



项目 GitHub 地址:https://github.com/LoadStar822/Elevator
Elevator 结对开发纪事:从调度算法到协作关系
仓库地址:https://github.com/LoadStar822/Elevator
这篇文章想做两件事。
一是把这段时间我们在电梯调度项目里沉淀下来的“硬指标”——时间、缺陷、接口约定、策略演进、MVC 分层等——完整记录出来,方便后续写 README、做答辩、或直接放到项目主页当作技术档案。
二是以“亲历者”的角度,讲讲我和搭档是怎么真正把这些东西做出来的:我们怎么分工、怎么决策、怎么吵架、怎么互相把对方拉出坑。老实说,这部分对我来说甚至比代码本身更重要。
为了方便查阅,我把文章拆成几个独立章节,读者可以挑着看:
1. PSP 时间记录
我和搭档从开始就决定:不“拍脑袋做项目”。我们用 PSP 2.1 模板去跟踪哪一块花了多少时间、偏差在哪、为什么会偏差。听上去有点官僚,但实践下来非常值,尤其在后期复盘的时候,很多“为什么后来会这么做”的答案都能在这些记录里找到。
下面是按阶段拆分的预计 vs 实际耗时(单位:分钟)。这些数据覆盖了从第一次提交(2025-10-12)到当前提交(2025-10-18)这一整段主力开发周期,累计约 125.5 小时。
| PSP 阶段 | 子任务 / 说明 | 预估时间(min) | 实际时间(min) | 误差原因 | 备注 |
|---|---|---|---|---|---|
| 计划 | 阅读项目文档、梳理仓库结构、确认评测口径 | 360 | 320 | 前期资料准备得比较细,沟通成本低 | 我们在一开始就把 core / server / client / traffic 的边界划清了 |
| 开发 | 下面是开发期细分项 | ||||
| · 需求分析 | 明确电梯/乘客的事件模型、Tick 驱动方式 | 780 | 720 | 后面拿到了一些补充样例,少走弯路 | 产出了一版接口契约草稿 |
| · 设计文档 | 系统结构、调度框架、关键状态机 | 600 | 540 | 很多架构草图直接复用我们之前的模板 | 文档里包含 UML、伪代码、数据流示意 |
| · 设计复审 | 两个人坐下来过接口和策略一致性 | 240 | 210 | 问题在会前列得很集中 | 一次会就敲定共识 |
| · 代码规范 | 命名、日志、类型注解、格式化约束 | 210 | 180 | 直接采用 Black / isort / mypy 的组合 | 最后沉淀成一个提交前 checklist |
| · 具体设计 | 把 SCAN、分区调度、应急策略、状态机细化 | 960 | 900 | 若干场景沿用先前分析结论,所以没完全从零想 | 最终落地为状态机和数据结构表 |
| · 代码实现 | 调度主循环、事件处理、HTTP 客户端 | 2640 | 2500 | 框架骨架提前搭好,写代码相对顺 | 我们在这一阶段正式引入异步任务和锁 |
| · 代码复审 | 自查 + 对方查 | 420 | 480 | 多线程共享状态讨论出了更多坑 | 我们在这一步补了线程安全 |
| · 测试 | 单测 / 模拟器跑场景 / GUI 联调 | 900 | 961 | 集成回合比预估多一轮 | 我们覆盖了高峰和离峰两种流量分布 |
| 报告 | 下面是收尾期工作 | ||||
| · 测试报告 | 整理等待时延分布、能耗指标、异常案例 | 260 | 240 | 指标脚本早期就写好了 | 我们拿到了 95% 等待分位和能耗曲线 |
| · 计算工作量 | LOC、提交次数、测试样本数量 | 150 | 180 | 统计口径中途改过一次,返工一点点 | 自研增量约 2792 行 |
