



 本文深入探讨了数据结构与算法中的重要概念,包括并查集的路径压缩与应用、拓扑排序的经典BFS实现、快速排序中的三分法以及链表操作如合并、反转和回文判断。通过实例解析,展示了这些算法在解决实际问题中的高效性和灵活性。
本文深入探讨了数据结构与算法中的重要概念,包括并查集的路径压缩与应用、拓扑排序的经典BFS实现、快速排序中的三分法以及链表操作如合并、反转和回文判断。通过实例解析,展示了这些算法在解决实际问题中的高效性和灵活性。
1.并查集
1)模板
压缩路径:
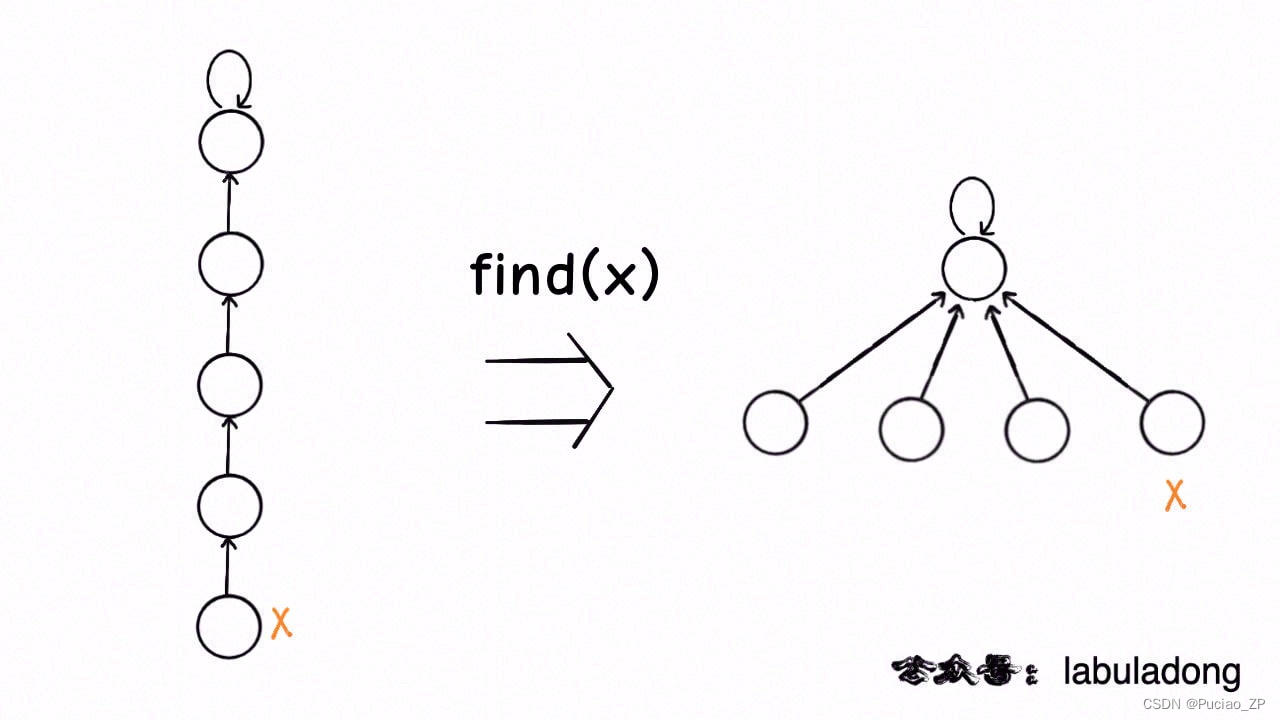
class UF {
// 连通分量个数
private int count;
// 存储每个节点的父节点
private int[] parent;
// n 为图中节点的个数
public UF(int n) {
this.count = n;
parent = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
// 将节点 p 和节点 q 连通
public void union(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
if (rootP == rootQ)
return;
parent[rootQ] = rootP;
// 两个连通分量合并成一个连通分量
count--;
}
// 判断节点 p 和节点 q 是否连通
public boolean connected(int p, int q) {
int rootP = find(p);
int rootQ = find(q);
return rootP == rootQ;
}
//压缩路径
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
// 返回图中的连通分量个数
public int count() {
return count;
}
}
2)典型例题
<130题>
思路:对此题思路要转换,反过来想,核心就是:找到所有与边缘o相连的区域合并到数组的最后一个节点(并查集最后的数组位置是故意多留出来的),对该区域标记后不做处理;对非边界上的O,连接到一起,后续遍历更改为x
//并查集
class Solution {
//这个并查集没有路径压缩
class UnionFind {
int[] parents;
public UnionFind(int totalNodes) {
parents = new int[totalNodes];
for (int i = 0; i < totalNodes; i++) {
parents[i] = i;
}
}
void union(int node1, int node2) {
int root1 = find(node1);
int root2 = find(node2);
if (root1 != root2) {
parents[root2] = root1;
}
}
int find(int node) {
while (parents[node] != node) {
parents[node] = parents[parents[node]];
node = parents[node];
}
return node;
}
boolean isConnect(int node1, int node2) {
return find(node1) == find(node2);
}
}
int cols;//记录列
public void solve(char[][] board) {
if (board == null || board.length == 0) {
return;
}
int row = board.length;
int col = board[0].length;
cols = col;
UnionFind uf = new UnionFind(row * col + 1);
int spe = row * col;
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
if (board[i][j] == 'O') {
//边界上的O合并到数组最后一个元素上
if (i == 0 || i == row - 1 || j == 0 || j == col - 1) {
uf.union(node(i, j), spe);
} else {
//不在边界上的O直接合并到一起
if (i > 0 && board[i - 1][j] == 'O') {
uf.union(node(i, j), node(i - 1, j));
}
if (i < row - 1 && board[i + 1][j] == 'O') {
uf.union(node(i, j), node(i + 1, j));
}
if (j > 0 && board[i][j - 1] == 'O') {
uf.union(node(i, j), node(i, j - 1));
}
if (j < col - 1 && board[i][j + 1] == 'O') {
uf.union(node(i, j), node(i, j + 1));
}
}
}
}
}
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
if (uf.isConnect(node(i, j), spe)) {
board[i][j] = 'O';
} else {
board[i][j] = 'X';
}
}
}
}
int node(int i, int j) {
return i * cols + j;
}
}
<547题>
这个就是一道模板题,只要模板记住了就能做出来。
2.拓扑排序
1)思想:
「拓扑排序」是专门应用于有向图的算法;
这道题用 BFS 和 DFS 都可以完成,只需要掌握 BFS 的写法就可以了,BFS 的写法很经典;
BFS 的写法就叫「拓扑排序」,这里还用到了贪心算法的思想,贪的点是:当前让入度为 0 的那些结点入队;
「拓扑排序」的结果不唯一;
删除结点的操作,通过「入度数组」体现,这个技巧要掌握;
「拓扑排序」的一个附加效果是:能够顺带检测有向图中是否存在环,这个知识点非常重要,如果在面试的过程中遇到这个问题,要把这一点说出来。
2)例题
<207题>
3.快速排序与三分法(3-way-partition)
快速排序:
快速排序实现了将小于pivot元素的数放到它前面,大于的放到它后面。
void quickSelect(int[] nums,int left,int right){
int pivot = nums[left];
int l = left;
int r = right;
while(l<r){
while(l<r&&nums[r]>=pivot){
r--;
}
if(l<r){
nums[l++]=nums[r];
}
while(l<r&&nums[l]<=pivot){
l++;
}
if(l<r){
nums[r--]=nums[l];
}
}
nums[l]=pivot;
}
三分法:
有些时候需要将向量快速划分为三块,例如LeetCode Sort Colors,向量nums中的元素等于0或1或2,要求在排序后,所有的0在最前面,然后是所有的1,最后是所有的2.该问题可以用三划分方法来解决。
也就是=pivot的元素要放到中间,也就是和pivot挨在一起,这一点是快速排序没实现的。
***思想:***将严格小于pivot的元素尽量方法i的位置(也就是靠前的位置);严格大于pivot的元素按照顺序往后面放,这样else的情况就是对应=pivot的情况,元素就会被挤到中间的位置了。

void partition(vector<int>& arr, int mid){
int i = 0, j = 0, n = arr.size() - 1;
while(j <= n){
if(arr[j] < mid)
swap(arr[i++], arr[j++]);
else if(arr[j] > mid)
swap(arr[j], arr[n--]);
else
j = j + 1;
}
}
<324题>
既用到了快速排序也用到了三分法
class Solution {
int n=-1;
public void wiggleSort(int[] nums) {
//找到中位数索引
int midIndex = this.quickSelect(nums,0,nums.length-1);
//找到中位数
int mid = nums[midIndex];
n=nums.length;
//三分法
for(int i=0,j=0,k=nums.length-1;j<=k;){
if(nums[V(j)]>mid){
swap(nums,V(j++),V(i++));
}else if(nums[V(j)]<mid){
swap(nums,V(j),V(k--));
}else{
j++;
}
}
}
public int V(int i){
return (1+2*(i)) % (n|1);
}
public void swap(int[] nums,int i,int j){
int t = nums[i];
nums[i]=nums[j];
nums[j]=t;
}
public int quickSelect(int[] nums,int left,int right){
int pivot = nums[left];
int l = left;
int r = right;
while(l<r){
while(l<r&&nums[r]>=pivot){
r--;
}
if(l<r){
nums[l++]=nums[r];
}
while(l<r&&nums[l]<=pivot){
l++;
}
if(l<r){
nums[r--]=nums[l];
}
}
nums[l]=pivot;
if(l==nums.length/2){
return l;
}else if(l>nums.length/2){
return this.quickSelect(nums,left,l-1);
}else{
return this.quickSelect(nums,l+1,right);
}
}
}
4.二叉树
1)BST二叉搜索树
1.二叉搜索树的合法性
这里是有坑的哦,我们按照普通的中序遍历的模板是不行的,每个节点自己要做的事不就是比较自己和左右孩子吗?看起来应该这样写代码:
boolean isValidBST(TreeNode root) {
if (root == null) return true;
if (root.left != null && root.val <= root.left.val)
return false;
if (root.right != null && root.val >= root.right.val)
return false;
return isValidBST(root.left)
&& isValidBST(root.right);
}
但是这个算法出现了错误,BST 的每个节点应该要小于右边子树的所有节点,下面这个二叉树显然不是 BST,因为节点 10 的右子树中有一个节点 6,但是我们的算法会把它判定为合法 BST:
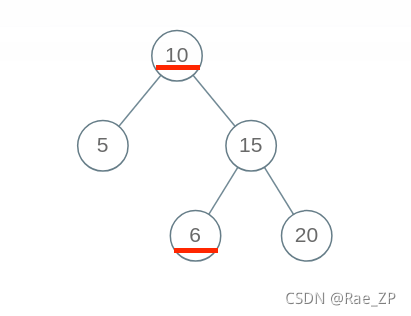
出现问题的原因在于,对于每一个节点 root,代码值检查了它的左右孩子节点是否符合左小右大的原则;但是根据 BST 的定义,root 的整个左子树都要小于 root.val,整个右子树都要大于 root.val。
问题是,对于某一个节点 root,他只能管得了自己的左右子节点,怎么把 root 的约束传递给左右子树呢?
