




一、确定关键检索词。
1、在看文献之前,首先需要明确我们的研究方向,再进行主题分析。“主题”即为文献或检索课题所论述的、研究的具体对象或问题,就是我们通常说的中心内容。而主题的确定一般是导师希望你做的课题方向或者自己感兴趣的方面。
2、明确了我们要研究方向后,下一步我们要做的是确定检索关键词。这里举例说明,假设我们要做的大方向是“社区公园”,通过有道翻译、百度翻译等中英互译软件,我们可以得到community park或者neighborhood park或者neighborhood garden。
因为东西方文化的差异,会得到不同的翻译结果,这些翻译结果均可以作为我们检索时所用到的词汇。
如果研究范围缩小,例如研究主题为“城市社区公园公平性分析”。那我们可以通过以下方法确定检索词:
1)多概念主题分解法:城市社区公园公平性分析有道词典中翻译为Fairness analysis of urban community park,分解为城市社区公园+公平性,所以检索词可以为urban community park| neighborhood park| neighborhood garden + fairness|equity| justification。
2)主题转换法,这是在确定检索词中我们最常用到的方法。城市社区公园公平性分析主要关键词为城市社区公园+公平性,公平性可以转换为公正性或可达性,即unprejudiced| impartiality| accessibility
3)词性的转换,在英文中相同含义的词有复数形式、动名词、形容词等形式,这时我们可以转换词性进行检索,例如equity—equities—equitable—equal—equitableness。
二、选文献
在确定好关键检索词后,我们下一步要进行查文献和下文献。
1、现阶段我们常用到的文献检索网站,一般从学校图书馆入口进找WOS(Web of science)端口,输入关键词进行文献查找。
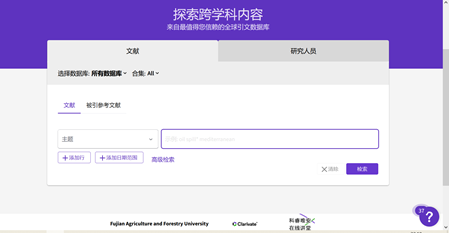
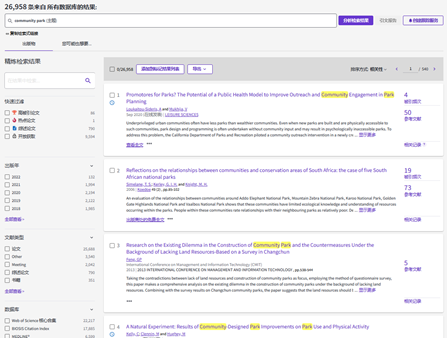
2、在WOS网站中输入关键检索词后,会出现很多的文章,那如何选择有用文献呢?泛读(阅读题目和摘要,筛选出感兴趣或对自己研究领域有用的论著)。
确定一篇论文是否与我们研究方向相同,只要了解题目和摘要即可。与我们研究方向相同的文章我们都可以下载下来进行快速阅读。
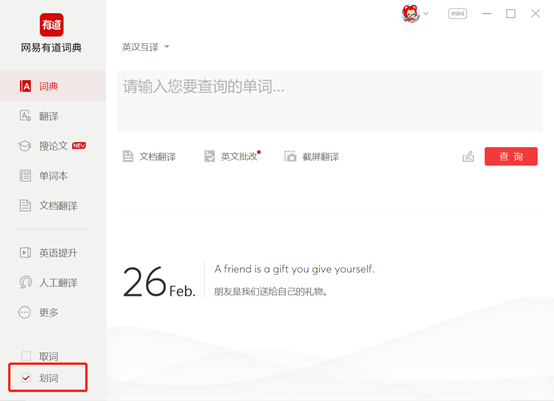
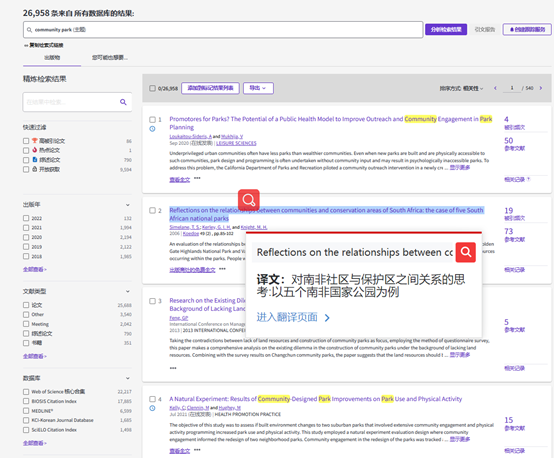
这里,我们介绍有道词典软件中十分有用的一个功能“划词”,就可以快速得到中文翻译。
3、Ps拓展知识:我们怎么知道这篇论文的质量如何呢?一般来说期刊层级决定文章质量,那如何了解杂志层次呢?
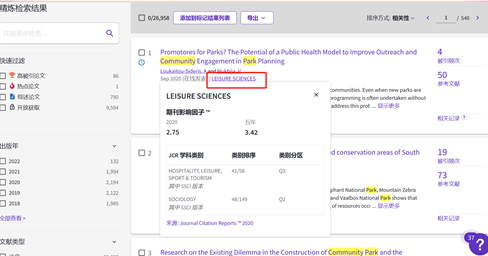
在文章题目的下方会有期刊名称,点击后即可显示文章的JCR分区(国外常用期刊分区),通常我们要选择Q1、Q2的文章阅读;
或者搜索微信小程序“中科院文献情报中心分区表”,输入期刊名或者ISSN号,即可显示中科院分区(国内常用期刊分区),因为我国科研成果一般认定为3区及以上的文章,所以通常下载1区2区期刊的文章进行学习。
三、下文献
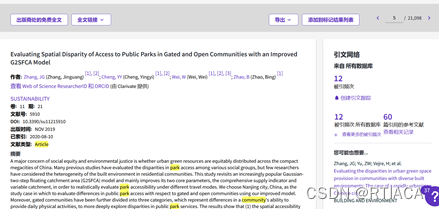
在WOS中,点击文章题目出现“出版商处的免费全文”即可下载全文。但有时WOS下载不了全文时,这就需要文章中的DOI号码或文章名称到OA图书馆网站或者pub med网站或者Geenmedical网站,进行查找也可以下载全文。