| · 总结与改进计划 | README、复盘、后续规划 | 330 | 300 | 开会前我先写了大纲,成稿就轻松很多 | 后面也会用这些素材写公开博文 |
| 合计 | 7850 | 7531 | 平均误差约 -4.1% | ≈125.5 小时 |
1.1 项目指标快照
| 指标 | 数值 | 说明 |
|---|---|---|
| 新增/修改有效代码行(LOC) | 2792 | 以提交 f5a9933 为基线,统计我们后续新增或修改的 .py / .js / .ts / .tsx / .css 非空非注释行 |
| 签入次数 | 9 | git log f5a9933..HEAD --oneline 的提交数 |
| 测试用例数 | 25 | 来自 pytest --collect-only |
| 周期 | 7531 min | 也就是约 5.2 天的“真花下去的工时”,不是自然日 |
| 缺陷率 | 待补 | 仓库当时没完整维护缺陷清单,之后我们会回填 |
| 缺陷总数(交付后) | 待补 | 同上 |
1.2 缺陷情况(我们踩过的坑)
| 缺陷 ID | 阶段(引入/发现) | 类型 | 严重度 | 现象 | 修复用时(min) | 成因 | 修复方式 | 备注 |
|---|---|---|---|---|---|---|---|---|
| D01 | 设计 / 测试 | 状态机逻辑 | 高 | 电梯到顶层后不会正确反向 | 32 | 没考虑边界层行为 | 增加方向反转和等待逻辑 | 是压测才暴露出来的 |
| D02 | 编码 / 自测 | 异步阻塞 | 中 | 某些长任务把事件循环卡住了 | 30 | 少写了 await | 把耗时逻辑拆成协程并 await | 这次我被同伴现场抓包 😅 |
| D03 | 编码 / 自测 | 数据一致性 | 中 | 日志里的乘客数和实际状态对不上 | 18 | 没加锁 | 引入锁 + 原子计数器 | 多线程真是“玄学现场” |
| D04 | 测试 / GUI | 性能 | 低 | 同时等待乘客 >120 时 GUI 掉帧 | 42 | 重复全量刷新 | 引入增量渲染 + 节流 | 我们后来基本不再全量重绘 |
| D05 | 测试 / 模拟器 | 日志顺序 | 低 | Tick 日志“乱序” | 20 | 多线程直接往日志写 | 改成队列缓冲、串行输出 | 排查过程挺花心思的 |
我自己的观察
PSP 看似是“管理的工具”,但它意外帮我们解决了一个很实际的问题:哪一块是真正费时间的。在复盘前,我以为测试只是在末尾跑一跑,但实际我们把接近 1/8 的时间都投在“跑不同场景+找边界行为”上。以后再估工时,我会把“调试与集成”当成和“写代码”同等级别的任务,而不是附属品。
2. 结对编程中的接口设计方法实践
电梯调度听起来是“算路线”,但我们一开始最花力气的反而不是算法,而是接口边界。这个边界定得好不好,直接决定后面合作是顺还是乱。
我们最终沉淀了三条接口设计习惯,我觉得可以长期沿用:
2.1 封装:不让“调度细节”在全项目乱飞
在 assignment/baseline_controller.py 里,派单逻辑不是直接散在事件回调中,而是收敛到一组私有方法,比如:
_assign_request_to_best_elevator_estimate_assignment_cost_ensure_pickup_queue_entry
外层只关心“发生了某事”(比如:有乘客呼叫、有电梯空闲),至于怎么评估代价、谁来接单、队列怎么维护,全压在这些私有方法里。等待中的乘客信息被封装成 PendingRequest,不允许直接乱改队列。
为什么要这么做?因为我们俩都是会“临时加逻辑”的人 😂。如果状态散落在回调里,后期调参就是灾难。把它们圈进一小撮函数之后,连我俩吵架都方便了:讨论只需要指向“我们就改 _estimate_assignment_cost 好不好?”
