




 本教程详细介绍了如何使用Requests和Scrapy框架模拟登录新浪微博。首先通过预登陆获取必要的参数,然后进行正式登录,处理可能出现的验证码或二维码登录流程,最后成功登录并保存Cookie。整个过程涉及Ajax请求、RSA加密、短信验证码和二维码登录。
本教程详细介绍了如何使用Requests和Scrapy框架模拟登录新浪微博。首先通过预登陆获取必要的参数,然后进行正式登录,处理可能出现的验证码或二维码登录流程,最后成功登录并保存Cookie。整个过程涉及Ajax请求、RSA加密、短信验证码和二维码登录。
爬虫基于Requests + Scrapy
Requests获取Cookie,Scrapy框架通过Cookie登录爬取。
本次模拟登录使用request的会话机制维持登录状态
模拟登录流程分析:
- 手动登录,使用浏览器develop功能分析登录流程
- 根据上一步的分析结构,手动构建请求参数
- 处理验证等过程,完成登录
- 登录成功保存Cookie到文件
一. 预登陆
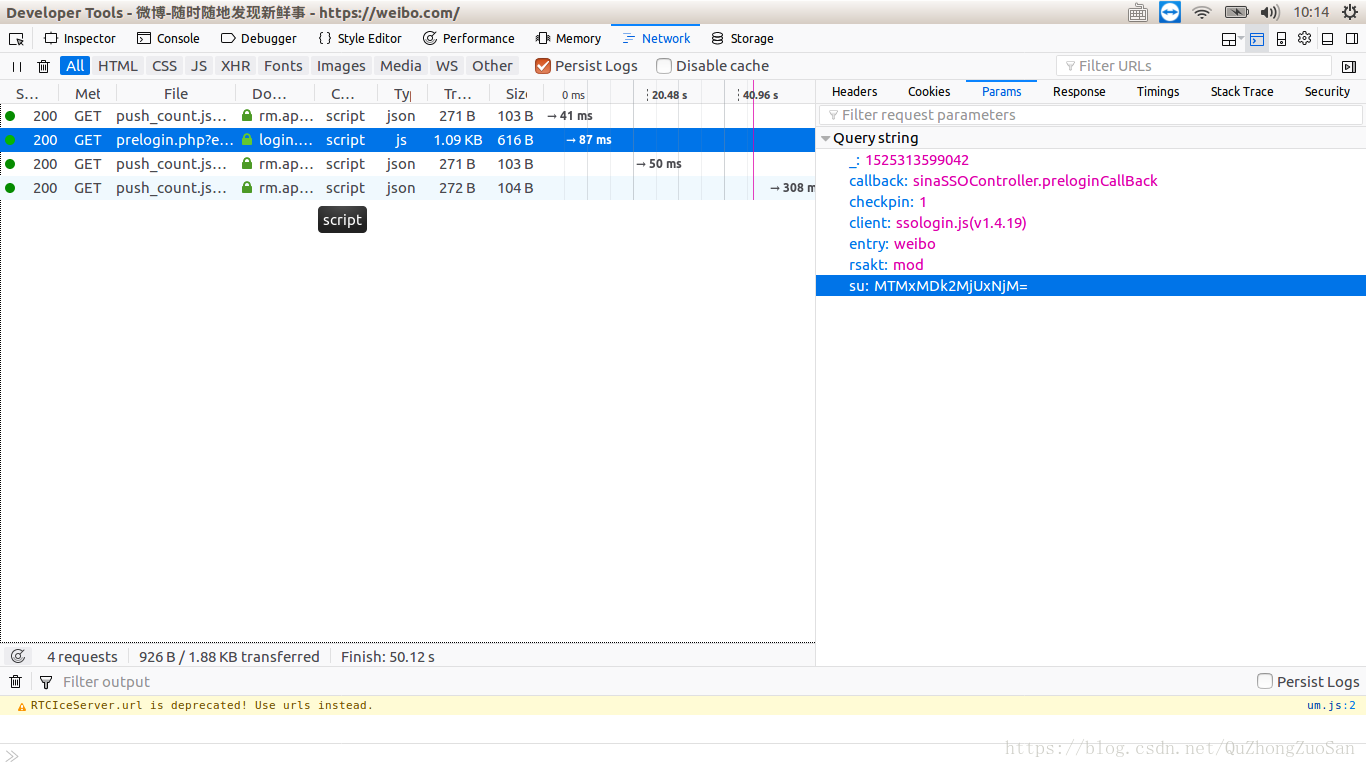
