



1.数据簿及随机数据创建和生成
因为是用Python处理随机生成的数据所以我们首先导入random这个标准库:
from random import choice, randint,choice用于在非空序列等概率返回一个元素,randint则是用于生成数据.
由于是处理excel中的数据,我们需要从可以读写excel这个库中导入功能:
from openpyxl import Workbook, load_workbook
Workbook:这是openpyxl库中的一个类,用于创建一个新的Excel工作簿。
load_workbook:这是一个函数,用于加载一个已存在的Excel工作簿,以便进行读取或修改。
接下来我们开始生成随机数据,首先建立一个新的excel工作簿:
def generateRandomInformation(filename):
workbook = Workbook() # 创建一个新的Excel工作簿
worksheet = workbook.worksheets[0] # 获取第一个工作表
worksheet.append(['姓名','课程','成绩']) # 在工作表的首行添加表头
再对该工作表进行数据的插入:

以上便是随机生成数据的一些样本,设定人的名字三个字每个字都分别从上述数据生成,课程则从'语文','数学','英语'中随机生成,接下来正式开始生成数据:

随后开始随机生成成绩:
worksheet.append([name, choice(subjects), randint(0, 100)]) # 将姓名、随机课程和0-100之间的随机成绩添加到工作表中 # 保存数据,生成Excel 2007格式的文件
最后保存工作簿:
workbook.save(filename) # 保存工作簿到指定的文件名
这样一个包含数据的完整工作簿就创建好了.
2.遍历上述数据簿并把数据存放在新的数据簿中
创建一个函数getResult:

再创建一个用于存放结果的字典(如上图所示)
然后我们打开原始数据:

遍历原始数据:

再创建一个新的工作表用于存放结果:

跟第一个函数创建工作簿的方法是一样的
然后将result字典中的结果写入excel文件:
最后保存新的工作簿到指定文件名:workbook1.save(newfile)
3.举例示范
举个栗子看看:
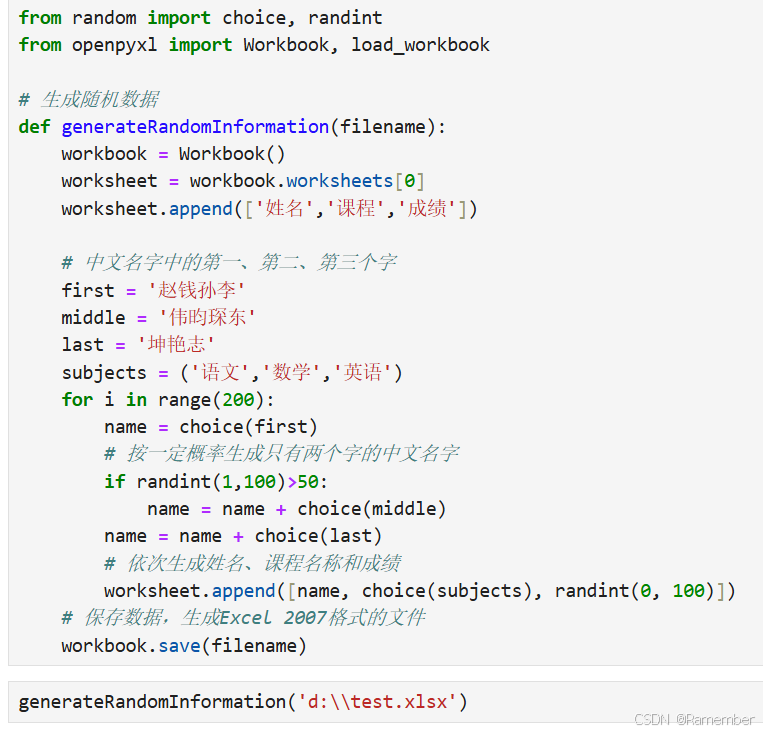
当我执行上述操作时,我的d盘中出现了test.xlsx这个excel文件,并生成了200个学生数据:
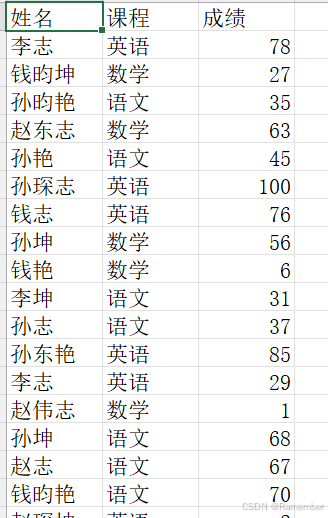
这是生成数据的一部分,这时我可以执行调用getResult('d:\\test.xlsx', 'd:\\result.xlsx'),文件会保留以下数据:(数据量较大,仅展示一部分)

这是因为 getResult 函数会保留每个学生每门课程的最高成绩。


















 5783
5783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