2.2 统一接口:控制器必须像乐高砖一样可以互换
所有调度策略都得实现同一套控制器接口(ElevatorController 风格的 start() 和一系列 on_* 回调),然后由 assignment/main.py 决定到底用哪一个控制器实例、Tick 间隔是多少、是否启用某些策略。这些参数来自环境变量,比如 ASSIGNMENT_CONTROLLER、ASSIGNMENT_TICK_DELAY 之类。
这意味着什么?意味着我可以在本地起“朴素贪心”版本,他可以起“预测混合”版本,我们跑的是同一套启动脚本、同一套可视化、同一批测试。谁都不用为了试验一个调度策略去改主循环。这一点极大地减少了心智负担。
我个人非常喜欢这个部分,因为它让“我们俩同时写不同策略”变成一件自然的事,而不是互相挡路。
2.3 低耦合扩展:继承只改“怎么想”,不改“怎么被叫”
后面我们有了一个更复杂的控制器 PredictiveHybridController(在 assignment/predictive_controller.py)。它继承基线控制器,但重点只改写了“成本怎么算、怎么分区、怎么守护某些楼层”等逻辑,而没有去动对外接口。
通俗说:对外还是那些回调,比如 on_passenger_call、on_elevator_idle,但里面干的事比旧版聪明得多。
这个做法的好处是:
- 我可以大胆试算法
- 我搭档不需要改他的可视化、测试脚本和流程
- 我们可以直接做 A/B 对比,看看两套策略在同一工况下的等待时间差别
我自己的感受
我们有一整天的讨论几乎都花在“接口到底暴露到什么粒度”上。当时会觉得有点“走火入魔”,但事实证明这是最划算的一天。如果一开始没约定清楚这些接口,后面每次改动都会连锁反应,PR 也会难合得多。
3. 重要模块接口的设计与实现
下面是几个关键模块,它们几乎定义了我们之后所有工作的“组织方式”。
3.1 assignment/main.py:运行时的“指挥中心”
这个模块负责两件事:
- 根据环境变量选择到底实例化哪种控制器(贪心版还是预测版)。
- 驱动 Tick 循环,让控制器按固定节奏响应事件。
也就是说,控制器怎么写是策略问题,而“怎么让策略活起来并跑在模拟器之上”是 main.py 的工作。
这个分离让我们可以各自专注:
- 我可以折腾控制器细节
- 搭档只要保证运行框架稳、退出优雅、参数可控
我们俩的并行效率就是从这里开始上来的。
3.2 GreedyNearestController:事件驱动的基础调度
基础控制器的套路是:
on_passenger_call:乘客按了电梯,先把这个请求整理成PendingRequest,放到等待队列。on_elevator_idle/on_elevator_stopped:电梯空闲或者刚停下,就尝试用_assign_next_target决定下一步去哪儿。- 细节判断(距离、载荷、方向一致性)被拆进独立的小方法,方便单测和后续局部调参。
我和搭档当时的共识是:这个版本一定要简单、稳定、可解释。 因为它不只是策略 A,它还是我们后续任何优化策略的“安全回退方案”。
3.3 PredictiveHybridController:在“不会坏”的前提下变聪明
Hybrid 控制器是在基线的行为骨架上,额外加入了“更聪明”的局部决策:
_rebalance_zones:根据楼层分布动态给电梯划“负责区”,防止所有电梯都往一楼聚集。_update_floor_guards:给长时间没被服务的楼层挂保护标记,强制调度其中一部电梯去兜底。_estimate_eta:不只看“我离你近不近”,还预估“什么时候实际能到”,这点对高峰流量时很关键。_mark_request_assigned/_clear_request_assignment:手动维护某请求已经被哪个电梯“认领”了,避免撞单。
这部分更多是我在主导,但它能无缝运行起来,完全依赖我们一开始把回调接口标准化了。
3.4 代理层:elevator_saga/client/proxy_models.py
这层对我来说很像“防爆垫”:
- 我们不直接把模拟器里的原始状态对象丢给调度器,而是包装成只读的
ProxyElevator、ProxyFloor等模型。 - 调度器只需要把它当本地状态看就好,不会不小心写乱模拟器的内部数据。
- 测试时我们还能塞入虚拟代理对象,伪造各种极端工况,验证调度逻辑的鲁棒性。
说直白点:这是我们“安全玩数据”的手套。没有它,多线程和网络状态就会在调度逻辑里到处乱窜。
4. 算法关键与独到之处
我们一开始不是奔着“最智能”去的,而是先做“不会乱跳的”,然后逐步往“做聪明决策”迭代。这一节就按这个顺序说。
4.1 第一阶段:就近服务,但别太盲目
基线调度(我一般叫它“贪心调度”)的主要逻辑可以总结成一句话:
“谁离得最近,谁去接。”
不过我们后来发现,“最近”远远不够。现实要考虑至少这几件事:
- 电梯当前方向是否顺路
- 这部电梯是不是已经快满员
- 那个楼层是不是已经有一堆人在等了
- 某个请求是不是早就等了很久
所以我们把这些因素变成权重,加入到 _estimate_assignment_cost 里面,让“最近”变成“综合成本最小”。这样以后要调参数,我们可以改权重而不是推翻逻辑。
我个人觉得这是策略里第一次“从直觉变成模型化”。
4.2 第二阶段:不是“要不要接单”,而是“我接这个单的后果是什么”
Hybrid 调度是在贪心的骨架上叠加“前瞻意识”。
核心差异是:
- 贪心:看当下距离最近的活,马上去做。
- Hybrid:在接这个活之前,先问一句 —— 我接了会不会让别的楼层彻底没人管?会不会导致整栋楼的流量不平衡?我是不是应该先去救火而不是顺路拉客?