请看正确的代码:
boolean isValidBST(TreeNode root) {
return isValidBST(root, null, null);
}
/* 限定以 root 为根的子树节点必须满足 max.val > root.val > min.val */
boolean isValidBST(TreeNode root, TreeNode min, TreeNode max) {
// base case
if (root == null) return true;
// 若 root.val 不符合 max 和 min 的限制,说明不是合法 BST
if (min != null && root.val <= min.val) return false;
if (max != null && root.val >= max.val) return false;
// 限定左子树的最大值是 root.val,右子树的最小值是 root.val
return isValidBST(root.left, min, root)
&& isValidBST(root.right, root, max);
}
我们通过使用辅助函数,增加函数参数列表,在参数中携带额外信息,将这种约束传递给子树的所有节点,这也是二叉树算法的一个小技巧吧。
2.在 BST 中搜索一个数
其实不需要递归地搜索两边,对于普通二叉树搜索一个数可以通过递归中序遍历的方式,但是由于BST的特点可以使用类似二分查找思想,根据 target 和 root.val 的大小比较,就能排除一边。我们把上面的思路稍稍改动:
boolean isInBST(TreeNode root, int target) {
if (root == null) return false;
if (root.val == target)
return true;
if (root.val < target)
return isInBST(root.right, target);
if (root.val > target)
return isInBST(root.left, target);
// root 该做的事做完了,顺带把框架也完成了,妙
}
3.在 BST 中插入一个数
上一个问题,我们总结了 BST 中的遍历框架,就是「找」的问题。直接套框架,加上「改」的操作即可。一旦涉及「改」,函数就要返回 TreeNode 类型,并且对递归调用的返回值进行接收。
TreeNode insertIntoBST(TreeNode root, int val) {
// 找到空位置插入新节点
if (root == null) return new TreeNode(val);
// if (root.val == val)
// BST 中一般不会插入已存在元素
if (root.val < val)
root.right = insertIntoBST(root.right, val);
if (root.val > val)
root.left = insertIntoBST(root.left, val);
return root;
}
4.BST删除一个元素
TreeNode deleteNode(TreeNode root, int key) {
if (root == null) return null;
if (root.val == key) {
// 这两个 if 把情况 1 和 2 都正确处理了
if (root.left == null) return root.right;
if (root.right == null) return root.left;
// 处理情况 3
TreeNode minNode = getMin(root.right);
root.val = minNode.val;
root.right = deleteNode(root.right, minNode.val);
} else if (root.val > key) {
root.left = deleteNode(root.left, key);
} else if (root.val < key) {
root.right = deleteNode(root.right, key);
}
return root;
}
TreeNode getMin(TreeNode node) {
// BST 最左边的就是最小的
while (node.left != null) node = node.left;
return node;
}
5.穷举所有可能的BST构造种类
思路:
1、穷举 root 节点的所有可能。
2、递归构造出左右子树的所有合法 BST。
3、给 root 节点穷举所有左右子树的组合。
/* 主函数 */
public List<TreeNode> generateTrees(int n) {
if (n == 0) return new LinkedList<>();
// 构造闭区间 [1, n] 组成的 BST
return build(1, n);
}
/* 构造闭区间 [lo, hi] 组成的 BST */
List<TreeNode> build(int lo, int hi) {
List<TreeNode> res = new LinkedList<>();
// base case
if (lo > hi) {
res.add(null);
return res;
}
// 1、穷举 root 节点的所有可能。
for (int i = lo; i <= hi; i++) {
// 2、递归构造出左右子树的所有合法 BST。
List<TreeNode> leftTree = build(lo, i - 1);
List<TreeNode> rightTree = build(i + 1, hi);
// 3、给 root 节点穷举所有左右子树的组合。
for (TreeNode left : leftTree) {
for (TreeNode right : rightTree) {
// i 作为根节点 root 的值
TreeNode root = new TreeNode(i);
root.left = left;
root.right = right;
res.add(root);
}
}
}
return res;
}
2)二叉树序列化
3)扁平化列表迭代器
参考
方法1:
将整形数字当成叶子结点,通过迭代访问树的叶子结点实现。实现的时候由于这种数据结构没有实现迭代器,需要自己去实现。
方法1的缺点是一次性加载了所以的整数,可能会占据很大的内存。因此可以通过方法2的惰性取值。
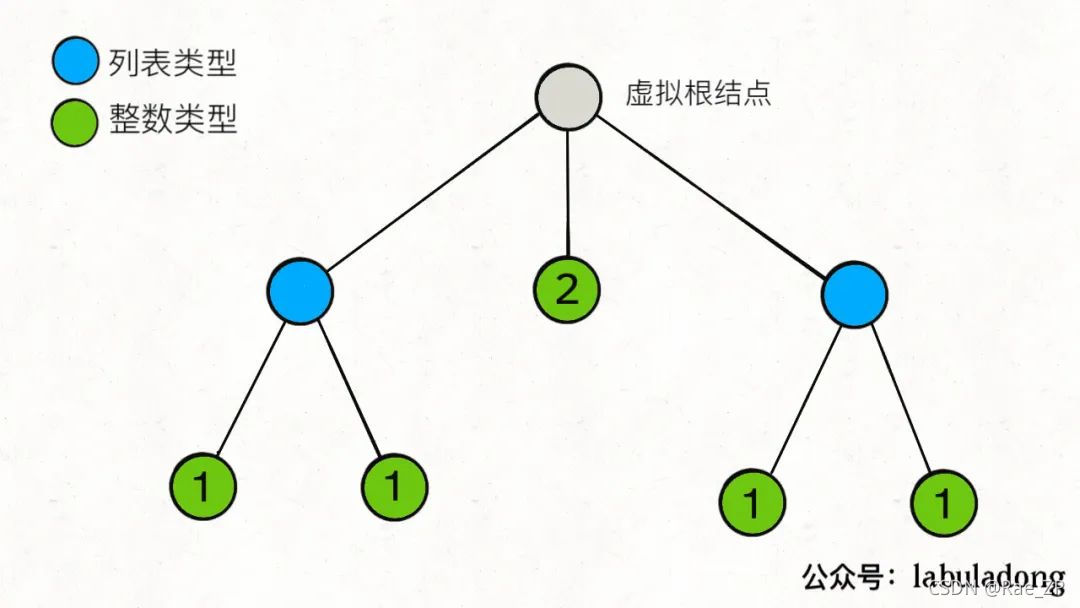
class NestedIterator implements Iterator<Integer> {
private Iterator<Integer> it;
public NestedIterator(List<NestedInteger> nestedList) {
// 存放将 nestedList 打平的结果
List<Integer> result = new LinkedList<>();
for (NestedInteger node : nestedList) {
// 以每个节点为根遍历
traverse(node, result);
}
// 得到 result 列表的迭代器
this.it = result.iterator();
}
public Integer next() {
return it.next();
}
public boolean hasNext() {
return it.hasNext();
}
// 遍历以 root 为根的多叉树,将叶子节点的值加入 result 列表
private void traverse(NestedInteger root, List<Integer> result) {
if (root.isInteger()) {
// 到达叶子节点
result.add(root.getInteger());
return;
}
// 遍历框架
for (NestedInteger child : root.getList()) {
traverse(child, result);
}
}
}
方法2:
调用hasNext时,如果nestedList的第一个元素是列表类型,则不断展开这个元素,直到第一个元素是整数类型。
由于调用next方法之前一定会调用hasNext方法,这就可以保证每次调用next方法的时候第一个元素是整数型,直接返回并删除第一个元素即可。
public class NestedIterator implements Iterator<Integer> {
private LinkedList<NestedInteger> list;
public NestedIterator(List<NestedInteger> nestedList) {
// 不直接用 nestedList 的引用,是因为不能确定它的底层实现
// 必须保证是 LinkedList,否则下面的 addFirst 会很低效
list = new LinkedList<>(nestedList);
}
public Integer next() {
// hasNext 方法保证了第一个元素一定是整数类型
return list.remove(0).getInteger();
}
public boolean hasNext() {
// 循环拆分列表元素,直到列表第一个元素是整数类型
while (!list.isEmpty() && !list.get(0).isInteger()) {
// 当列表开头第一个元素是列表类型时,进入循环
List<NestedInteger> first = list.remove(0).getList();
// 将第一个列表打平并按顺序添加到开头
for (int i = first.size() - 1; i >= 0; i--) {
list.addFirst(first.get(i));
}
}
return !list.isEmpty();
}
}
4)二叉树的遍历
1.层次遍历
// 输入一棵二叉树的根节点,层序遍历这棵二叉树
void levelTraverse(TreeNode root) {
if (root == null) return 0;
Queue<TreeNode> q = new LinkedList<>();
q.offer(root);
int depth = 1;
// 从上到下遍历二叉树的每一层
while (!q.isEmpty()) {
int sz = q.size();
// 从左到右遍历每一层的每个节点
for (int i = 0; i < sz; i++) {
TreeNode cur = q.poll();
printf("节点 %s 在第 %s 层", cur, depth);
// 将下一层节点放入队列
if (cur.left != null) {
q.offer(cur.left);
}
if (cur.right != null) {
q.offer(cur.right);
}
}
depth++;
}
}
2.多叉树的广度优先(BFS)
// 输入起点,进行 BFS 搜索
int BFS(Node start) {
Queue<Node> q; // 核心数据结构
Set<Node> visited; // 避免走回头路
q.offer(start); // 将起点加入队列
visited.add(start);
int step = 0; // 记录搜索的步数
while (q not empty) {
int sz = q.size();
/* 将当前队列中的所有节点向四周扩散一步 */
for (int i = 0; i < sz; i++) {
Node cur = q.poll();
printf("从 %s 到 %s 的最短距离是 %s", start, cur, step);
/* 将 cur 的相邻节点加入队列 */
for (Node x : cur.adj()) {
if (x not in visited) {
q.offer(x);
visited.add(x);
}
}
}
step++;
}
}
5)DFS回溯算法
在List<List<Integer>> res = new LinkedList<>();
/* 主函数,输入一组不重复的数字,返回它们的全排列 */
List<List<Integer>> permute(int[] nums) {
// 记录「路径」
LinkedList<Integer> track = new LinkedList<>();
backtrack(nums, track);
return res;
}
// 路径:记录在 track 中
// 选择列表:nums 中不存在于 track 的那些元素
// 结束条件:nums 中的元素全都在 track 中出现
void backtrack(int[] nums, LinkedList<Integer> track) {
// 触发结束条件
if (track.size() == nums.length) {
res.add(new LinkedList(track));
return;
}
for (int i = 0; i < nums.length; i++) {
// 排除不合法的选择
if (track.contains(nums[i])) {
continue;
}
// 做选择
track.add(nums[i]);
// 进入下一层决策树
backtrack(nums, track);
// 取消选择
track.removeLast();
}
}
5.链表
1)单链表
1、合并两个有序链表
ListNode mergeTwoLists(ListNode l1, ListNode l2) {
// 虚拟头结点
ListNode dummy = new ListNode(-1), p = dummy;
ListNode p1 = l1, p2 = l2;
while (p1 != null && p2 != null) {
// 比较 p1 和 p2 两个指针
// 将值较小的的节点接到 p 指针
if (p1.val > p2.val) {
p.next = p2;
p2 = p2.next;
} else {
p.next = p1;
p1 = p1.next;
}
// p 指针不断前进
p = p.next;
}
if (p1 != null) {
p.next = p1;
}
if (p2 != null) {
p.next = p2;
}
return dummy.next;
}
2、合并 k 个有序链表
合并 k 个有序链表的逻辑类似合并两个有序链表,难点在于,如何快速得到 k 个节点中的最小节点,接到结果链表上?
