本篇验证在非总计行中进行计算的情况,以帮助判断总计行是否是关键点。
SUMMARIZECOLUMNS 的疑似 bug(1)引言
SUMMARIZECOLUMNS 的疑似 bug(2)SUMX 在总计行
SUMMARIZECOLUMNS 的疑似 bug(3)总计行是否关键点
SUMMARIZECOLUMNS 的疑似 bug(4)验证触发条件
SUMMARIZECOLUMNS 的疑似 bug(5)最终结论
实验设计
很简单,在上一篇的基础上,从可视化对象(矩阵)的行标题中,去除 Dates[Month Num] ,仅保留 Dates[Year] ,观察计算结果并分析计算过程。
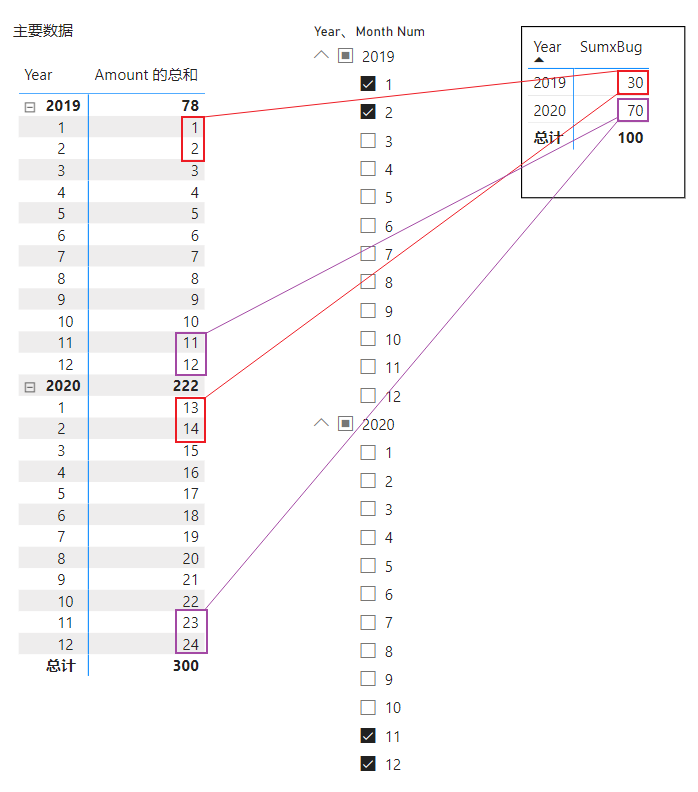
计算结果与上一篇中总计行的数值一样,说明在非总计行上也会发生相同的情况,因此可以否定掉SUMMARIZECOLUMNS总计行的计算存在特殊算法这个猜想。
在非总计行是如何计算出这些结果的,下面仍然通过分析物理查询计划来探究。
DAX 查询
EVALUATE
SUMMARIZECOLUMNS (
Dates[Year],
TREATAS (
{ ( 2019, 1 ), ( 2019, 2 ), ( 2020, 11 ), ( 2020, 12 ) },
'Dates'[Year],
'Dates'[Month Num]
