







对于需要寻找某个值的出现次数,可以使用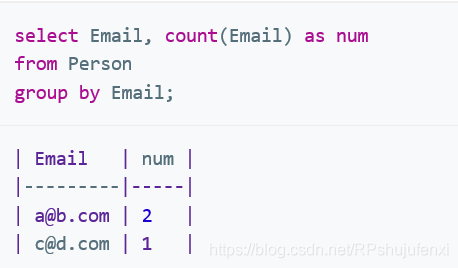
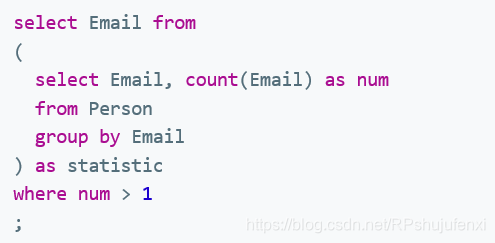
查询出现重复次数,并返回该Email
select distinct Email
from Person
where Email
in
(select Email
from Person
group by Email
having count(Email)>1)也可以采用临时表的方式:
注意:group by 只是查询结果去重,并不是真的删掉了重复的记录
优先顺序
where>group by>having>order by

注意:学生在每个课中不应被重复计算
select distinct class
from courses
group by class
having count(distinct student)>=5group by按照课程排序,having count计算的是每个课程学生的数量,所以要在having count的括号里加上distinct student
!!!having count指表中所有数,而不能表示出连续出现的数

select distinct Lg1.Num as ConsecutiveNums
from Logs lg1,Logs lg2,Logs lg3
where lg1.Id=lg2.Id+1 and lg1.Num=lg2.Num
and lg2.Id=lg3.Id+1 and lg2.Num=lg3.NumSQL 语句的执行顺序跟其语句的语法顺序并不一致
一般而言
SQL 语句的语法顺序是:
SELECT[DISTINCT]
FROM
WHERE
GROUP BY
HAVING
UNION
ORDER BY
其执行顺序为:
FROM
WHERE
GROUP BY
HAVING
SELECT
DISTINCT
UNION
ORDER BY
需要注意的是:
1、 FROM 才是 SQL 语句执行的第一步。数据库在执行SQL 语句的第一步是将数据从硬盘加载到数据缓冲区中,以便对这些数据进行操作。
2、SELECT 是在大部分语句执行了之后才执行的,严格的说是在 FROM 和 GROUP BY 之后执行的。这就是你不能在 WHERE 中使用在 SELECT 中设定别名的字段作为判断条件的原因。
3、并非所有SQL都按照上述的顺序进行。


















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