这里我们就要用到 优先级队列(二叉堆) 这种数据结构,把链表节点放入一个最小堆,就可以每次获得 k 个节点中的最小节点:
ListNode mergeKLists(ListNode[] lists) {
if (lists.length == 0) return null;
// 虚拟头结点
ListNode dummy = new ListNode(-1);
ListNode p = dummy;
// 优先级队列,最小堆
PriorityQueue<ListNode> pq = new PriorityQueue<>(
lists.length, (a, b)->(a.val - b.val));
// 将 k 个链表的头结点加入最小堆
for (ListNode head : lists) {
if (head != null)
pq.add(head);
}
while (!pq.isEmpty()) {
// 获取最小节点,接到结果链表中
ListNode node = pq.poll();
p.next = node;
if (node.next != null) {
pq.add(node.next);
}
// p 指针不断前进
p = p.next;
}
return dummy.next;
}
优先队列 pq 中的元素个数最多是 k,所以一次 poll 或者 add 方法的时间复杂度是 O(logk);所有的链表节点都会被加入和弹出 pq,所以算法整体的时间复杂度是 O(Nlogk),其中 k 是链表的条数,N 是这些链表的节点总数。
3、寻找单链表的倒数第 k 个节点
双指针实现
// 返回链表的倒数第 k 个节点
ListNode findFromEnd(ListNode head, int k) {
ListNode p1 = head;
// p1 先走 k 步
for (int i = 0; i < k; i++) {
p1 = p1.next;
}
ListNode p2 = head;
// p1 和 p2 同时走 n - k 步
while (p1 != null) {
p2 = p2.next;
p1 = p1.next;
}
// p2 现在指向第 n - k 个节点
return p2;
}
4、寻找单链表的中点
快慢指针
ListNode middleNode(ListNode head) {
// 快慢指针初始化指向 head
ListNode slow = head, fast = head;
// 快指针走到末尾时停止
while (fast != null && fast.next != null) {
// 慢指针走一步,快指针走两步
slow = slow.next;
fast = fast.next.next;
}
// 慢指针指向中点
return slow;
}
5、判断单链表是否包含环并找出环起点
当快慢指针相遇时,让其中任一个指针指向头节点,然后让它俩以相同速度前进,再次相遇时所在的节点位置就是环开始的位置。
ListNode detectCycle(ListNode head) {
ListNode fast, slow;
fast = slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if (fast == slow) break;
}
// 上面的代码类似 hasCycle 函数
if (fast == null || fast.next == null) {
// fast 遇到空指针说明没有环
return null;
}
// 重新指向头结点
slow = head;
// 快慢指针同步前进,相交点就是环起点
while (slow != fast) {
fast = fast.next;
slow = slow.next;
}
return slow;
}
6、判断两个单链表是否相交并找出交点
可以让 p1 遍历完链表 A 之后开始遍历链表 B,让 p2 遍历完链表 B 之后开始遍历链表 A,这样相当于「逻辑上」两条链表接在了一起。
如果这样进行拼接,就可以让 p1 和 p2 同时进入公共部分,也就是同时到达相交节点 c1
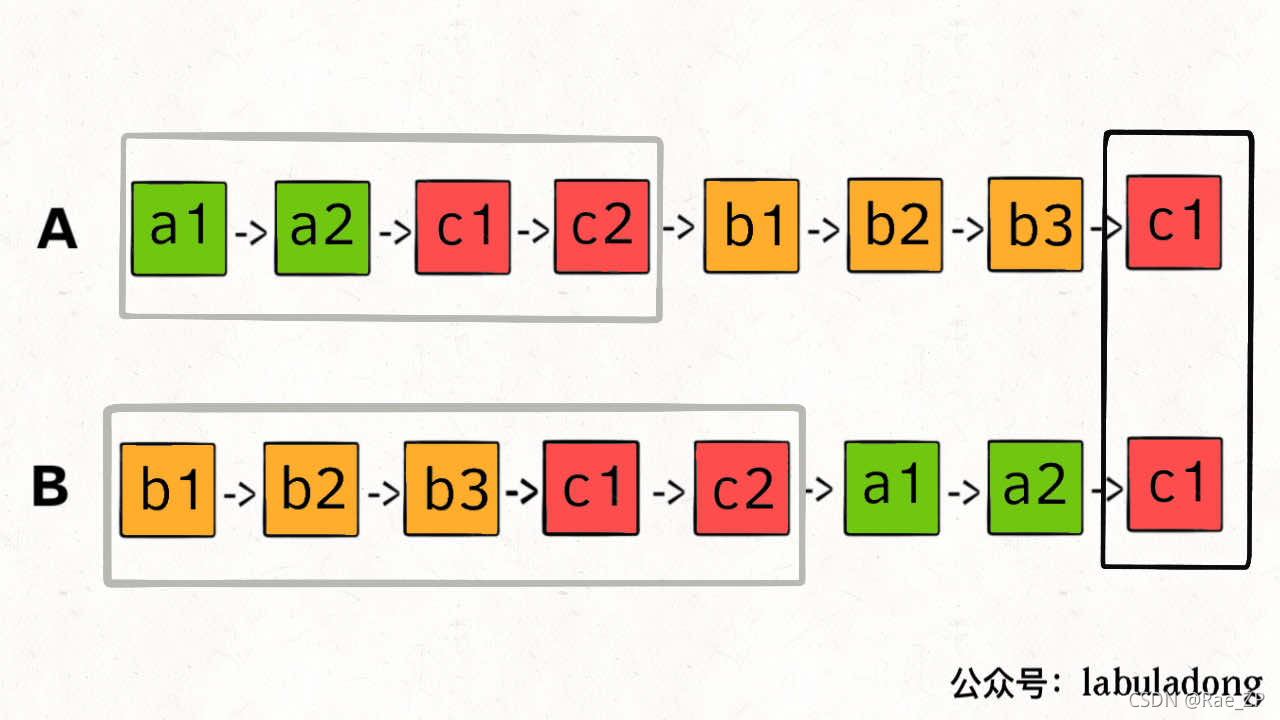
ListNode getIntersectionNode(ListNode headA, ListNode headB) {
// p1 指向 A 链表头结点,p2 指向 B 链表头结点
ListNode p1 = headA, p2 = headB;
while (p1 != p2) {
// p1 走一步,如果走到 A 链表末尾,转到 B 链表
if (p1 == null) p1 = headB;
else p1 = p1.next;
// p2 走一步,如果走到 B 链表末尾,转到 A 链表
if (p2 == null) p2 = headA;
else p2 = p2.next;
}
return p1;
}
那你可能会问,如果说两个链表没有相交点,是否能够正确的返回 null 呢?
