



A. Good Pairs
题意:
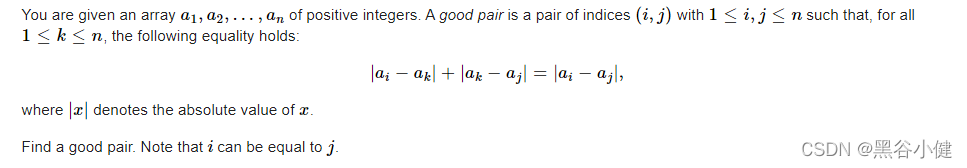
思路:
观察上面的数学等式,有没有发现只要绝对值开出来不变号,那么一定成立?所以取个最大和最小即可
#include<bits/stdc++.h>
using namespace std;
const int maxn=2e5+100;
struct node{
int v,idx;
}a[maxn];
bool cmp1(node a,node b)
{
return a.v<b.v;
}
int main()
{
int n,i,j,t;
cin>>t;
while(t--)
{
cin>>n;
for(i=0;i<n;i++)
{
cin>>a[i].v;
a[i].idx=i+1;
}
sort(a,a+n,cmp1);
cout<<a[0].idx<<" "<<a[n-1].idx<<endl;
}
return 0;
}
B. Subtract Operation
题意:
您将得到一个n整数列表。您可以执行以下操作:从列表中选择一个元素x,从列表中擦除x,并从其余所有元素中减去x的值。因此,在一个操作中,列表的长度精确地减少了1
思路:
拿三个数玩一下就知道了,比如 1 2 3 ,假设把1拿走,剩下就是1 2 ,再拿走一个就是1,有没有发现,一直拿下去,到最后剩下的两个数时,他们的差和变化之前是一样的,也就是说本来最后两个假设是2和3,他们的差就是1,最后虽然是1和2,但是他们的差还是1,所以既然每个数的差是固定的,那么其实我就找数组中有没有任意两个数的差为k就好
#include<bits/stdc++.h>
using namespace std;
map<long long ,long long >mo;
#define int long long
const int maxn=2e5+1000;
int a[maxn];
signed main()
{
int n,i,j,t,k;
cin>>t;
while(t--)
{
cin>>n>>k;
for(i=0;i<n;i++)
{
cin>>a[i];
mo[a[i]+k]++;
}
int flag=0;
for(i=0;i<n;i++)
{
if(mo[a[i]]){
flag=1;
break;
}
}
if(flag) cout<<"YES"<<endl;
else cout<<"No"<<endl;
mo.clear();
}
return 0;
}
C. Make Equal With Mod
题意:
您将得到一个nn个非负整数的数组a1,a2,…。,a2,…...您可以进行以下操作:选择一个整数x≥2x≥2,并将数组的每个数除以xx,即对于所有1≤i≤N Set ai到ai%x时,将该数组的每个数替换为余数。
思路:
整体操作和上面一样,不过是用x%上每个数然后用他们的余数去代替,并且选的x可以任意,但是得大于等于2,首先不难发现,既然x随意选,那么只要大于2的都用它本身去取余直接就为0了,于是乎你从大到小一个数一个数余小去都可以得到0,那么没有出现1的情况都有解,现在思考有1的情况。
①有1的情况下如果有0那么一定是NO,因为无法进行取余操作,他们不会改变了
②有1的情况下1肯定是固定的,想办法把他们都变为1,那么余本身是0,余本身-1就是1了,所以就排序找一下数组里有没有出现过比他小1的即可。
我考场代码比较乱,最后几分钟过的。。哎,之前一直猜结论就芭比Q了,也是灵光一闪过的
#include<bits/stdc++.h>
using namespace std;
const int maxn=2e5+1000;
int a[maxn],c1[maxn];
signed main()
{
int n,i,j,t,k;
cin>>t;
while(t--)
{
cin>>n;
int f1=0,f2=0,d1=0,d2=0,cnt=0,b1=0;
for(i=0;i<n;i++)
{
cin>>a[i];
if(a[i]==1) d1=1;
else if(a[i]==0){
d2=1;
}
else
c1[cnt++]=a[i];
if(a[i]==2) b1=1;
if(a[i]%2==0) f2++;
else f1++;
}
if(d1==0||f1==n||f2==n)
{
cout<<"YEs"<<endl;
}
else if(d1&&d2)
{
cout<<"No"<<endl;
}
else
{
int dx=0,flag=0;
sort(c1,c1+cnt);
for(i=1;i<cnt;i++)
{
if(c1[i]-c1[i-1]==1) flag=1;
}
if(flag==0&&b1==0)
{
cout<<"YES"<<endl;
}else
{
cout<<"No"<<endl;
}
}
}
return 0;
}

















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