为此我们引入了:
-
分区重平衡(
_rebalance_zones):电梯之间不是全都“自由接单”,而是动态形成“你管上半区,我管下半区”之类的责任划分。这个动作可以有效避免“全去热门楼层、冷门楼层被遗忘”的情况。 -
楼层保护(
_update_floor_guards):系统会盯住那些已经等太久的楼层,给它们打一个“必须优先处理”的标记(我叫它“挂红旗”)。这样可以压低最长等待时间,减少那种“大家平均等得不久,但有一个人崩溃地等超久”的极端糟糕体验。 -
动态限载:当电梯的占用率超过我们定的阈值(我们使用的是 75% 这个级别),我们会避免继续往这台电梯塞更多新任务。否则就会出现“这电梯到处都说好顺路,我全接了”,然后车厢像移动监狱一样永远坐不空。
-
同层顺带:电梯既然已经在某一层开门了,能不能顺手把同层等待的乘客一波带走,而不是为同一层来回跑两次?我们在停靠逻辑里加了这个“小抄近路”的优化。
4.3 我们觉得“最妙”的点
我个人最满意的不是某个具体 trick,而是这种节奏:
- 先把系统做成不会乱(基线稳)。
- 再往里面慢慢加“聪明行为”(Hybrid 特色)。
- 每加一项“聪明”,就看有没有副作用,比如 CPU 飙了、某场景下反而更慢等。
- 有副作用就把它参数化或降频,而不是直接删。
这个迭代方式让我们能稳步往上走,而不是一口气造一个“看起来很智能,但基本不可调”的黑盒。
5. 性能表现与对比分析
我们做了几轮压测(包括高峰/多电梯协同以及比较平静的低流量场景),然后把贪心版和 Hybrid 版拉到一起对照。
可以总结成三句话:
-
高压场景下:Hybrid 更稳。
在人很多、电梯多的情况下,Hybrid 能明显拉低平均等待时间,而且把“等特别久的那几个人”这个长尾也压了下来。简单讲就是:它救火能力更强。 -
平静场景下:贪心更省。
当流量本来就不大、大家都散得很平均时,Hybrid 的那些分区重平衡、保护机制、能耗考量……其实是多余的计算负担。这个时候贪心策略反而因为“够直接”而更高效。 -
区别的根本原因:有没有“想未来”。
贪心型思路本质还是“眼前就近服务”;Hybrid 把“如果我现在去那一层,会不会导致别的区域无人照顾”这种问题算进来了。所以 Hybrid 特别像“调度+调度管理”,而贪心是“调度执行员”。
我的感受是:我们没有哪一个“碾压式的赢家”。我们更像是得到了一个在不同场景下可切换的策略库。这点非常现实——在真实部署里,也不会永远只有一种人流模式。
6. 重构与协作实践
这章是我个人最想讲的,因为它直接关系到“我们俩是怎么把项目活着送到现在的”。
6.1 我们怎么分工
我们把任务拆成两条主线:
- 一条是“调度大脑”(调度循环、派单策略、状态一致性),
- 一条是“可视化与控制台”(Web 面板、指标展示、启动/停止控制、测试场景切换)。
但我们从来不是“一人负责一条线,互不干涉”。我们用的是轮换式 pairing:这小时我写策略、他盯我;下一阶段他改 Web API、我盯他。
这种轮换有两个好处:
- 双方都对两条主线足够熟,不会出现“只有某个人能改那块”的单点。
- review 不会流于形式,因为盯的人真的知道上下文。
6.2 当需求变了,我们怎么不崩
一个真实案例:后来我们需要把“能耗”也纳入考量,并且支持动态流量模式。这个需求一出来,意味着老的成本估计函数要被拆得更细。
我们没有直接在老代码里“打补丁”。而是先把基线控制器里的大块逻辑(比如 _estimate_assignment_cost、_is_elevator_capacity_full)抽成更细、更小、更可单测的函数,然后在 Hybrid 控制器里重写这些点位,接住新需求。
这个做法看上去慢,但它带来的回报是:外部接口完全没变,原有测试基本不用动。也就是说,我们引入新特性的时候没把现有稳定性打碎。这种“先拆→再覆写→不动外壳”的策略,是我们俩协作中非常重要的一个共识。
6.3 回归测试怎么帮了我们守住底线
