



克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
智能体自进化,阿里开源了新成果。
通义实验室提出了一种能够自进化的智能体系统——AgentEvolver。
通过自我提问、自我导航、自我归因三个模块,AgentEvolver可以在开放环境中自主演化出行为能力。
在相同规模的14B模型上,AgentEvolver将基准模型的平均完成率从29.8%大幅提高到57.6%。
目前该系统已在GitHub上线,技术报告也同步发布,作者署名当中包括了阿里副总裁、阿里云智能CTO周靖人。

模型智能体效果飞升
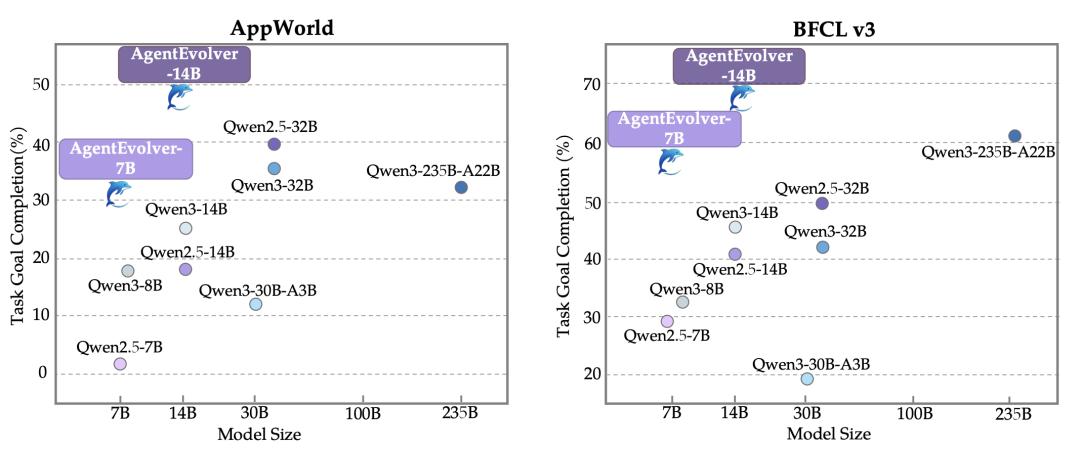
从综合性能来看,AgentEvolver在AppWorld和BFCL v3等长程复杂任务基准测试中展现了惊人的爆发力。
以14B模型为基座,其任务平均完成率(avg@8)从29.8%飙升至57.6%,实现了近乎翻倍的性能增长;在最佳尝试(best@8)指标上,更是达到了76.7%的高位。
在更小参数量的7B模型上的提升也同样显著,平均完成率从15.8%跃升至45.2%,证明了该框架对不同规模模型的普适性增强能力。