),
"Total", [SumxBug]
)
这次没有添加 ROLLUPADDISSUBTOTAL函数,甚至没有 Dates[Month Num] 做参数
存储引擎
2个 xmSQL 查询
1、VQ1,F1V0
按切片器固化筛选器从 Dates 表中获取 Year 列的不重复值
SELECT
'Dates'[Year]
FROM 'Dates'
WHERE
( 'Dates'[Year], 'Dates'[Month Num] ) IN { ( 2020, 12 ) , ( 2019, 2 ) , ( 2020, 11 ) , ( 2019, 1 ) };
2、VQ2,F2,V1
固化筛选器又被破坏了,分别以 Year = {2019,2020} 和 Month Num = {1,2,11,12} 做条件,从 DFact 扩展表中按 Dates[Year] 和 Dates[Month Num]分组汇总 DFact[Amount]
SELECT
'Dates'[Year],
'Dates'[Month Num],
SUM ( 'DFact'[Amount] )
FROM 'DFact'
LEFT OUTER JOIN 'Dates'
ON 'DFact'[Date]='Dates'[Date]
WHERE
'Dates'[Year] IN ( 2019, 2020 ) VAND
'Dates'[Month Num] IN ( 12, 1, 2, 11 ) ;
逻辑查询计划
逻辑查询计划非常简短
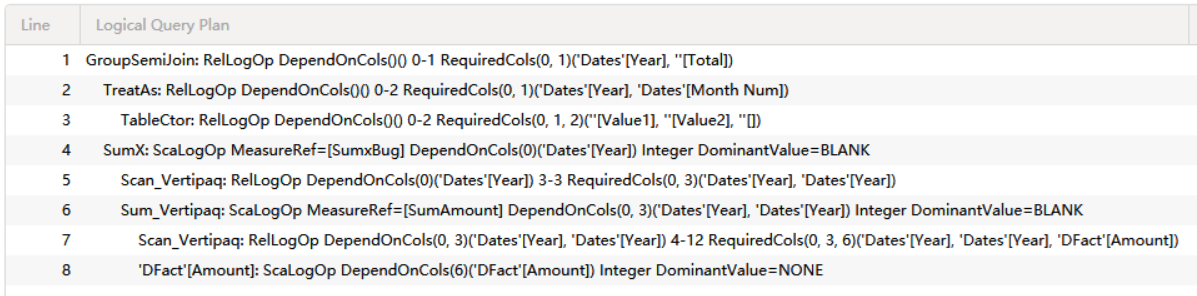
与上一篇有 ROLLUPADDISSUBTOTAL函数计算总计的情况相比,逻辑查询计划不再有 Union 操作符,与上一篇中逻辑查询计划左侧的分支结构相同。相同的是,仍然区分了 Year(0) 和 Year(3)。
物理查询计划
物理查询计划
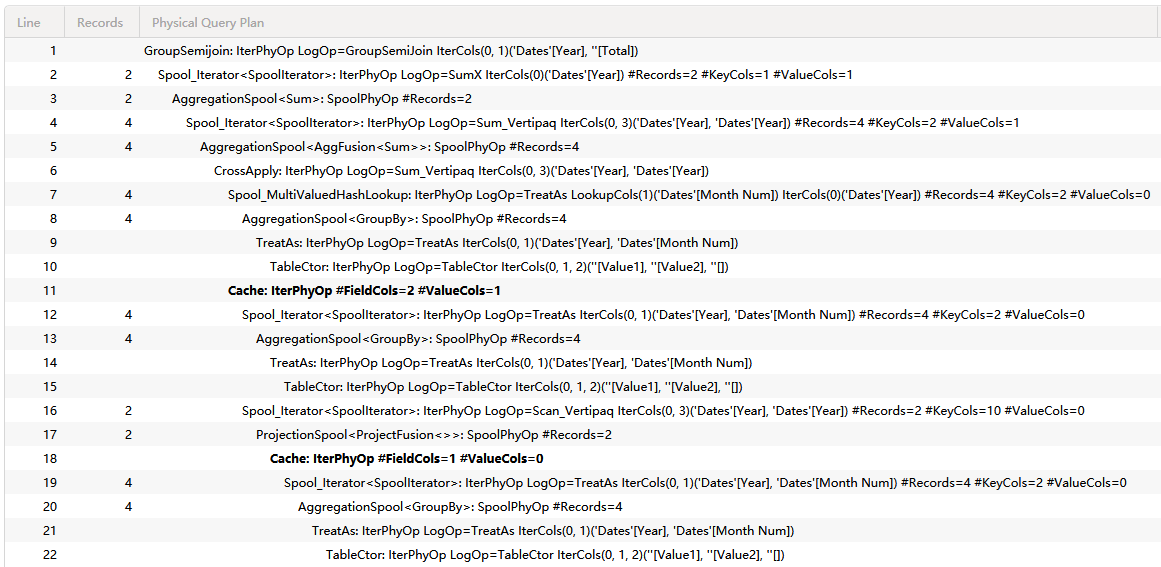
GroupSemijoin: IterPhyOp LogOp=GroupSemiJoin IterCols(0, 1)('Dates'[Year], ''[Total])
└── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=SumX IterCols(0)('Dates'[Year]) #Records=2 #KeyCols=1 #ValueCols=1
└── AggregationSpool<Sum>: SpoolPhyOp #Records=2
└── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Sum_Vertipaq IterCols(0, 3)('Dates'[Year], 'Dates'[Year]) #Records=4 #KeyCols=2 #ValueCols=1
└── AggregationSpool<AggFusion<Sum>>: SpoolPhyOp #Records=4
└── CrossApply: IterPhyOp LogOp=Sum_Vertipaq IterCols(0, 3)('Dates'[Year], 'Dates'[Year])
├── Spool_MultiValuedHashLookup: IterPhyOp LogOp=TreatAs LookupCols(1)('Dates'[Month Num]) IterCols(0)('Dates'[Year]) #Records=4 #KeyCols=2 #ValueCols=0
│ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=4
│ └── TreatAs: IterPhyOp LogOp=TreatAs IterCols(0, 1)('Dates'[Year], 'Dates'[Month Num])
│ └── TableCtor: IterPhyOp LogOp=TableCtor IterCols(0, 1, 2)(''[Value1], ''[Value2], ''[])
└── Cache: IterPhyOp #FieldCols=2 #ValueCols=1
├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=TreatAs IterCols(0, 1)('Dates'[Year], 'Dates'[Month Num]) #Records=4 #KeyCols=2 #ValueCols=0
│ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=4
│ └── TreatAs: IterPhyOp LogOp=TreatAs IterCols(0, 1)('Dates'[Year], 'Dates'[Month Num])
│ └── TableCtor: IterPhyOp LogOp=TableCtor IterCols(0, 1, 2)(''[Value1], ''[Value2], ''[])
└── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(0, 3)('Dates'[Year], 'Dates'[Year]) #Records=2 #KeyCols=10 #ValueCols=0
└── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=2
└── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
└── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=TreatAs IterCols(0, 1)('Dates'[Year], 'Dates'[Month Num]) #Records=4 #KeyCols=2 #ValueCols=0
└── AggregationSpool<GroupBy>: SpoolPhyOp #Records=4
└── TreatAs: IterPhyOp LogOp=TreatAs IterCols(0, 1)('Dates'[Year], 'Dates'[Month Num])
└── TableCtor: IterPhyOp LogOp=TableCtor IterCols(0, 1, 2)(''[Value1], ''[Value2], ''[])
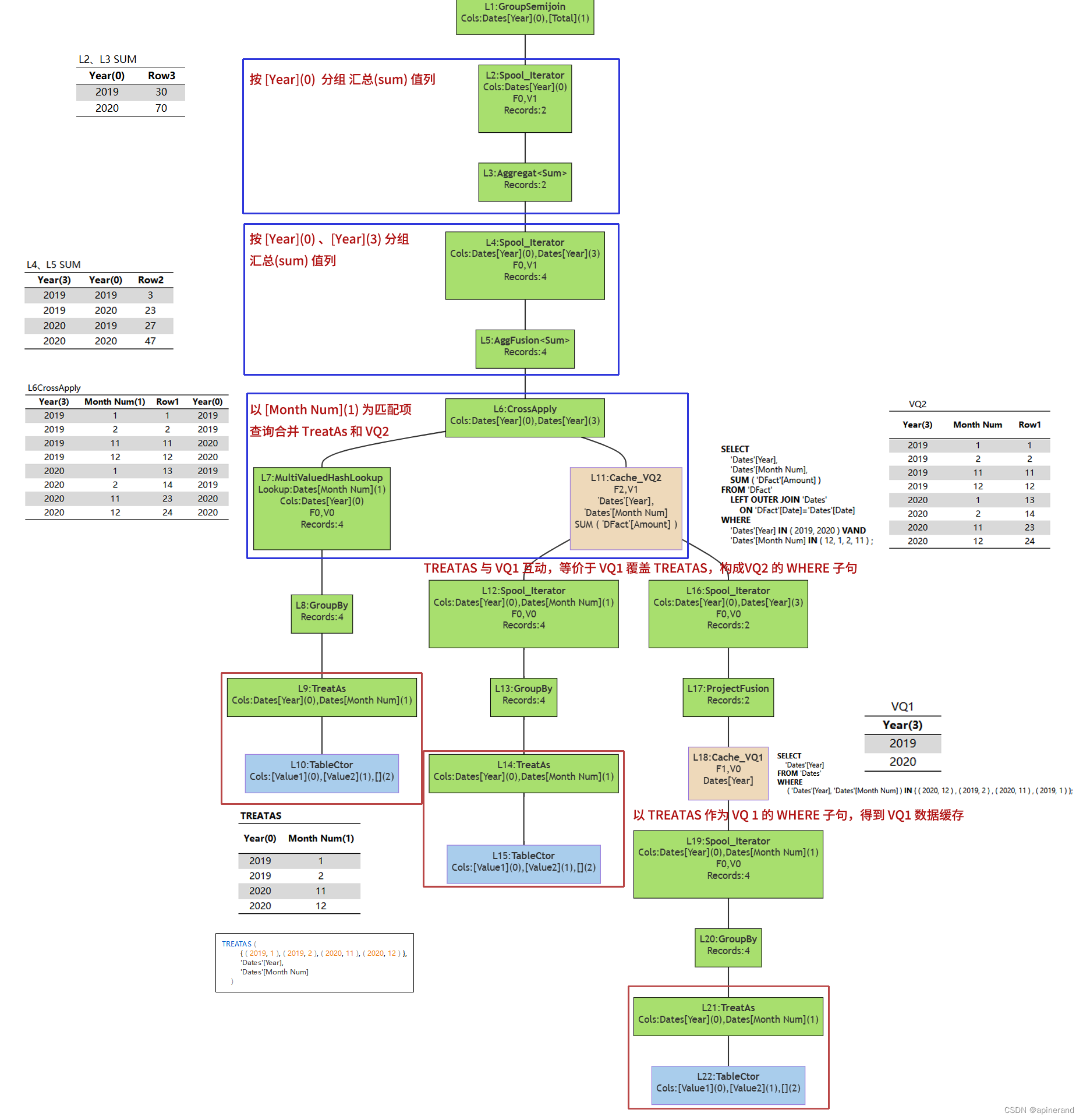