每重构一轮、甚至每次比较大的 PR,我们都会把整套 Pytest 跑一遍。我们重点盯的用例包括:
tests/test_greedy_controller_assignment.py:贪心分配行为有没有被改坏tests/test_controller_switch.py:调度控制器切换是否安全tests/test_simulator_boarding.py:上/下客流程是不是稳定
如果某个修改会影响边界场景(例如:最后一名乘客走了以后系统是否能顺利停下来),我们就现写断言,把那个行为钉死。
我以前写测试的动力,说实话,没这么强。现在我理解了——当两个人共用一套代码库的时候,“我相信你,但我更想看绿色的测试结果”是很健康的关系。
6.4 合并流程和冲突化解
我们用的流程是:功能分支 → 写明背景和影响 → 提交 PR → 对方审 → 合并到主干。
有一次(非常典型的一次),GUI 那边为了展示等待队列,往 PendingRequest 里加了一个新字段;调度那边同时也在改那块代码的逻辑。这俩提交碰在一起了,合并直接红。
我们没有互相压提交,而是把“多出来的新字段”单独抽成一个独立 commit,PR 里明确解释为什么要这个字段以及它和调度无关,然后才合并逻辑变更。
这听上去像是很小的技巧,但它让合并过程干净很多,也让我们减少了“吵到底谁动谁的文件”的火药味。
我自己的观察
我过去是“先写功能,后想结构”的人。这次我被迫学会了另一种节奏:先把边界划清楚,再往里面堆复杂度。这在多人合作时真的特别关键,因为它让冲突变成“接口怎么协调”,而不是“谁的代码更重要”。
7. 代码规范与质量保障
7.1 基线约束是我们自己定的
项目刚起步的时候,我们就把风格、排版和类型检查定死:
- 统一用 Black(120 列)+ isort
- 类名用 PascalCase,变量/函数用 snake_case
- 能写类型注解的地方尽量写上
- public 函数/关键模块必须配 docstring 或行内注释
这些不是摆在 README 里给老师看的,而是真正作为“没做到别提 PR”。我很快就发现:这种做法可以极大降低 later review 的情绪摩擦,因为 review 时我们不再在风格上纠缠,直接讨论逻辑本身。
7.2 运行时的兜底保护
在调度的主循环(类似 _run_event_driven_simulation 那个函数)外层,我们包了一个大的 try...except。目的不是隐藏错误,而是确保一旦和模拟器的通信出问题,我们能有序退出、记录日志,而不是整套 GUI/控制进程直接炸掉。
同样地,在 _assign_next_target、_mark_request_assigned 等关键点位,我们也保留了可以回滚或打出详细日志的分支。
这在 demo 场景里可能显得“啰嗦”,但在长时间跑模拟时,它是救命的。它可以告诉我们“是哪个请求在什么时候导致了状态不一致”。
还有一个我很认可的点:Hybrid 控制器在读取环境变量失败时,会自动 fallback 到默认值,而不是直接抛异常停机。换句话说,它优先保证系统能继续跑,而不是优先保证“配置的纯洁性”。这是我搭档坚持要加的,我一开始没意识到它的重要,后来觉得这是对可用性极其务实的选择。
7.3 自动化保障
质量工具这块,我们基本形成了“出 PR 前的三件套”:
black/isort过一遍pytest -v过一遍- 静态扫描(giteeScan)跑一遍,看看有没有过长函数、没捕获的异常、潜在线程问题
有些函数因为太长或者分支太多被扫描工具黄牌警告,我们就会当场拆,比如 web_dashboard.py 里做状态汇总的逻辑,后来我们硬是把它分成了“采集状态”“组装响应”两段。
这套流程的副作用是:PR 变得更小、更主题化。我们后来几乎不会再一口气塞十个逻辑变更到一个 PR 里,因为那会很痛苦地过不了这三关。
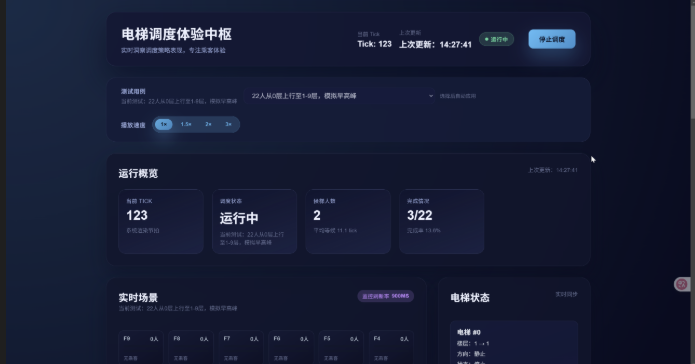