这种进化不仅体现在分数的增长,更带来了“越级挑战”的效果,经过强化后的14B模型,在特定任务上的表现已经超越了未经过同类优化的32B乃至更大参数量的模型(如Qwen2.5-32B)。
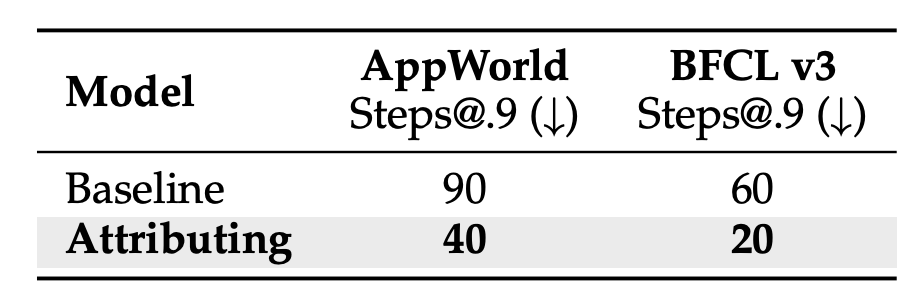
除了最终效果的上限被拔高,AgentEvolver在学习效率上也表现出了极速收敛的特性。
实验表明,在达到基线模型90%性能水平时,AgentEvolver所需的训练步数大幅减少,在AppWorld任务中减少了55.6%,在BFCL任务中更是减少了66.7%。
这意味着它不仅学得更好,而且学得更快,极大地降低了训练的时间成本和算力消耗。
并且这种自进化获得的能力具备极强的跨域泛化性。
研究人员发现,仅使用合成数据训练出的模型,在迁移到未曾见过的全新领域时,依然保持了极高的性能。
例如,在AppWorld上训练的模型直接用于解决BFCL任务时,性能衰减微乎其微。
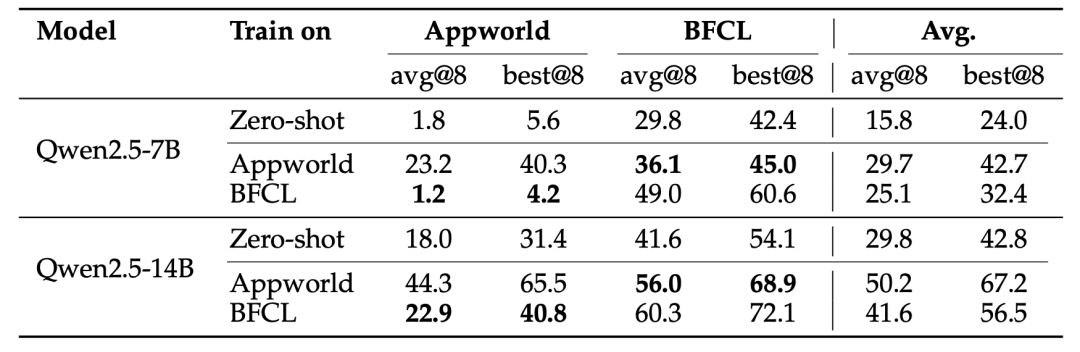
这说明AgentEvolver并非是在记忆特定环境的题库,而是真正掌握了通用的工具使用与推理逻辑能力。
AgentEvolver如何实现自进化?
