



注:该内容由“数模加油站”原创,无偿分享,可以领取参考但不要利用该内容倒卖,谢谢!
A 题 智慧工厂工业设备传感器数据分析
初赛任务A:机床设备故障预测回归分析问题 使用机器编号、机器类型、运行小时数、温度、振动、声音、油位、冷却液位、功耗、距 上次维护天数、维护历史次数、故障历史次数、人工智能监控、过去30天错误编码等特征,构 建回归模型,预测机床设备在7天内是否会发生故障。要求输出模型准确率、召回率、F1值,并 分析前5个最重要的特征。
初赛任务B:剩余使用寿命预测回归分析问题 在不使用目标标签(7天内故障预测)的情况下,基于剩余使用寿命(天)、运行小时数、 温度、振动、油位、冷却液位、维护历史次数、故障历史次数等特征,构建回归模型,预测机 床设备的剩余使用寿命(目标为连续值)。要求输出模型的均方误差(MSE)和决定系数(R²) 并分析特征重要性对剩余寿命的影响
对于这两个问题,首先需要做好数据的预处理和特征选择,确保输入数据质量高且对目标变量有较好的预测能力。在选择模型时,可以从简单的回归模型入手,逐步引入复杂模型(如随机森林、XGBoost、SVR等)。评估模型时,需要使用合适的回归指标,如准确率、召回率、F1值等来评估故障预测任务,而使用均方误差和R²来评估剩余使用寿命预测任务。
问题1
问题1思路框架:
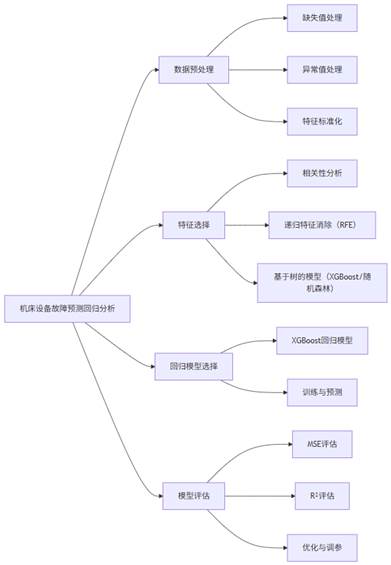
数学模型构建:
1. 数据预处理
数据预处理是任何机器学习任务中的关键步骤,直接影响到模型的表现。
1.1 缺失值处理
数值型特征(如温度、功耗等)的缺失值可以用 均值填充 或 中位数填充。选择均值填充是因为大部分特征应该围绕某个中心值分布,均值作为一个较好的估计。
对于 类别型特征(如机器类型),可以使用 众数填充,即填充该特征的最常见值。
1.2 异常值处理
Z-score 方法用于检测异常值。Z-score反映了一个数据点距离均值的标准差。如果Z-score大于3,通常认为该点是异常值。
其中, 是均值,
是标准差。
异常值可能会影响模型训练的稳定性,通常可以将异常值剔除或替换。
1.3 数据标准化
为了确保各个特征在相同的尺度上进行比较,通常需要对数值型特征进行标准化,特别是当使用距离度量或者对模型训练时间较为敏感的模型时。
标准化公式:
1.4 特征工程
- 特征构造:可以结合现有特征构造新的特征。例如,可以计算 温度和振动的交互项,以反映设备状态变化的潜在关联。
- 类别特征编码:如机器类型等可以通过 独热编码(One-Hot Encoding) 转换为数值特征。
2. 特征选择
特征选择是减少模型复杂性、提高性能和避免过拟合的重要步骤。在此任务中,我们有多个传感器数据和设备历史记录特征,我们需要从中选择对预测故障最为相关的特征。
2.1 相关性分析
目标:初步筛选特征。通过计算各特征与目标变量(是否故障)的相关性,去除与目标变量相关性低的特征。
使用皮尔逊相关系数(Pearson correlation)来评估特征与目标之间的线性相关性。
其中, 是特征 X 与目标 Y 的协方差,
和
是它们的标准差。
相关性分析帮助我们快速去除无关特征,避免后续算法在冗余特征上浪费计算资源。
2.2 递归特征消除(RFE)
目标:在数据集较为复杂时,递归特征消除(RFE)可以进一步优化特征选择。
方法:
-
- RFE通过训练回归模型,并逐步去除不重要的特征,最终保留最具预测能力的特征。
- 每次训练一个基学习器(例如线性回归),评估每个特征的重要性,然后递归地移除最不重要的特征,直到保留最重要的特征。
- 适用场景:如果数据集特征之间存在复杂的非线性关系或交互作用,RFE能够帮助我们从中挖掘出最有用的特征。
2.3 基于树的模型(XGBoost)
目标:使用树模型(如XGBoost或随机森林)对特征的重要性进行排序。这些模型在评估特征重要性时能够有效处理非线性关系。
方法:
训练一个随机森林回归或XGBoost回归模型,这些模型能够自动评估每个特征的贡献并计算特征重要性。
特征重要性通常基于信息增益或基尼指数(用于决策树的分裂标准)。
XGBoost的特征重要性评估:
优点:随机森林和XGBoost能够处理非线性关系,适合复杂的设备故障预测问题,并且能够自动计算和筛选特征。
3. 构建XGBoost回归模型
在特征选择后,我们可以使用 XGBoost 来构建回归模型。XGBoost是一种基于梯度提升树的集成学习算法,适用于复杂的非线性数据。
3.1 初始化XGBoost模型
选择XGBoost作为回归模型,因为它能够处理复杂的特征交互,适合本任务中的设备故障预测问题。XGBoost模型的常见参数包括:
n_estimators:树的数量。
max_depth:每棵树的最大深度。
learning_rate:学习率,用于控制每棵树的贡献。