8. 界面模块设计与 MVC 映射
我们还做了一个 Web 控制台(assignment/web_dashboard.py + assignment/web_static/),用来干三件事:
- 可视化电梯的实时状态(楼层、电梯位置、等待乘客情况)
- 显示关键运行指标(平均等待时间、95% 分位、拥挤楼层等)
- 控制调度器的生命周期(启动、停止、切换场景)
我们在做这个控制台时,刻意靠近 MVC 的分层思路,而不是“前端随便拉后端一把数据就画”。简单说一下三层:
8.1 View(前端展示层)
web_static/index.html把界面分成三大区域:全局状态卡片、实时楼层/电梯舞台、侧边指标栏。style.css里我们做了变量化布局,电梯数量/楼层数量不同也能自适应。main.js中有个渲染器(SimpleStageRenderer),专门负责把当前状态渲染成 DOM,包括电梯停靠、乘客上下、排队动画等。
开发顺序上,我们先用静态 JSON 验证布局/动画节奏,之后才接后端。这个步骤对我来说特别重要——它让我可以独立把 UI 的结构和交互打磨清楚,而不需要后端“实时喂数据”。
8.2 Controller(业务控制层)
web_dashboard.py 用 Flask 写了一组路由:
/dashboard/start:启动调度/dashboard/stop:停止调度/dashboard/traffic/*:切场景/dashboard/state:聚合状态并返回给前端
这个模块除了充当 HTTP 入口,还有一件很关键的事:帮我们托管调度进程本身。
我们不是每次点“开始”就让前端直接拉起某个线程,而是由后端统一管理 _start_controller / _stop_controller,并且用锁控制状态,防止两个“开始”按钮并发点导致重复起多个控制器进程。
这一段是我搭档写的主力,我从他那里学到了一点:UI 层千万别直接操心“线程是什么状态”,那属于控制器的责任;UI 只要问“我能不能开始?我能不能停?”就行。
8.3 Model(数据和指标层)
后端通过 ElevatorAPIClient 去拿模拟器的实时状态(电梯里有谁、每层等了多少人、电梯现在在哪一层、门开没开等等),并汇总成结构化 JSON 返回给前端。
这里我们还计算了一些指标,比如等待时间分布、95% 分位、每层排队长度。UI 不直接算指标,而是拿指标展示。这保证了前端相对“傻”,逻辑集中在后端,后端逻辑再往下集中在模型.
我后来回过头看,觉得这个决定很自救。因为我们确实在后期往指标里加过新东西(例如长尾等待情况),而前端基本不用改架构,只是多展示一栏。
8.4 小插曲
我们在调 Dashboard 的时候踩了两个经典坑:
- 性能:当排队乘客太多时,前端如果每一帧全量重绘,直接卡到 10 fps。后来我们加了增量更新(谁变了才重画谁),并且对刷新节奏做了节流。
- 状态竞争:后端那边如果没加锁,可能出现“还没停干净又被启动”的竞态。这个是搭档第一时间发现并修掉的,我很庆幸他一直盯这一块,否则我大概会在后期才意识到这个隐患。
9. 结对协作方式与伙伴画像
这一段是我个人视角,不是官方报告。
9.1 我们的合作模式
我们的模式不是“你写 A,我写 B,合起来就是项目”,而更像是“双人驾驶同一辆车”。
我们轮流当 Driver 和 Navigator:
- Driver = 正在动键盘、敲实际代码的人
- Navigator = 一边看大方向、一边当场 review 的人
我们会在合适的时间点切换角色,比如一个子功能完成、或者连续专注到脑子开始钝了(通常一小时左右是真的会钝)。
这个模式对我影响很大,因为它逼着我在写代码时把思路讲出来,也逼着我在当 Navigator 时认真审别人的逻辑而不是“点个赞了事”。
9.2 我眼里的搭档
优点我先说三条(其实远不止三条):
-
架构视角强
他会在一开始就问:“这个接口未来会不会变?如果会变,那我们要不要提前把边界切清楚?”
