




 本文档是启英泰伦离线语音识别模块的使用教程,包括入门和进阶两部分。入门篇涉及语音识别基础、开发板获取及初步交互体验。进阶篇讲解开发环境搭建、固件在线开发和组件制作,如语言模型、声学模型的获取,以及播报音合成。此外,还介绍了用户代码的开发流程和固件烧录步骤。
本文档是启英泰伦离线语音识别模块的使用教程,包括入门和进阶两部分。入门篇涉及语音识别基础、开发板获取及初步交互体验。进阶篇讲解开发环境搭建、固件在线开发和组件制作,如语言模型、声学模型的获取,以及播报音合成。此外,还介绍了用户代码的开发流程和固件烧录步骤。
欢迎加我Q一起讨论:3806899279
入门篇¶
1、初识语音¶
语音识别的本质就是将语音序列转换为文本序列,其常用的系统框架如下:
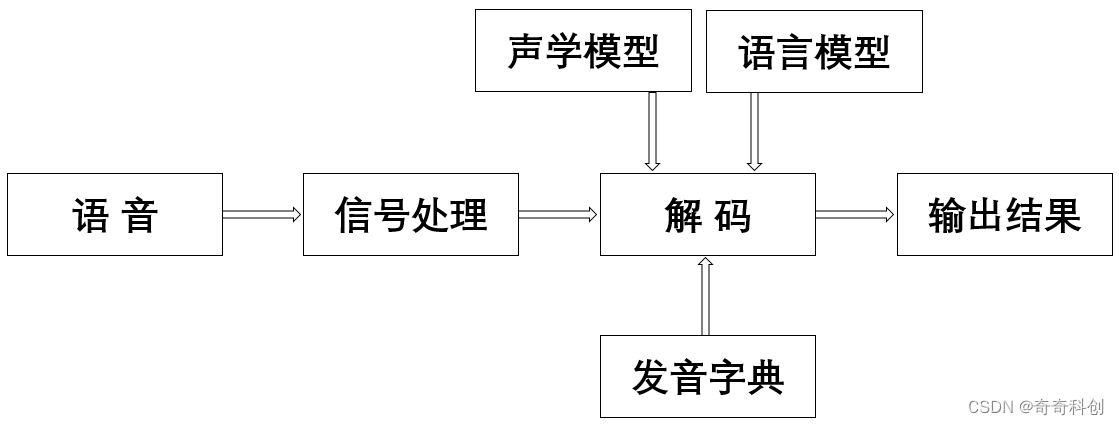
得更多的资料以及进行产品的开发,目前启英泰伦平台对用户免费开放,您可以获推荐您申请注册平台账号并使用。
2、获取开发板套件¶
对于电子创客来说,直接使用开发模组直接体验。提供了配套的使用说明,软件SDK,固件及各类工具
3、初体验识别交互¶
准备好您的开发板,接上电源,听见欢迎播报的时候,您就可以开始您的语音交互之旅了。
如果您体验完后,意犹未尽想制作一个自己的demo固件,那么请查阅下述进阶篇的内容。
进阶篇¶
1、开发环境准备¶
开发套件一个
1.1 搭建可编程开发环境¶
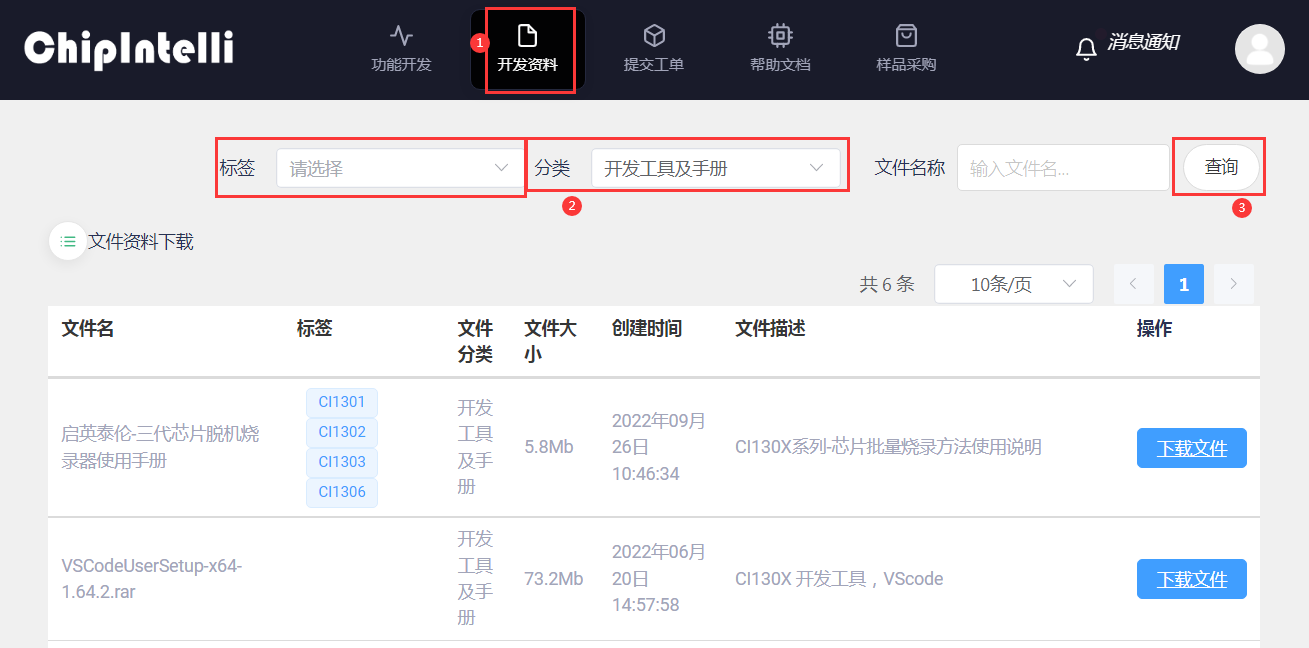
进入语音AI平台后,点击【☞开发资料】,分类选择“开发工具及手册”;“查询”后根据文件描述,下载对应芯片型号的开发工具及手册(可以通过选择标签来进一步筛选),解压并根据【☞编译软件安装与使用】指引安装可编程开发环境。
也可以关注微信公众号获取资料
回复 7166

1.2 开发板套件确认¶
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









