






 探讨在一棵完全二叉树中,多个小球依次落下并受开关控制左右路径的问题,通过分析小球编号与路径的关系,给出了一种直接模拟最后一个小球落地位置的方法。
探讨在一棵完全二叉树中,多个小球依次落下并受开关控制左右路径的问题,通过分析小球编号与路径的关系,给出了一种直接模拟最后一个小球落地位置的方法。
题目链接
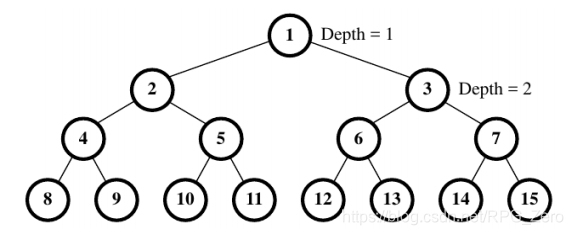
题目大意:一棵完全二叉树,最大深度为D,所有结点从上到下从左到右编号为1,2,3,…,2D-1 在结点1处放一个小球,它会往下落。每个内结点上都有一个开关,初始状态全为关,球经过开关,开关状态改变。每个球从根结点往下掉,若开关关闭,则往左走,否则往右走。现有t个小球依次向下落,求最后一个小球落在了哪个叶子结点上。
Sample Input
5
4 2
3 4
10 1
2 2
8 128
-1
Sample Output
12
7
512
3
255
解题思路:
紫书上二叉树第一题,二叉树的编号。
对小球从1到t进行编号,考虑最后一个小球t,当t为奇数时,它是往左走的第(t+1)/2个小球;当t为偶数时,它是往右走的第t/2个小球。这样,就可以直接模拟最后一个小球的路线。
重要结论:
给定一棵包含2d个结点(其中d为树的高度)的完全二叉树,如果把结点从上到下从左到右编号为1,2,3…,则结点k的左右子结点的编号分别为 2*k 和 2*k+1
AC代码:
#include<iostream>
using namespace std;
int main() {
int l, d, t;
while (cin >> l) {
if (l == -1) break;
for (int i = 1; i <= l; i++) {
cin >> d >> t;
int k = 1;
for (int j = 1; j < d; j++) {
if (t % 2 == 0) {
t = t / 2;
k = 2 * k + 1;
}
else {
t = (t + 1) / 2;
k = 2 * k;
}
}
cout << k << endl;
}
}
}

















 659
659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