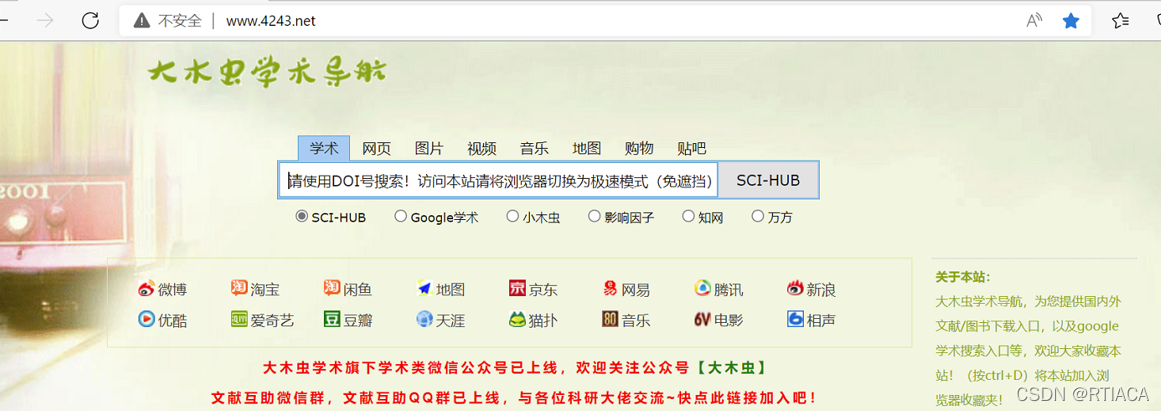
这里我们再介绍一个神奇的网站——大木虫学术导航,这里是各种学术网站的汇总,不仅有文献下载,还有课题申请,文献翻译,在线降重等。
Ps:这里注意下载的文章一般为pdf格式,这有助于我们下一步的精读。
四、读文献
1、先泛读(通过快速翻译全文,确定文章与研究方向的相关度)。
我们下载了很多文献,但如何确定一篇文章需不需要精读呢?这需要我们了解文章中文意思。
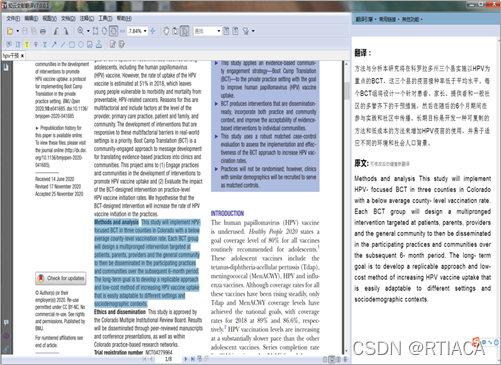
可以使用有道词典软件的划词功能,但有时在大段落翻译时它会出现卡顿现象,所以这里我们再介绍一款好用的全免费的翻译软件“知云文献翻译”软件。在软件中直接打开文献进行划词翻译。
Ps:有道云软件只能打开pdf或者doc格式的文件。
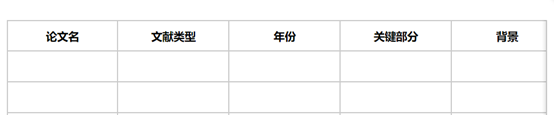
在泛读过程中,我们还可以利用表格记录,确定每篇文章我们可以学习的地方是什么,启示是什么。表格中重点写好“论文名”以及“关键部分”,方便以后文献查找以及让我们快速回忆出文章的启示点是什么。
2、后精读
在大段落划取翻译后,我们基本可以确定1-3篇与我们研究方向高度贴合的文章,对这些文章我们需要逐字逐句细细的品读。这里使用有道云软件或知云文献翻译软件均可,顺手方便即可。
在精读文章的过程中,首先我们要列出文章的课题框架,学习文章的逻辑关系,研究其西方的写作套路,然后进行模仿进而超越。若有意向的期刊,我们还可以登录期刊的官网仔细研究下投稿须知等。
五、总结
以上,便是查、选、下、读英文文章的步骤。各位同学刚开始看英文论文的时候肯定会有很多问题,例如不适应WOS界面设置,下载不了文章,看不同文章意思,不会使用翻译软件等等等。但我们要坚定信心,坚持阅读!只要多读、多看、多学,英文文献对于我们也是小菜一碟!
看英文文献的几点要素:
1. 确定关键检索词
2. 选文献
3. 下文献
4. 看文献
5. 总结

















 174
174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