这个逻辑可以覆盖这种情况的,相当于 c1 节点是 null 空指针嘛,可以正确返回 null。
2) 反转链表
1.反转整个链表
先看反转整个链表:
参考
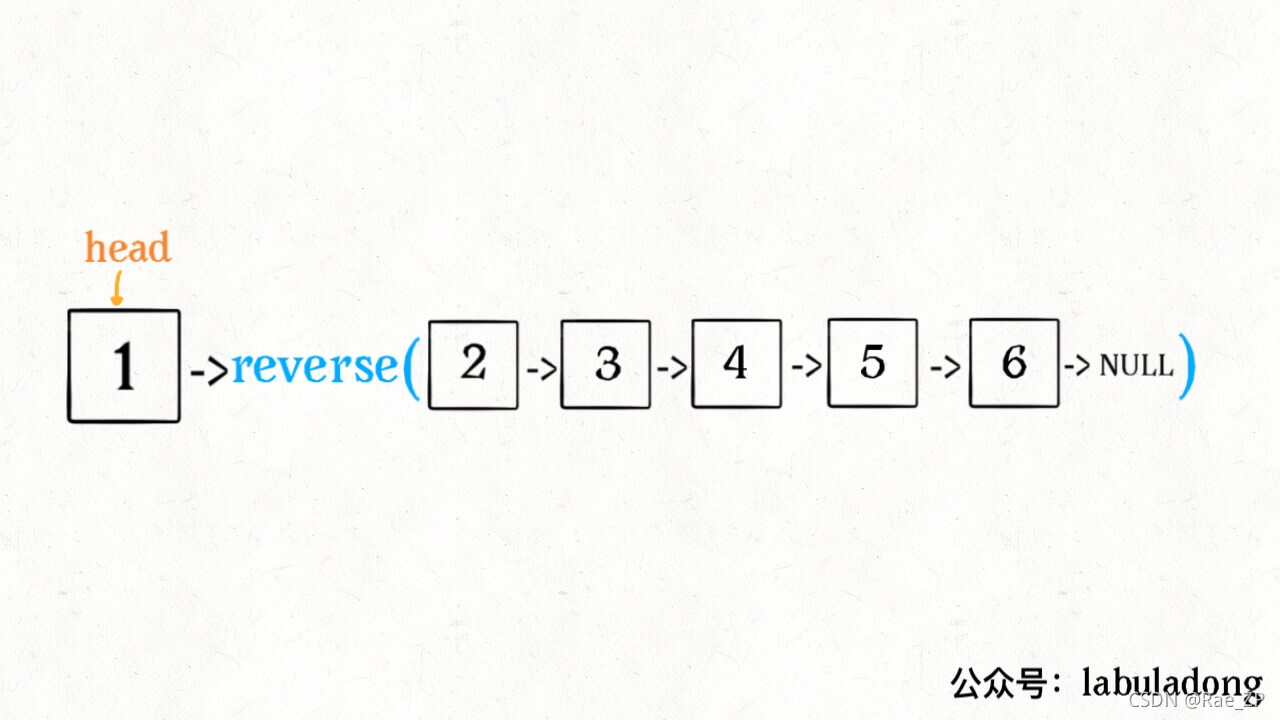
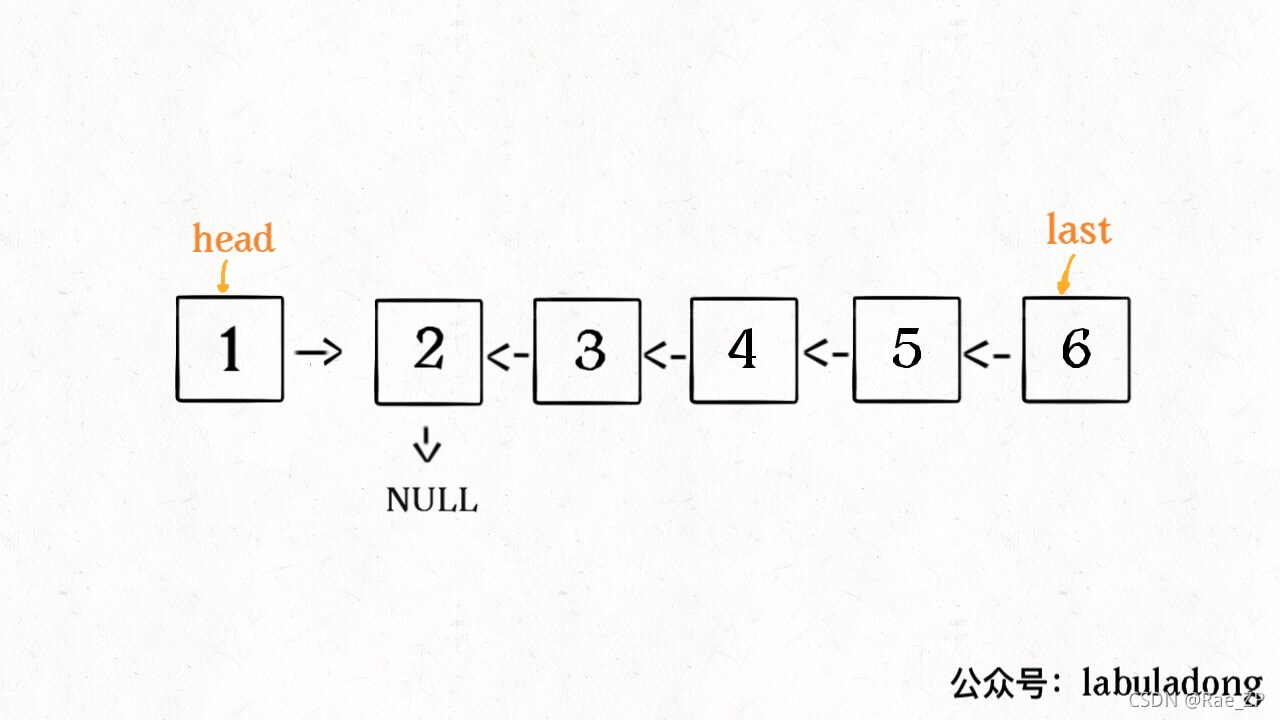
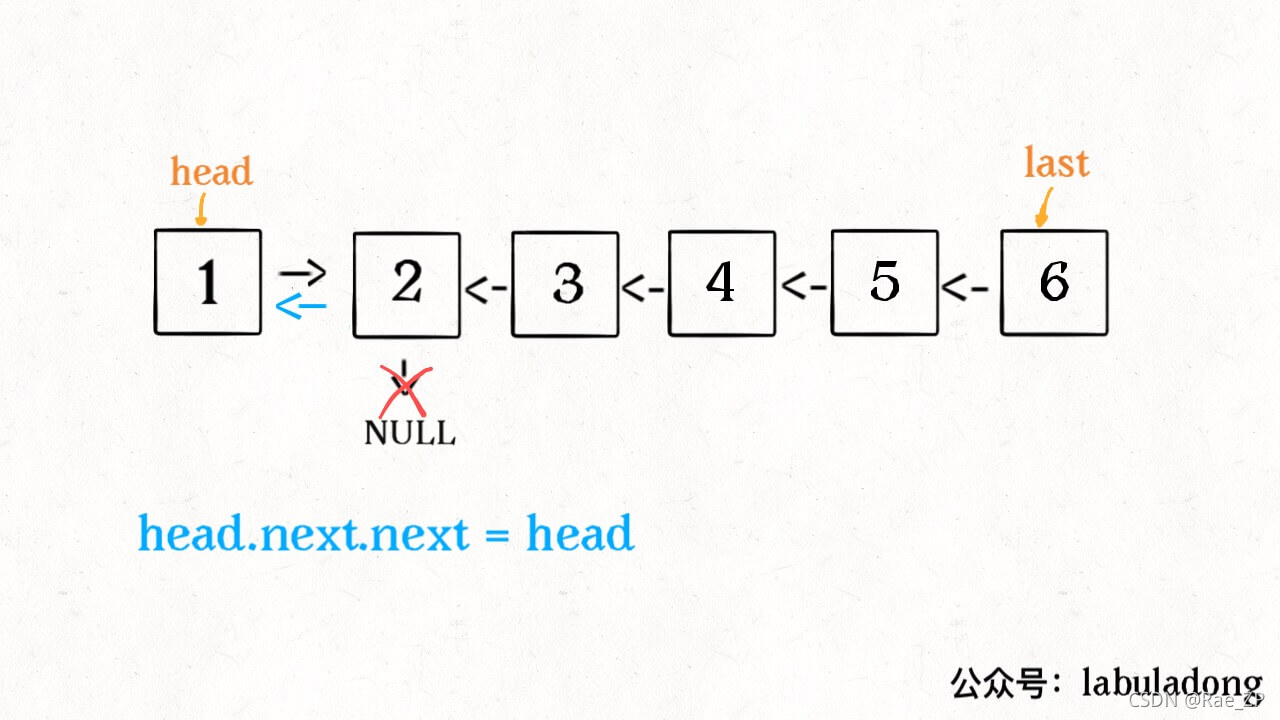
ListNode reverse(ListNode head) {
if (head.next == null) return head;
ListNode last = reverse(head.next);
head.next.next = head;
head.next = null;
return last;
}
2.反转前N个结点
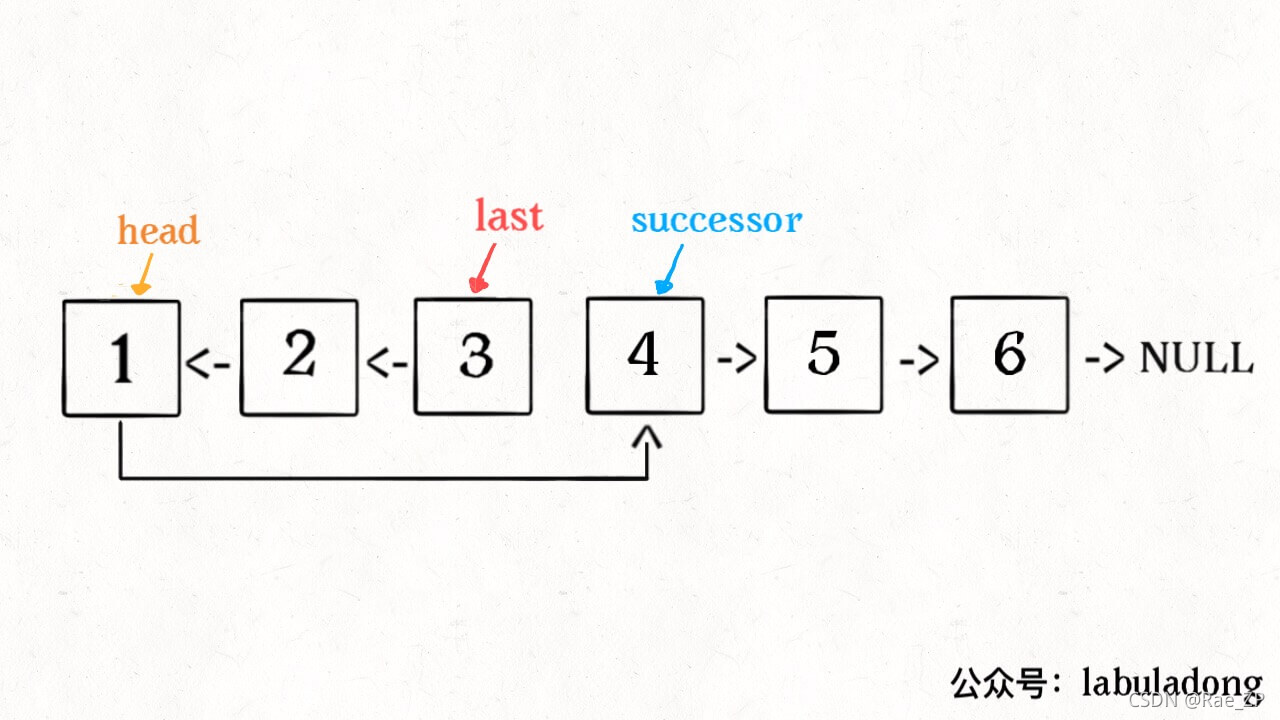
ListNode successor = null; // 后驱节点
// 反转以 head 为起点的 n 个节点,返回新的头结点
ListNode reverseN(ListNode head, int n) {
if (n == 1) {
// 记录第 n + 1 个节点
successor = head.next;
return head;
}
// 以 head.next 为起点,需要反转前 n - 1 个节点
ListNode last = reverseN(head.next, n - 1);
head.next.next = head;
// 让反转之后的 head 节点和后面的节点连起来
head.next = successor;
return last;
}
3. 反转链表的一部分
给一个索引区间 [m,n](索引从 1 开始),仅仅反转区间中的链表元素。
首先,如果 m == 1,就相当于反转链表开头的 n 个元素嘛,也就是我们刚才实现的功能:
ListNode reverseBetween(ListNode head, int m, int n) {
// base case
if (m == 1) {
// 相当于反转前 n 个元素
return reverseN(head, n);
}
// ...