切分数据集为训练集和测试集。
XGBoost回归公式:
- XGBoost通过加权的决策树集成来做回归,损失函数为:
其中,是回归损失函数,
是树的复杂度(例如树的叶子数、分裂点的数量),m是样本数,
是预测值。
3.2 模型预测
模型训练完成后,我们可以使用测试集进行预测。
3.3 模型评估
使用 均方误差(MSE) 和 决定系数(R²) 来评估回归模型的性能。
均方误差(MSE) 衡量预测值与实际值之间的平均误差。
决定系数(R²) 衡量模型对数据方差的解释能力。
3.4 模型性能分析
均方误差(MSE)越小,表示模型的预测误差越小。
R² Score接近1时,表示模型能够很好地拟合数据,解释能力强;接近0则表示模型表现不佳
Python代码:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.metrics import mean_squared_error, r2_score
import xgboost as xgb
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
from scipy.stats import zscore
# 数据加载
data = pd.read_csv('train_data.csv') # 用实际数据路径
# 提取特征和目标变量
X = data.drop(columns=['Failure_Within_7_Days']) # 特征
y = data['Failure_Within_7_Days'] # 目标变量
# 处理缺失值
imputer = SimpleImputer(strategy='mean')
X_imputed = imputer.fit_transform(X)
# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_imputed)
# 检查异常值(使用Z-score方法)
Z = zscore(X_scaled)
X_no_outliers = X_scaled[(Z < 3).all(axis=1)] # 删除异常值
y_no_outliers = y[(Z < 3).all(axis=1)] # 删除对应的y
# 切分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_no_outliers, y_no_outliers, test_size=0.2, random_state=42)
# 相关性分析
correlation_matrix = pd.DataFrame(X_scaled).corr()
plt.figure(figsize=(12, 8))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.show()
# 递归特征消除(RFE)
model = LinearRegression()
selector = RFE(model, n_features_to_select=5)
X_rfe = selector.fit_transform(X_train, y_train)
# 输出选择的特征
print("Selected features from RFE:", X_train.columns[selector.support_])
# 基于XGBoost的特征选择
xgb_model = xgb.XGBRegressor(objective='reg:squarederror', n_estimators=100, max_depth=6, learning_rate=0.1)
xgb_model.fit(X_train, y_train)
# 获取特征重要性
importance = xgb_model.feature_importances_
# 可视化特征重要性
sns.barplot(x=importance, y=X.columns)
plt.title("Feature Importance from XGBoost")
plt.show()
# 使用XGBoost进行训练和预测
xgb_model.fit(X_train, y_train)
y_pred = xgb_model.predict(X_test)
# 模型评估
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
print(f"R² Score: {r2}")
后续都在“数模加油站”......

















 5096
5096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