这次的物理查询计划,更新了我们对 SUMMARIZECOLUMNS的一些认识,为了进行比较,贴出完整的流程结构图。
将该查询计划与上一篇的查询计划进行对比,我们发现,这一次的查询计划与上一篇查询计划中右侧分支的结构完全相同,当时我们根据底层计算过程与最终计算结果的关系,判断右侧分支是【总计行】计算,并认为SUMMARIZECOLUMNS计算总计时采取了特别的方式使得计算结果不符合 DAX 理论。
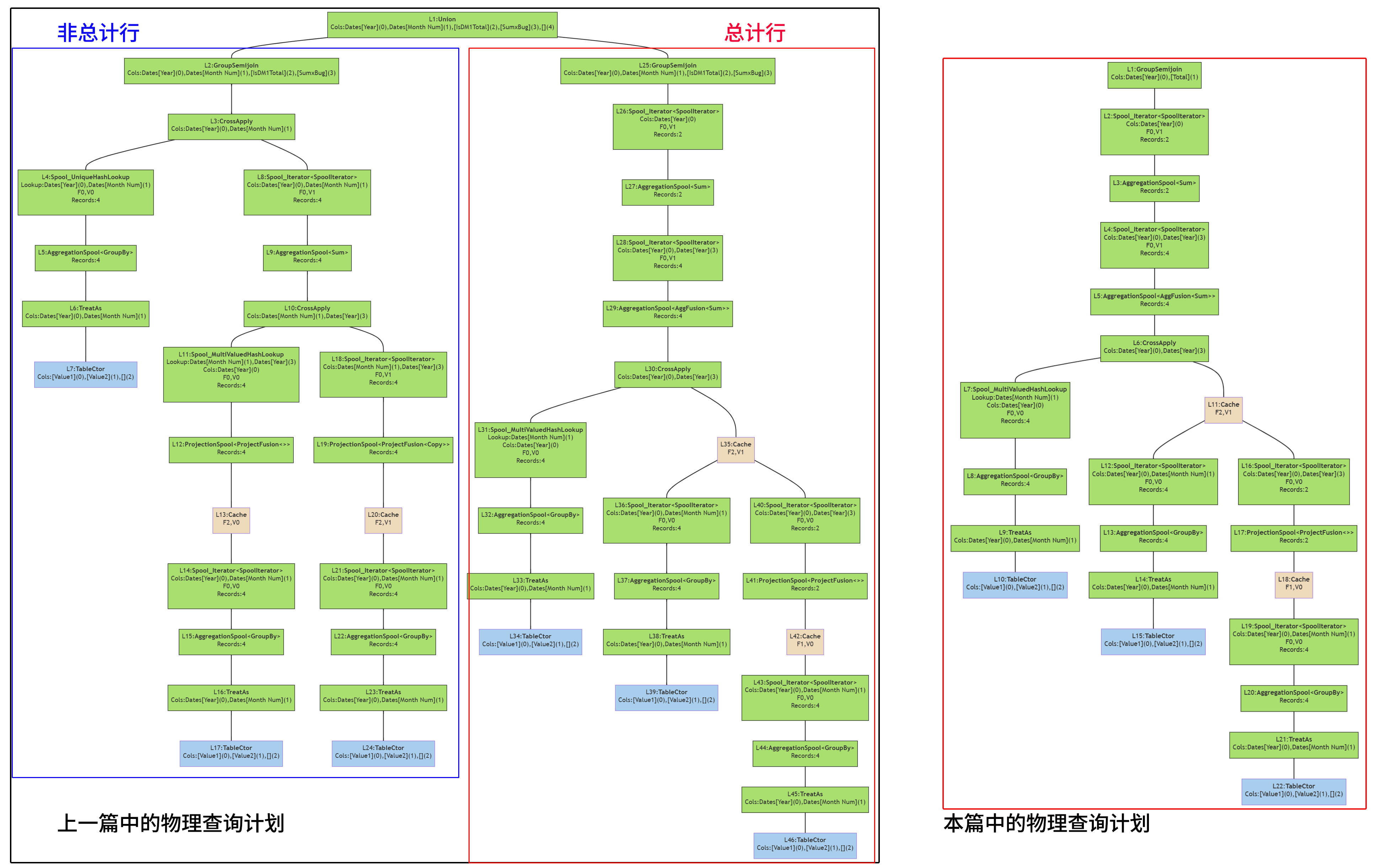
现在我们发现这是错误的认识,本篇没有总计行,却仍然出现了与上篇总计行相同的物理查询计划。
有了该发现,需要更新一下认识:虽然上一篇右测分支的确算的是【总计行】,但其计算步骤也可以用于【非总计行】计算,正如本篇所展示的物理查询计划。
往前再推一步,计算结果与理论不符,重点并不在【是否总计行】,而是在其他因素。
实际计算过程
实际计算过程与上一篇计算【总计行】的过程完全一样
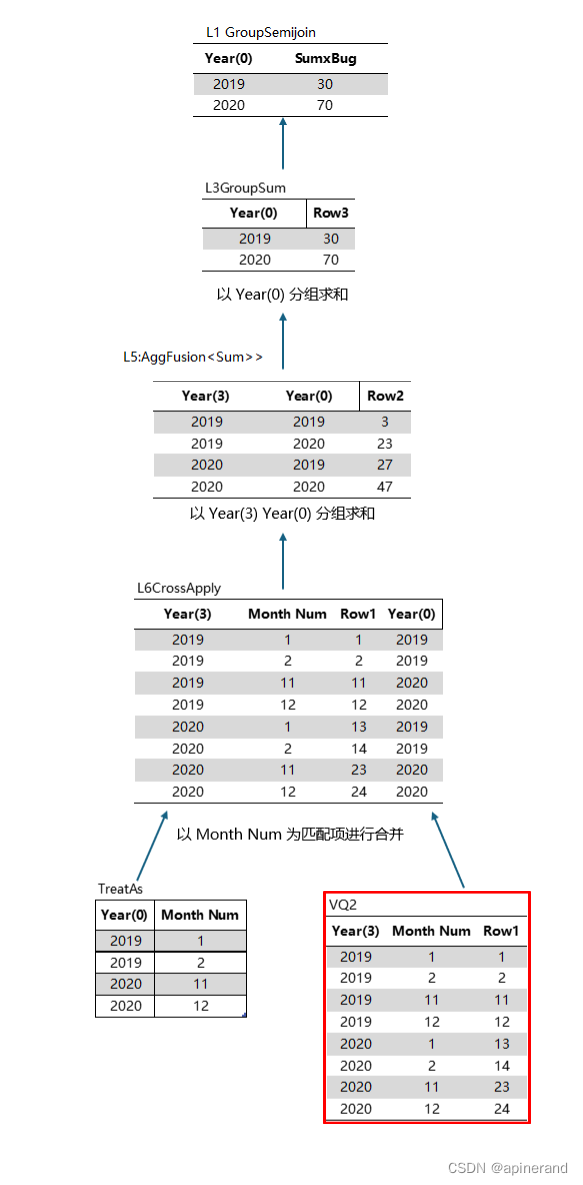
与物理查询计划对应起来是这样的
修正认识
猜想1中认为总计行是关键,现在看来并不是,总计行并不是关键。
与上一篇情况对比,共性的地方有:
- 参数上包含 Dates[Year]
- 使用的固化筛选器中包含有 Dates[Year]
- 度量值中存在对 Dates[Year] 进行迭代的迭代器