}
如果 m != 1 怎么办?如果我们把 head 的索引视为 1,那么我们是想从第 m 个元素开始反转对吧;如果把 head.next 的索引视为 1 呢?那么相对于 head.next,反转的区间应该是从第 m - 1 个元素开始的;那么对于 head.next.next 呢……
区别于迭代思想,这就是递归思想,所以我们可以完成代码:
ListNode reverseBetween(ListNode head, int m, int n) {
// base case
if (m == 1) {
return reverseN(head, n);
}
// 前进到反转的起点触发 base case
head.next = reverseBetween(head.next, m - 1, n - 1);
return head;
}
4.k个一组反转链表
先看迭代反转 a 到 b 之间的结点
/** 反转区间 [a, b) 的元素,注意是左闭右开 */
ListNode reverse(ListNode a, ListNode b) {
ListNode pre, cur, nxt;
pre = null; cur = a; nxt = a;
// while 终止的条件改一下就行了
while (cur != b) {
nxt = cur.next;
cur.next = pre;
pre = cur;
cur = nxt;
}
// 返回反转后的头结点
return pre;
}
再看通过递归实现的k个一组反转链表:
里面用到了上面的反转区间【a, b】结点的函数
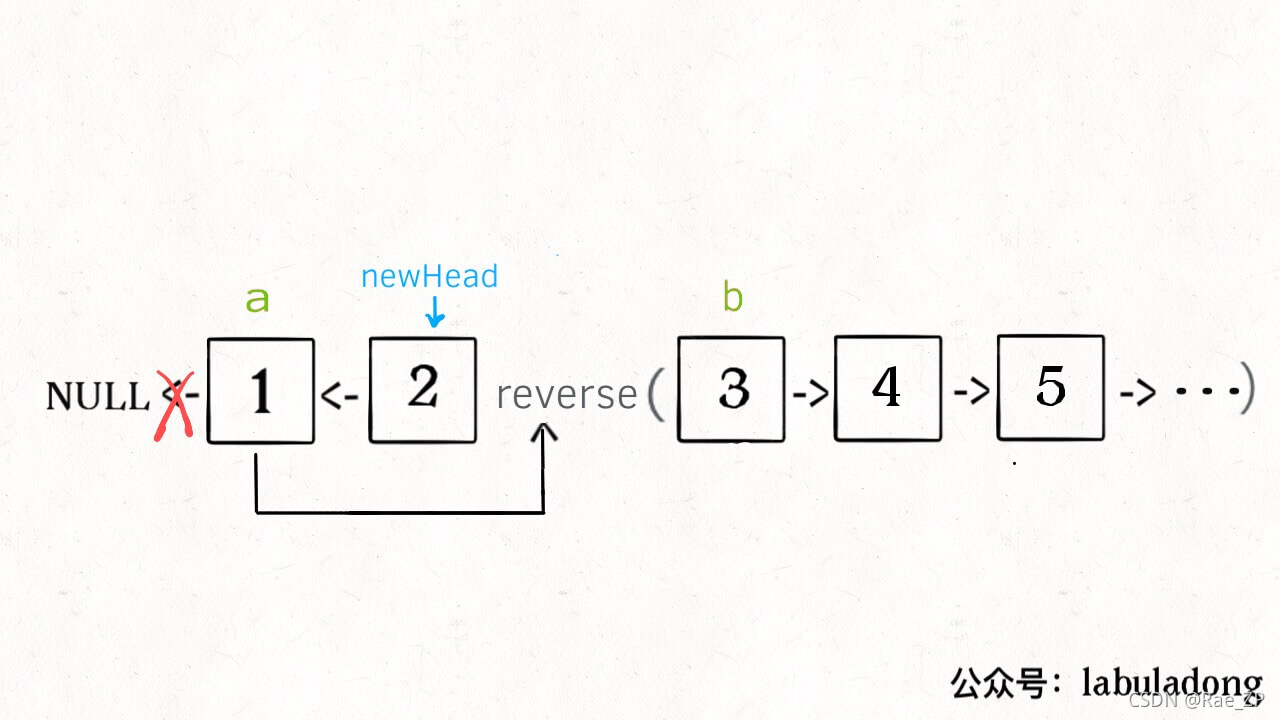
ListNode reverseKGroup(ListNode head, int k) {
if (head == null) return null;
// 区间 [a, b) 包含 k 个待反转元素
ListNode a, b;
a = b = head;
for (int i = 0; i < k; i++) {
// 不足 k 个,不需要反转,base case
if (b == null) return head;
b = b.next;
}
// 反转前 k 个元素
ListNode newHead = reverse(a, b);
// 递归反转后续链表并连接起来
a.next = reverseKGroup(b, k);
return newHead;
}
3)回文链表
1.寻找回文串
核心思想是从中心向两端扩展。
因为回文串长度可能为奇数也可能是偶数,长度为奇数时只存在一个中心点,而长度为偶数时存在两个中心点,所以这个函数需要传入l和r
string palindrome(string& s, int l, int r) {
// 防止索引越界
while (l >= 0 && r < s.size()
&& s[l] == s[r]) {
// 向两边展开
l--; r++;
}
// 返回以 s[l] 和 s[r] 为中心的最长回文串
return s.substr(l + 1, r - l - 1);
}
2.判断字符串是不是回文串
这就简单很多,不需要考虑奇偶情况,只需要「双指针技巧」,从两端向中间逼近即可:
bool isPalindrome(string s) {
int left = 0, right = s.length - 1;
while (left < right) {
if (s[left] != s[right])
return false;
left++; right--;
}
return true;
}
3.判断一个「单链表」是不是回文(3种方法)
方法1:
一般实现方式是通过将这个链表反转然后存成一个新的链表,然后同时遍历这两个链表,看看是不是一样,也就是原链表的正续和倒序是不是一样的。
方法2:
链表其实也可以有前序遍历和后序遍历,我们可以通过在递归中同时比较前序和后续的结点是不是一样的。
链表后续的框架:
void traverse(ListNode head) {
// 前序遍历代码
traverse(head.next);
// 后序遍历代码
}
通过上面的迭代思想,模仿双指针实现回文链表的判断:
// 左侧指针
ListNode left;
boolean isPalindrome(ListNode head) {
left = head;
return traverse(head);
}
boolean traverse(ListNode right) {
if (right == null) return true;
boolean res = traverse(right.next);
// 后序遍历代码
res = res && (right.val == left.val);
left = left.next;
return res;
}
无论造一条反转链表还是利用后序遍历,算法的时间和空间复杂度都是 O(N),怎样实现优化控件复杂度?