当键入账号后,新浪会发送ajax请求,请求参数包括Unix Timestamp ,账号使用base64计算后的su和固定参数,其中的client参数根据网上博客比较后发现是不同版本的登录JavaScript,是动态更新的。
请求发送后,返回值是包含一个json对象,包括服务器要求的一些参数。将里面的[servertime,nonce,pubkey,rsakv,pcid]提取出来,用于下一步正式登录。
二.正式登录
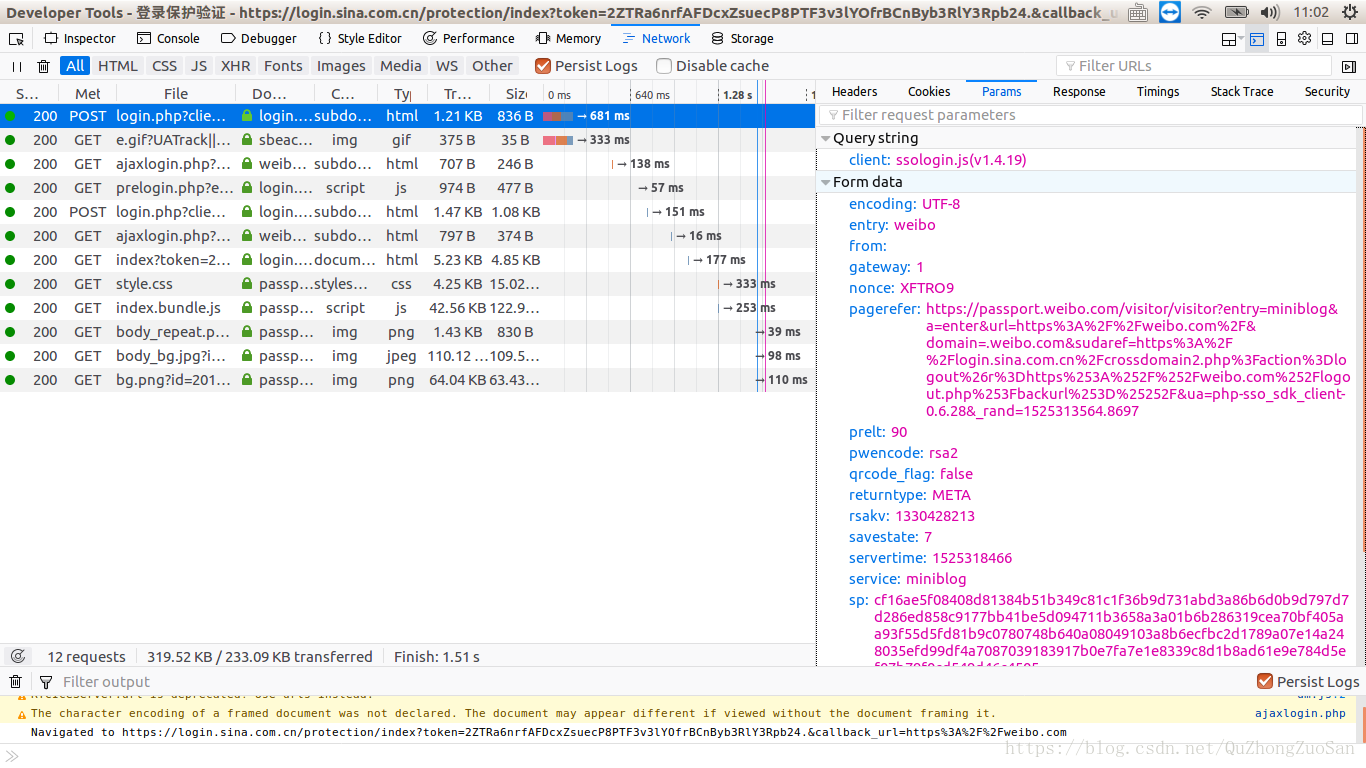
点检登录后,发送ajax POST请求,请求参数包含固定参数,和密码rsa加盐后的sp值,和上面获取到的参数共同构建成FormData。
postdata = {
‘entry’: ‘weibo’,
‘gateway’: ‘1’,
‘form’: ”,
‘savestate’: ‘7’,
‘qrcode_flag’: ‘false’,
‘use
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1068
1068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