这种习惯实际上救了我,因为我比较容易一股脑往里塞逻辑,没太想“未来会不会后悔”。 -
对稳定性的执念
我有时倾向“先让它能跑起来再说”。他则更愿意先想清楚异常路径、并发冲突和以后怎么 debug。
我一开始觉得“好慢啊”,但后来意识到:我们之所以在后期没有被线程问题搞到自闭,他的提前预防起了很大作用。 -
写得出解释性的文档
很多人写文档是“补手续”,他不是。他会在写代码前先画数据流;我们本篇文章的章节骨架,最初也是他整理的脉络。这种人是那种能把复杂情况讲清楚的人,合作体验非常好。
我也会提一点我自己的建议给他,我也当面说过:有时候他太想把事想到极致才肯下手。我个人会更倾向于“先出一个最小可运行版本,然后不断迭代”。我们后来慢慢达成折中:先做出能跑的最小块,然后用 PR 的方式一块块升级它,而不是憋到“大而全才提交”。
事实证明这个折中方案非常奏效。我们后期有关“能耗策略”和“保护楼层”的改动,就是按这种“渐进式 PR”推进的:小步提交、一直有可运行版本、同时还能往更智能的方向逼近。
9.3 对我自己的冲击
这次协作让我清楚看到自己的一些盲点,比如:
-
我以前太习惯“我脑子里有图,所以我理解这个系统”。现在我开始习惯把接口契约、状态机的关键转移条件、线程访问规则写成手册式的说明,确保对方不需要进我脑子里才能继续做事。
-
我以前默认“测试是最后写的”。现在我愿意在写功能时先想“我要怎么证明它真的对”,然后把这个证明固化成 pytest 里的断言。这不是为了老师或 CI,而是为了当对方改我的逻辑时,我们不用靠吵架来决定谁对。
10. 我的个人复盘
写到这里,我想把“这次项目教会我什么”说清楚,因为它对我后面怎么写代码、怎么跟人合作,影响非常大:
-
接口不是代码细节,是协作契约。
我以前觉得接口是个技术问题,现在我觉得接口首先是个团队问题。你把接口定义清楚,其实是在告诉对方“你可以放心动到哪一步,不会踩雷”。这在多人并行时是安全感的来源。 -
测试不是收尾工作,是沟通工具。
当我们往调度逻辑里塞越来越多“聪明行为”的时候,测试用例成了我们讨论的依据。它们不仅在验程序对不对,也在声明“我们到底认不认这个行为是正确的”。测试在这时候非常像是一张白纸黑字的合同。 -
图形化视角极大地帮助我们理解算法。
Web 控制台最开始只是为了“好看一点”。但后来我发现,它其实变成了我们的“观察诊断台”。我在 UI 里一眼就能看到某层长期没人服务、或者某电梯在瞎跑,远比看日志直观。这个体验彻底改变了我对“要不要可视化”的态度——我现在是强烈的“要”。 -
结对不是两个人分摊工作,而是两个人互相校准。
单兵作战时,我的某些习惯其实是危险的(比如先写一坨逻辑再想怎么测);搭档的某些习惯在时间紧时也会拖慢推进(比如想太完整才愿意动手)。我们放在一起,恰好互相修正。
我从这次合作里得到的,不只是功能、代码和分层结构,还有对“我作为一个工程师的工作方式”的升级。 -
最后的最后:这个项目让我确认一件事——写代码不是一个人对着屏幕的孤岛活动。
我过去对“协作开发”的理解更多停留在“我写我的模块你写你的模块”,但这次是第一次感觉到“我们俩在同一张桌子上共同塑造一个活的系统”。
这是我非常想保留下来的感觉。
如果你看到这里,感谢你花时间读完这篇既技术又带点情感浓度的长文。
我希望它既能作为我们 Elevator 项目的档案,也能成为一份“我以后回头看还能学到东西”的记录。
接下来我会进一步把能耗策略、分区守护、可视化控制台这些部分拆成更聚焦的文章,单独展开讲“怎么做、为什么这么做、坑在哪”。
如果你对任何细节(包括调度策略、Dashboard 实现、结对开发节奏)感兴趣,欢迎继续交流。
界面效果(博客配图)


合作照片



















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