**方法3:
参考
思路:
1、先通过「双指针技巧」中的快慢指针来找到链表的中点
2.从slow开始反转后面的链表,现在就可以开始比较回文串了
3.判断完成,使用一行代码恢复原来的顺序
找到中间结点:
ListNode slow, fast;
slow = fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
// slow 指针现在指向链表中点
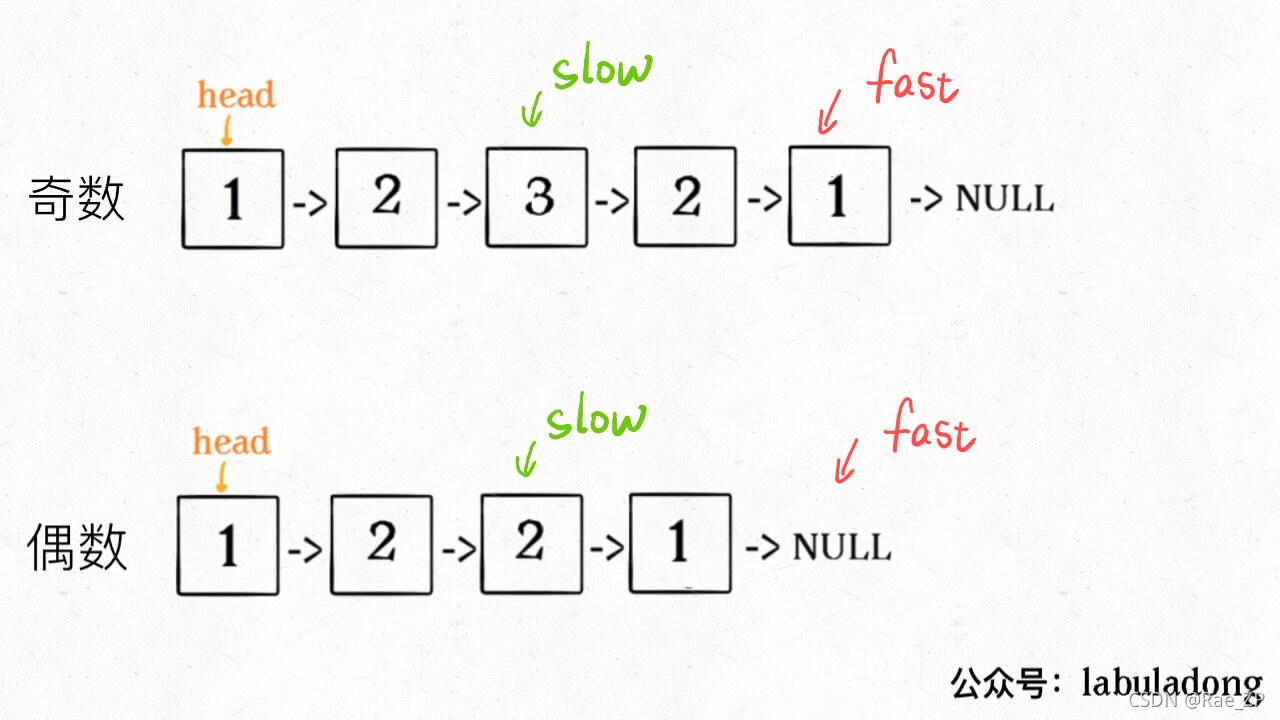
如果fast指针没有指向null,说明链表长度为奇数,slow还要再前进一步:
if (fast != null)
slow = slow.next;
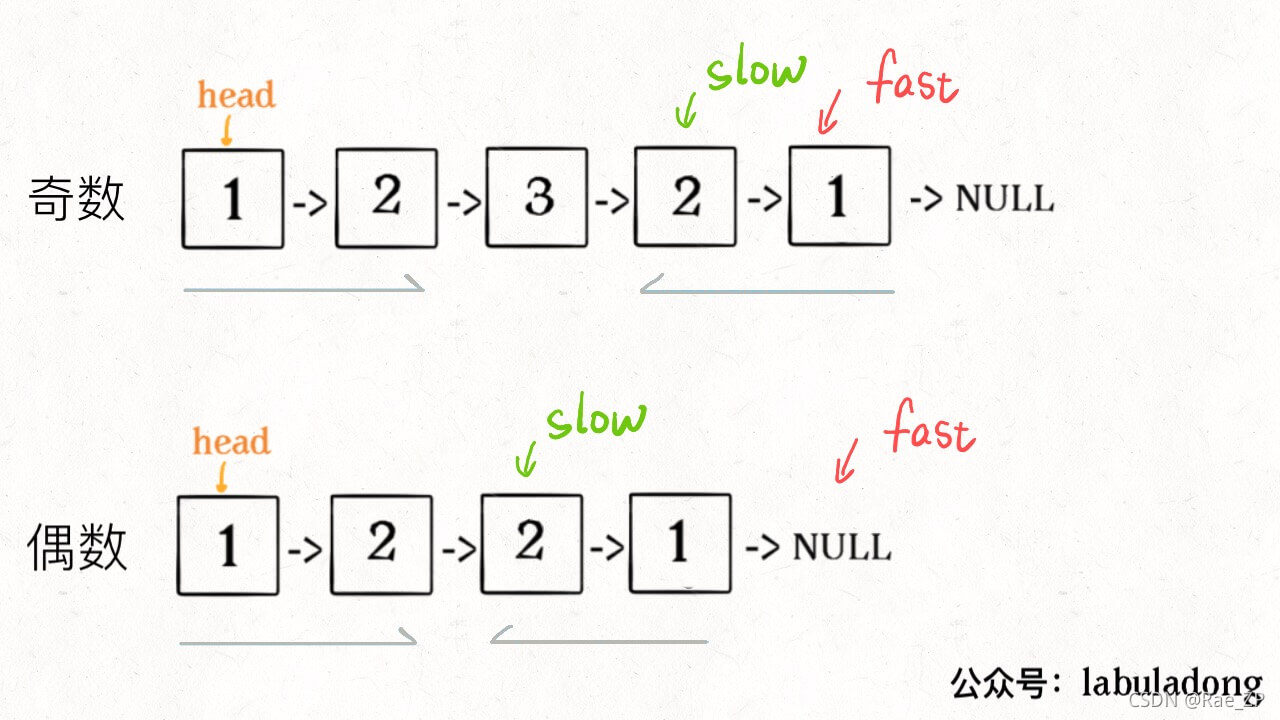
从slow开始反转后面的链表,现在就可以开始比较回文串了:
ListNode left = head;
ListNode right = reverse(slow);
while (right != null) {
if (left.val != right.val)
return false;
left = left.next;
right = right.next;
}
return true;
其中的reverse函数:
ListNode reverse(ListNode head) {
ListNode pre = null, cur = head;
while (cur != null) {
ListNode nxt = cur.next;
cur.next = pre;
pre = cur;
cur = nxt;
}
return pre;
}
只要在函数 return 之前加一段代码即可恢复原先链表顺序:
p.next = reverse(q);
算法总体的时间复杂度 O(N),空间复杂度 O(1),已经是最优的了。
6.图
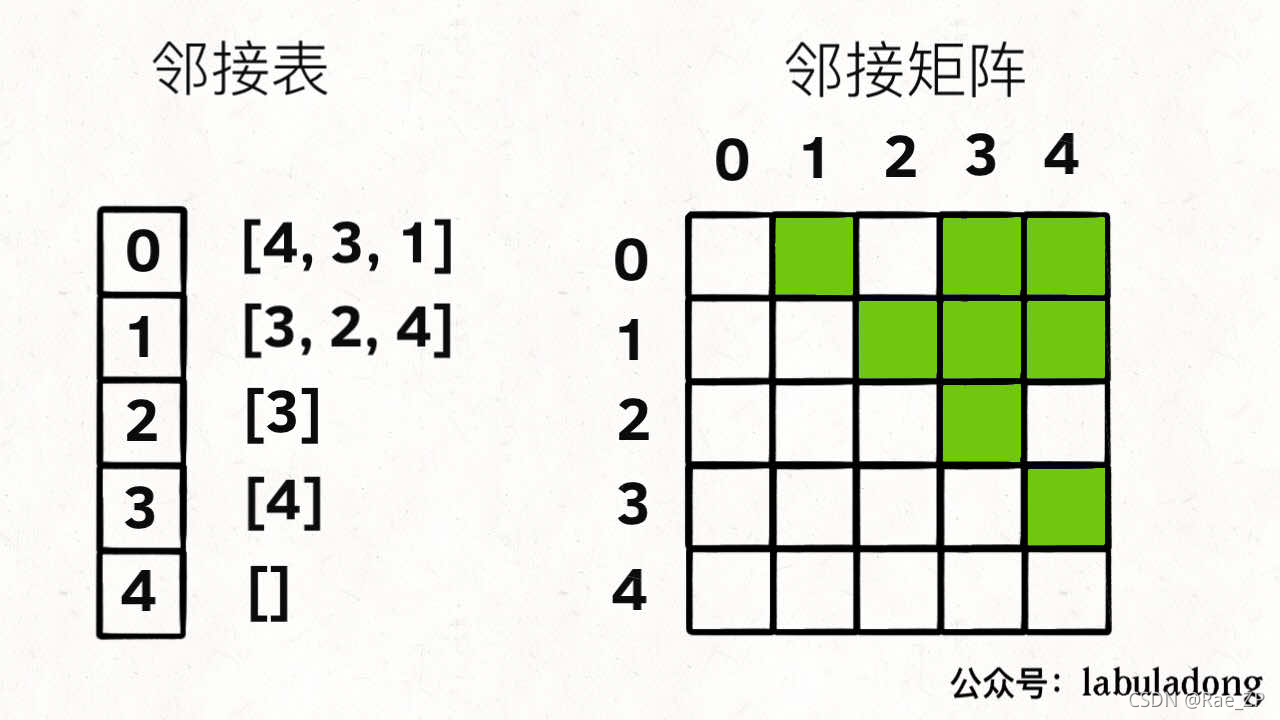
1.遍历图中所有结点
Graph graph;
boolean[] visited;
/* 图遍历框架 */
void traverse(Graph graph, int s) {
if (visited[s]) return;
// 经过节点 s
visited[s] = true;
for (TreeNode neighbor : graph.neighbors(s))
traverse(neighbor);
// 离开节点 s
visited[s] = false;
}
根据无环图的邻接表,返回所有路径情况<797题>
// 记录所有路径
List<List<Integer>> res = new LinkedList<>();
public List<List<Integer>> allPathsSourceTarget(int[][] graph) {
LinkedList<Integer> path = new LinkedList<>();
traverse(graph, 0, path);
return res;
}
/* 图的遍历框架 */
void traverse(int[][] graph, int s, LinkedList<Integer> path) {
// 添加节点 s 到路径
path.addLast(s);
int n = graph.length;
if (s == n - 1) {
// 到达终点
res.add(new LinkedList<>(path));
path.removeLast();
return;
}
// 递归每个相邻节点
for (int v : graph[s]) {
traverse(graph, v, path);
}
// 从路径移出节点 s
path.removeLast();
}
2.图中是否有环
// 记录一次 traverse 递归经过的节点
boolean[] onPath;
// 记录遍历过的节点,防止走回头路
boolean[] visited;
// 记录图中是否有环
boolean hasCycle = false;
boolean canFinish(int numCourses, int[][] prerequisites) {
List<Integer>[] graph = buildGraph(numCourses, prerequisites);
visited = new boolean[numCourses];
onPath = new boolean[numCourses];
for (int i = 0; i < numCourses; i++) {
// 遍历图中的所有节点
traverse(graph, i);
}
// 只要没有循环依赖可以完成所有课程
return !hasCycle;
}
void traverse(List<Integer>[] graph, int s) {
if (onPath[s]) {
// 出现环
hasCycle = true;
}
if (visited[s] || hasCycle) {
// 如果已经找到了环,也不用再遍历了
return;
}
// 前序遍历代码位置
visited[s] = true;
onPath[s] = true;
for (int t : graph[s]) {
traverse(graph, t);
}
// 后序遍历代码位置
onPath[s] = false;
}
//建图
List<Integer>[] buildGraph(int numCourses, int[][] prerequisites) {
// 图中共有 numCourses 个节点
List<Integer>[] graph = new LinkedList[numCourses];
for (int i = 0; i < numCourses; i++) {
graph[i] = new LinkedList<>();
}
for (int[] edge : prerequisites) {
int from = edge[1];
int to = edge[0];
// 修完课程 from 才能修课程 to
// 在图中添加一条从 from 指向 to 的有向边
graph[from].add(to);
}
return graph;
}
3. 拓扑排序
技巧:图的拓扑排序结果就是对应的邻接表的深度优先遍历的后续遍历的结果
4.名流问题
5.Dijstra求路径最短
参考
加权有向图,没有负权重边
Dijkstra 可以理解成一个带 dp table(或者说备忘录)的 BFS 算法,可以求出一个节点到其他各节点的最短路径长度。伪码如下:
// 返回节点 from 到节点 to 之间的边的权重
int weight(int from, int to);
// 输入节点 s 返回 s 的相邻节点
List<Integer> adj(int s);
// 输入一幅图和一个起点 start,计算 start 到其他节点的最短距离
int[] dijkstra(int start, List<Integer>[] graph) {
// 图中节点的个数
int V = graph.length;
// 记录最短路径的权重,你可以理解为 dp table
// 定义:distTo[i] 的值就是节点 start 到达节点 i 的最短路径权重
int[] distTo = new int[V];
// 求最小值,所以 dp table 初始化为正无穷
Arrays.fill(distTo, Integer.MAX_VALUE);
// base case,start 到 start 的最短距离就是 0
distTo[start] = 0;
// 优先级队列,distFromStart 较小的排在前面