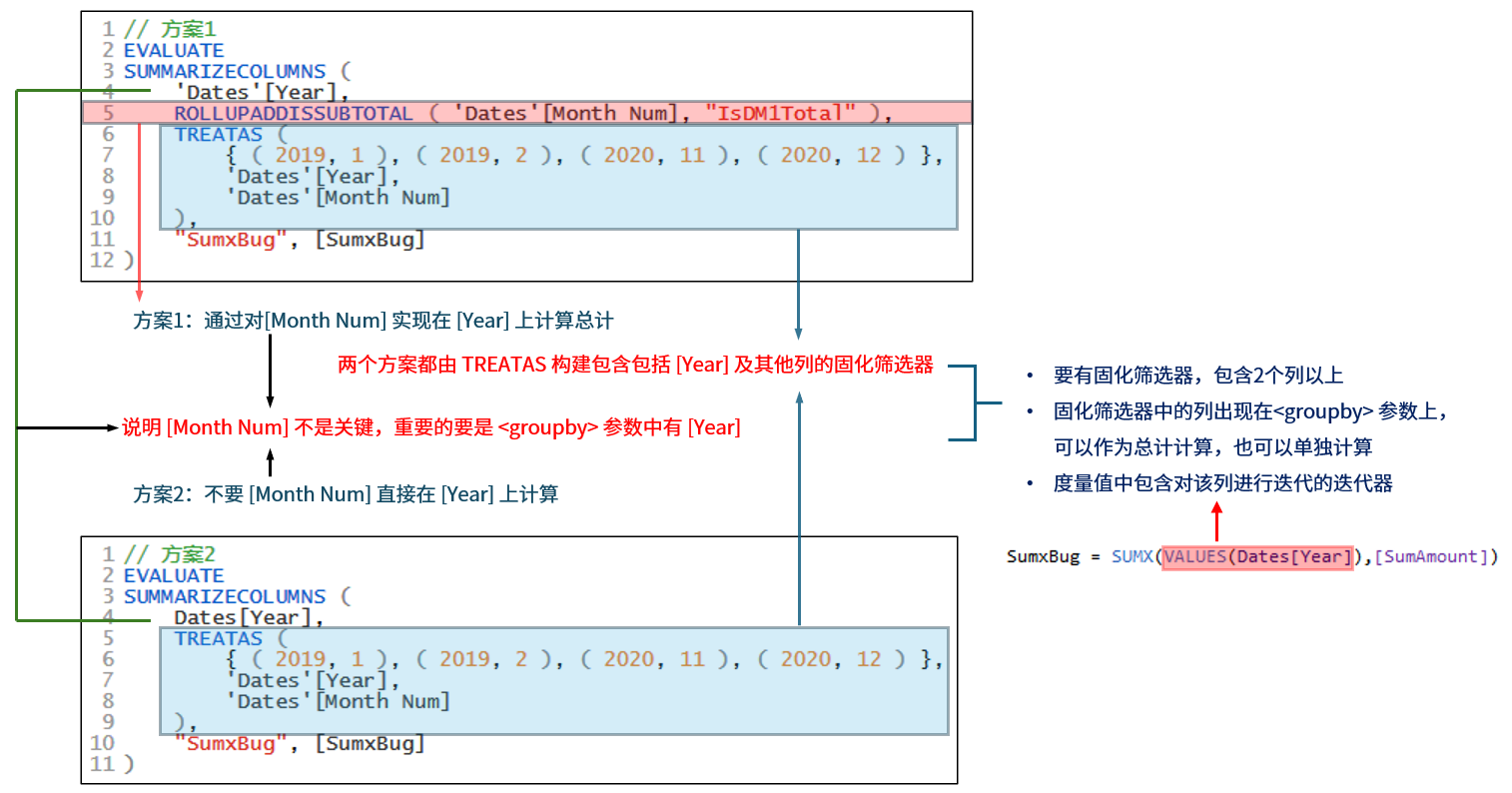
这些共性可能是触发该 bug 的关键点。
进行一个简单的验证,修改度量值和报表,用 Dates[Month Num] 代替 Dates[Year],观察计算结果
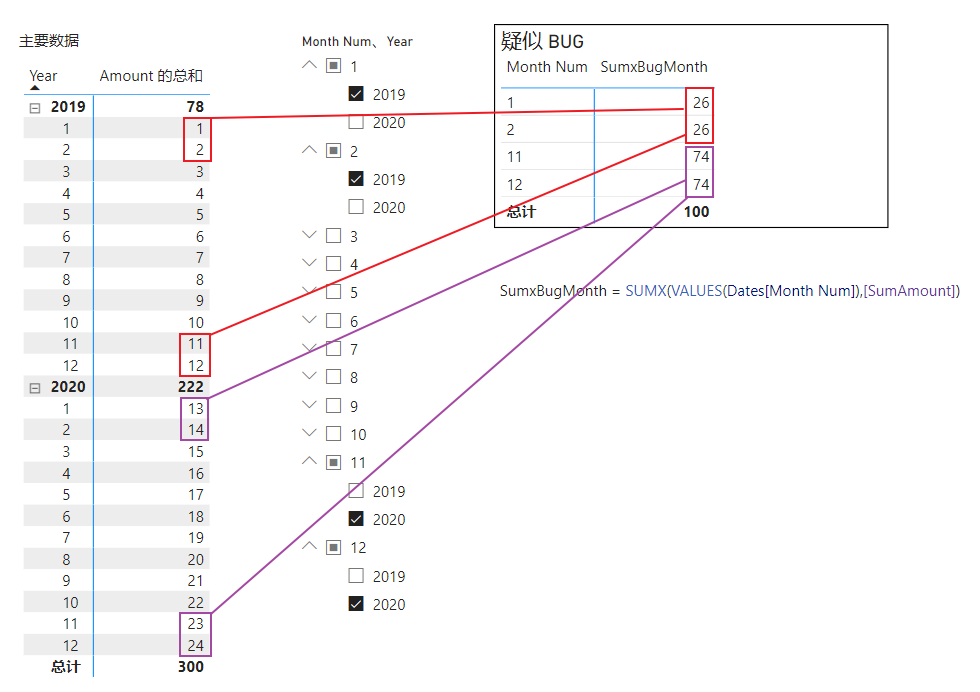
根据前面对底层计算过程的认识,可以推断这个结果是这样计算出来的
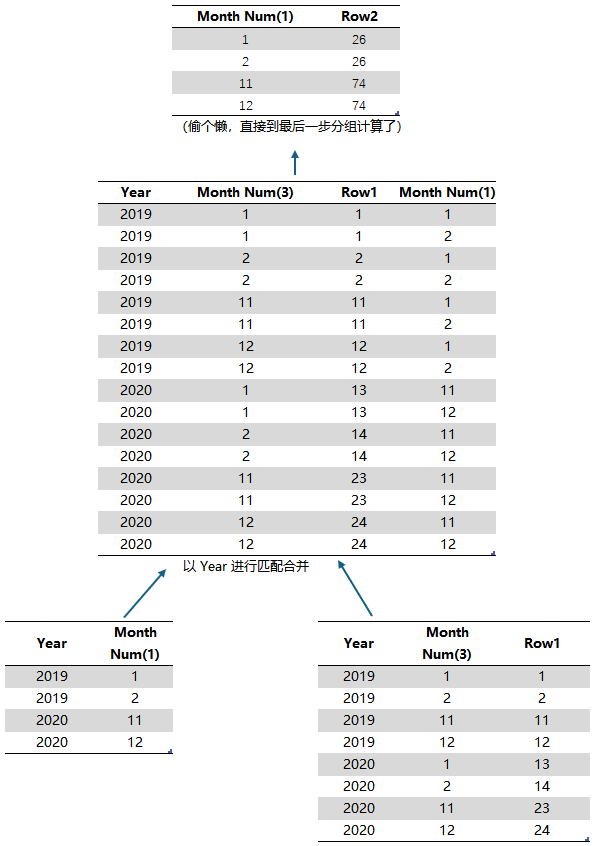
符合实际计算结果,由此可以将前面的3点认识抽象总结一下:
- 参数上包含 [关键列]
- 使用的固化筛选器中包含有 1# 中的 [关键列] ,且还有其他列(也许需要来自同一个表,待验证)
- 度量值中存在对 1# 中的 [关键列] 进行迭代的迭代器
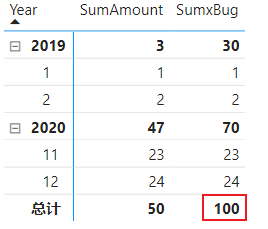
为了收集更多信息,我们准备在下一篇中尝试故意破坏其中的条件,比如,去掉第一点,不在中包含 [关键列],这对应了报表中矩阵最底部的总计行的计算,比如下图中的 100,它是怎么算出来的,是否仍然按照上述计算过程进行?下一篇将继续探究。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