Queue<State> pq = new PriorityQueue<>((a, b) -> {
return a.distFromStart - b.distFromStart;
});
// 从起点 start 开始进行 BFS
pq.offer(new State(start, 0));
while (!pq.isEmpty()) {
State curState = pq.poll();
int curNodeID = curState.id;
int curDistFromStart = curState.distFromStart;
if (curDistFromStart > distTo[curNodeID]) {
// 已经有一条更短的路径到达 curNode 节点了
continue;
}
// 将 curNode 的相邻节点装入队列
for (int nextNodeID : adj(curNodeID)) {
// 看看从 curNode 达到 nextNode 的距离是否会更短
int distToNextNode = distTo[curNodeID] + weight(curNodeID, nextNodeID);
if (distTo[nextNodeID] > distToNextNode) {
// 更新 dp table
distTo[nextNodeID] = distToNextNode;
// 将这个节点以及距离放入队列
pq.offer(new State(nextNodeID, distToNextNode));
}
}
}
return distTo;
}
完整:
class Solution {
public int networkDelayTime(int[][] times, int n, int k) {
// 节点编号是从 1 开始的,所以要一个大小为 n + 1 的邻接表
List<int[]>[] graph = new LinkedList[n + 1];
for (int i = 1; i <= n; i++) {
graph[i] = new LinkedList<>();
}
// 构造图
for (int[] edge : times) {
int from = edge[0];
int to = edge[1];
int weight = edge[2];
// from -> List<(to, weight)>
// 邻接表存储图结构,同时存储权重信息
graph[from].add(new int[]{to, weight});
}
// 启动 dijkstra 算法计算以节点 k 为起点到其他节点的最短路径
int[] distTo = dijkstra(k, graph);
// 找到最长的那一条最短路径
int res = 0;
for (int i = 1; i < distTo.length; i++) {
if (distTo[i] == Integer.MAX_VALUE) {
// 有节点不可达,返回 -1
return -1;
}
res = Math.max(res, distTo[i]);
}
return res;
}
class State {
// 图节点的 id
int id;
// 从 start 节点到当前节点的距离
int distFromStart;
State(int id, int distFromStart) {
this.id = id;
this.distFromStart = distFromStart;
}
}
// 输入一个起点 start,计算从 start 到其他节点的最短距离
int[] dijkstra(int start, List<int[]>[] graph) {
// 定义:distTo[i] 的值就是起点 start 到达节点 i 的最短路径权重
int[] distTo = new int[graph.length];
Arrays.fill(distTo, Integer.MAX_VALUE);
// base case,start 到 start 的最短距离就是 0
distTo[start] = 0;
// 优先级队列,distFromStart 较小的排在前面
Queue<State> pq = new PriorityQueue<>((a, b) -> {
return a.distFromStart - b.distFromStart;
});
// 从起点 start 开始进行 BFS
pq.offer(new State(start, 0));
while (!pq.isEmpty()) {
State curState = pq.poll();
int curNodeID = curState.id;
int curDistFromStart = curState.distFromStart;
if (curDistFromStart > distTo[curNodeID]) {
continue;
}
// 将 curNode 的相邻节点装入队列
for (int[] neighbor : graph[curNodeID]) {
int nextNodeID = neighbor[0];
int distToNextNode = distTo[curNodeID] + neighbor[1];
// 更新 dp table
if (distTo[nextNodeID] > distToNextNode) {
distTo[nextNodeID] = distToNextNode;
pq.offer(new State(nextNodeID, distToNextNode));
}
}
}
return distTo;
}
}
1.为什么要用 PriorityQueue 而不是 LinkedList 实现的普通队列?
如果你非要用普通队列,其实也没问题的,你可以直接把 PriorityQueue 改成 LinkedList,也能得到正确答案,但是效率会低很多。
Dijkstra 算法使用优先级队列,主要是为了效率上的优化,类似一种贪心算法的思路。
2.只关心起点 start 到某一个终点 end 的最短路径,怎样改代码?
// 输入起点 start 和终点 end,计算起点到终点的最短距离
int dijkstra(int start, int end, List<Integer>[] graph) {
// ...
while (!pq.isEmpty()) {
State curState = pq.poll();
int curNodeID = curState.id;
int curDistFromStart = curState.distFromStart;
// 在这里加一个判断就行了,其他代码不用改
if (curNodeID == end) {
return curDistFromStart;
}
if (curDistFromStart > distTo[curNodeID]) {
continue;
}
// ...
}
// 如果运行到这里,说明从 start 无法走到 end
return Integer.MAX_VALUE;
}
因为优先级队列自动排序的性质,每次从队列里面拿出来的都是 distFromStart 值最小的,所以当你从队头拿出一个节点,如果发现这个节点就是终点 end,那么 distFromStart 对应的值就是从 start 到 end 的最短距离。
这个算法较之前的实现提前 return 了,所以效率有一定的提高。
7.数组
1.田忌赛马
<870题>给你输入两个长度相等的数组 nums1 和 nums2,请你重新组织 nums1 中元素的位置,使得 nums1 的「优势」最大化。
将齐王和田忌的马按照战斗力排序,然后按照排名一一对比。如果田忌的马能赢,那就比赛,如果赢不了,那就换个垫底的来送人头,保存实力。
上述思路的代码逻辑如下:
int[] advantageCount(int[] nums1, int[] nums2) {
int n = nums1.length;
// 给 nums2 降序排序
PriorityQueue<int[]> maxpq = new PriorityQueue<>(
(int[] pair1, int[] pair2) -> {
return pair2[1] - pair1[1];
}
);
for (int i = 0; i < n; i++) {
maxpq.offer(new int[]{i, nums2[i]});
}
// 给 nums1 升序排序
Arrays.sort(nums1);
// nums1[left] 是最小值,nums1[right] 是最大值
int left = 0, right = n - 1;
int[] res = new int[n];
while (!maxpq.isEmpty()) {
int[] pair = maxpq.poll();
// maxval 是 nums2 中的最大值,i 是对应索引
int i = pair[0], maxval = pair[1];
if (maxval < nums1[right]) {
// 如果 nums1[right] 能胜过 maxval,那就自己上
res[i] = nums1[right];
right--;
} else {
// 否则用最小值混一下,养精蓄锐
res[i] = nums1[left];
left++;
}
}
return res;
}
为了记住nums2中排序完元素的下标,采用的办法是将一个数组存到优先队列,在数组的第一列元素表示的就是元素的下标,这样即使排序完我们还是能知道它原来的顺序。
2)二分搜索
1.基本二分搜索
采用[left,right]闭区间的方式
int binarySearch(int[] nums, int target) {
int left = 0;
int right = nums.length - 1; // 注意
while(left <= right) {
int mid = left + (right - left) / 2;//防止溢出
if(nums[mid] == target)
return mid;
else if (nums[mid] < target)
left = mid + 1; // 注意
else if (nums[mid] > target)
right = mid - 1; // 注意
}
return -1;
}
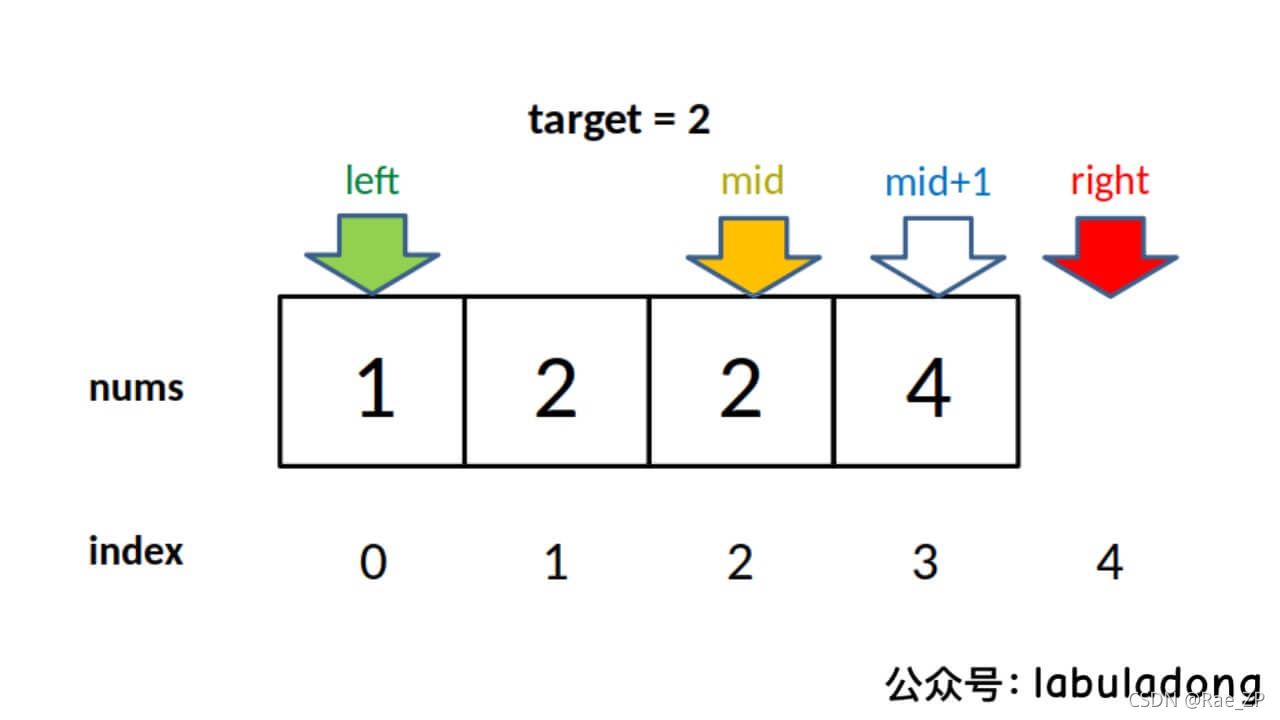
2.寻找左侧边界的二分搜索
nums = [1,2,2,2,3],target 为 2,此算法返回的索引是 2,没错。但是如果我想得到 target 的左侧边界,即索引 1。
以下是最常见的代码形式,其中的标记是需要注意的细节:
如果采用闭区间的方式
int left_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
// 搜索区间为 [left, right]
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
// 搜索区间变为 [mid+1, right]
left = mid + 1;
} else if (nums[mid] > target) {
// 搜索区间变为 [left, mid-1]
right = mid - 1;
} else if (nums[mid] == target) {
// 收缩右侧边界
right = mid - 1;
}
}
// 检查出界情况
if (left >= nums.length || nums[left] != target)
return -1;
return left;
}
采用开区间的方式:
int left_bound(int[] nums, int target) {
if (nums.length == 0) return -1;
int left = 0;
int right = nums.length; // 注意
while (left < right) { // 注意
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
right = mid;
} else if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid; // 注意
}
}
// target 比所有数都大
if (left == nums.length) return -1;
// 类似之前算法的处理方式
return nums[left] == target ? left : -1;
}
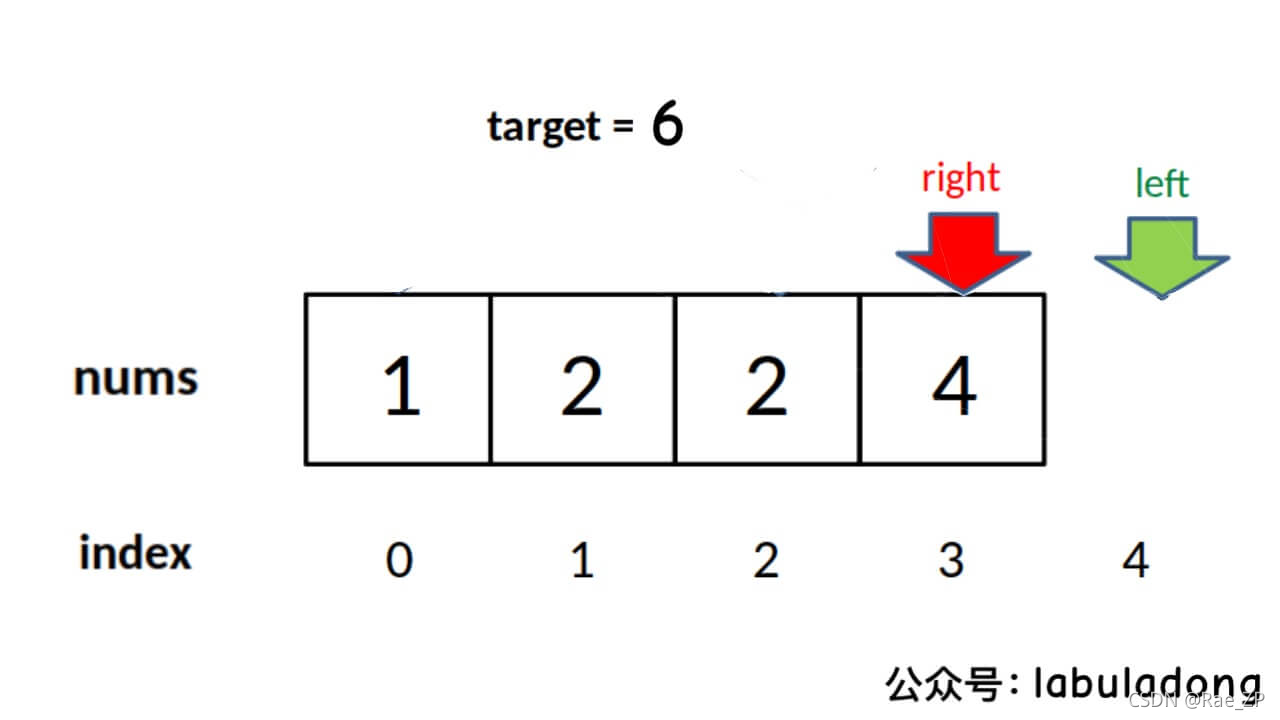
3.寻找右侧边界的二分查找
类似寻找左侧边界的算法,这里也会提供两种写法,还是先写常见的左闭右开的写法,只有两处和搜索左侧边界不同,已标注:
采用闭区间的方式
int right_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if (nums[mid] == target) {
// 这里改成收缩左侧边界即可
left = mid + 1;
}
}
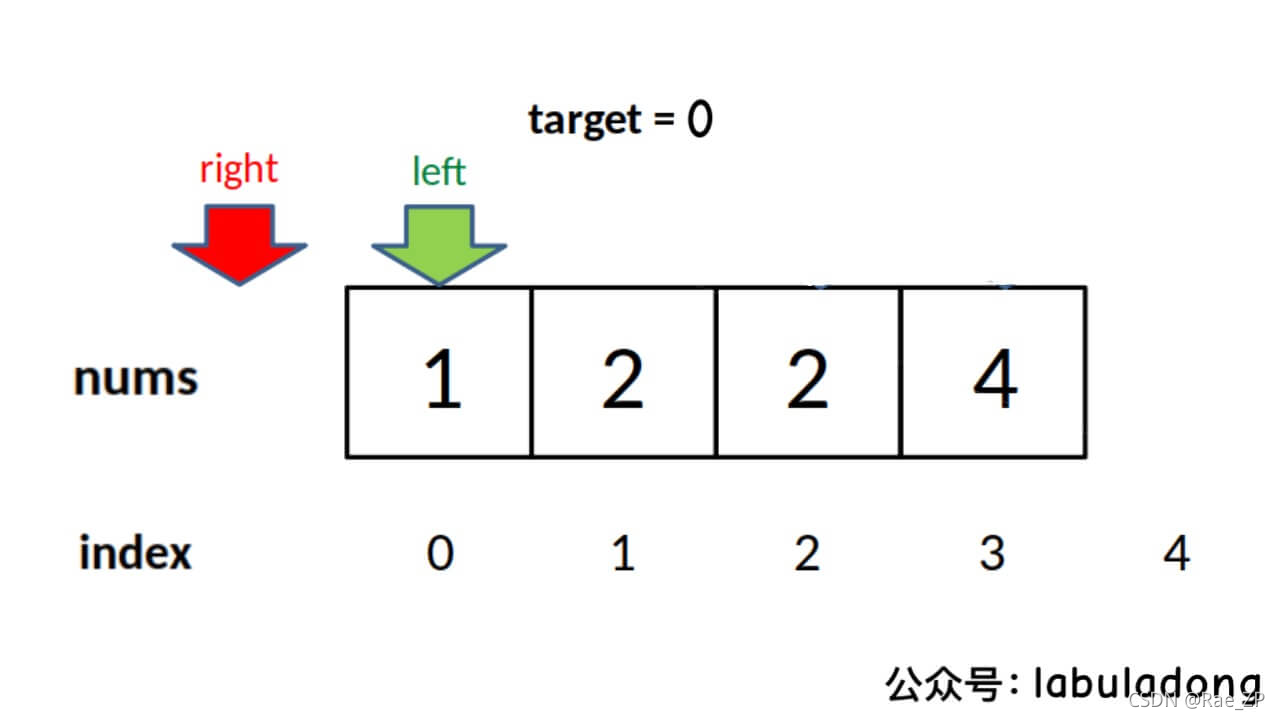
// 这里改为检查 right 越界的情况,见下图
if (right < 0 || nums[right] != target)
return -1;
return right;
}
采用开区间的方式
int right_bound(int[] nums, int target) {
if (nums.length == 0) return -1;
int left = 0, right = nums.length;
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
left = mid + 1; // 注意
} else if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid;
}
}
if (left == 0) return -1;
return nums[left-1] == target ? (left-1) : -1;
}
3)原地修改数组
1.单调栈模板(解决Next Greater Number问题)
题目:得到每一个数组元素后面第一个大于它的元素,如果没有就是-1
思想:从后往前算,先算数组后面的元素,从后面依次往前算。
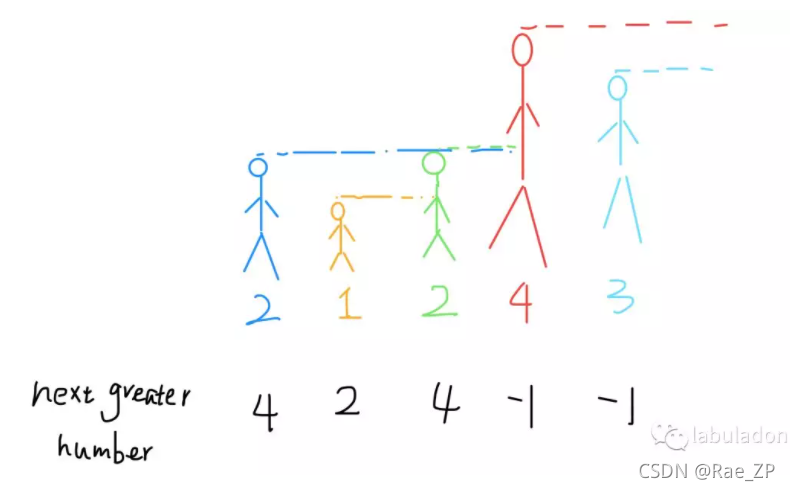
vector<int> nextGreaterElement(vector<int>& nums) {
vector<int> ans(nums.size()); // 存放答案的数组
stack<int> s;
for (int i = nums.size() - 1; i >= 0; i--) { // 倒着往栈里放
while (!s.empty() && s.top() <= nums[i]) { // 判定个子高矮
s.pop(); // 矮个起开,反正也被挡着了。。。
}
ans[i] = s.empty() ? -1 : s.top(); // 这个元素身后的第一个高个
s.push(nums[i]); // 进队,接受之后的身高判定吧!
}
return ans;
}
8.子序列->动态规划
1)最长子序列 300题

















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