AgentEvolver的本质是利用LLM自身的理解力,构建了一个数据-探索-反馈的自动化流程。
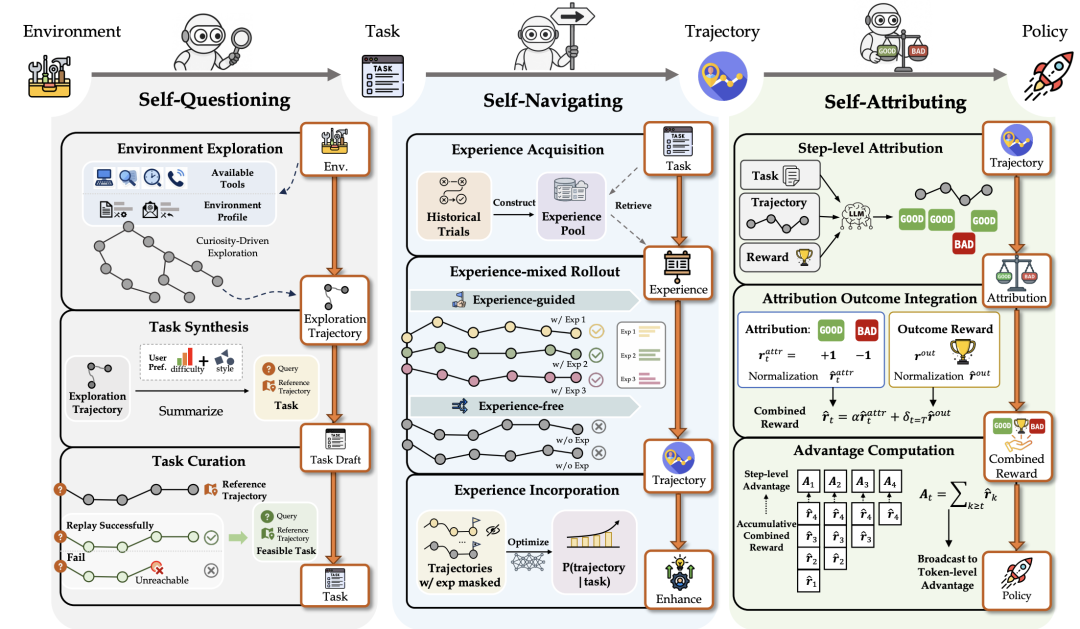
从整体架构来看,系统由Master节点统一调度,驱动着由任务生成、轨迹采样、经验总结和模型优化这四个阶段构成的自动化闭环,实现了无需人工干预的持续迭代。
为了支持大规模训练,框架采用了服务化解耦设计,将环境服务、模型服务和封装了Agent逻辑的执行层拆分为独立服务。
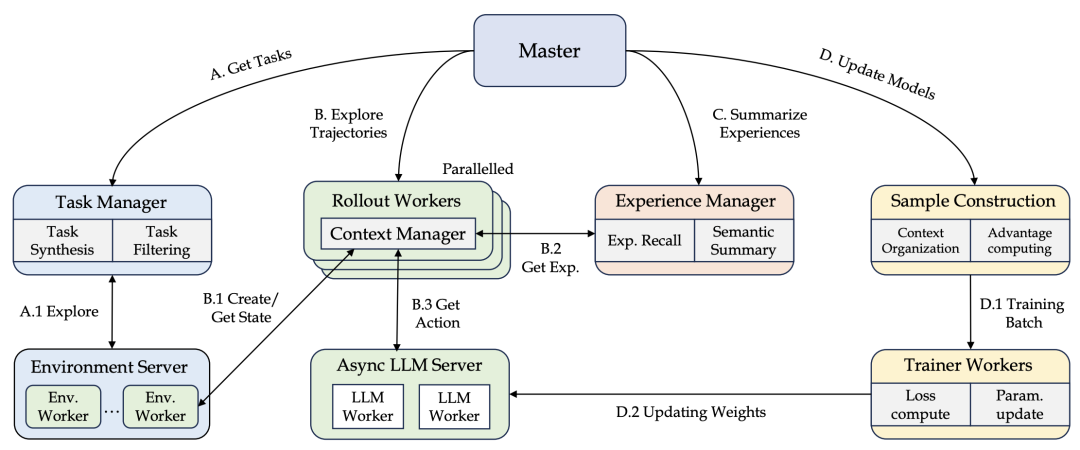
针对长程任务中Token消耗大、记忆管理难的痛点,系统还引入了上下文管理器,在保证推理连贯性的同时,有效控制了显存开销,并支持从滑动窗口到自主记忆管理的多种策略。
系统内置了基础因果、推理增强、滑动窗口以及自主上下文管理四种典型范式,涵盖了从追求极致效率到赋予Agent主动删减记忆权利的不同需求。
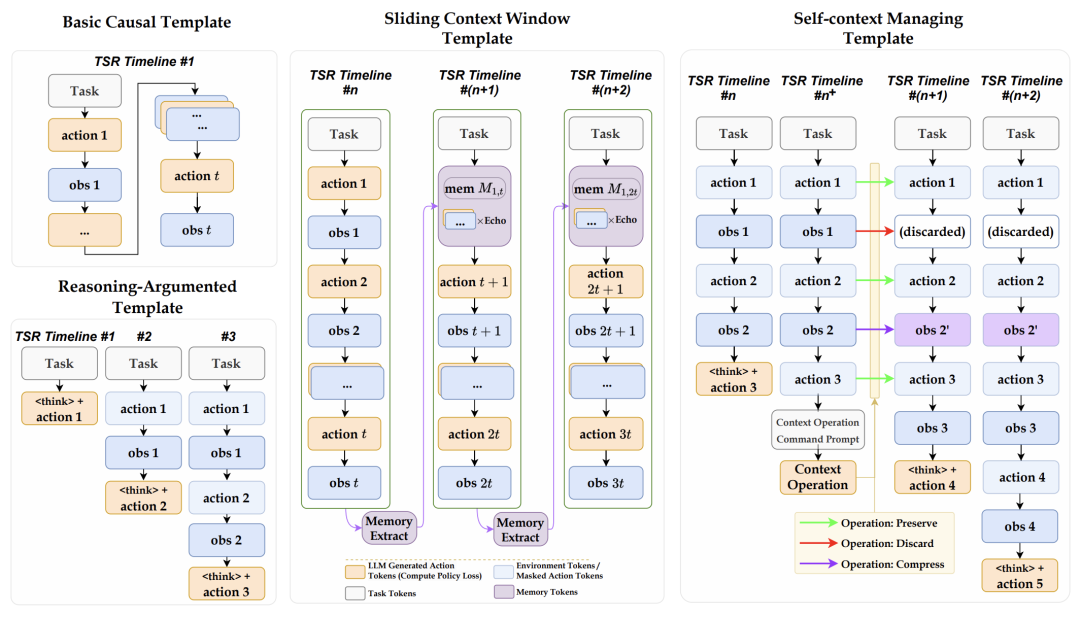
在此架构支撑下,AgentEvolver通过三个核心机制——自我提问、自我导航与自我归因——实现了能力的自主演化。
自进化的逻辑起点始于对环境的主动认知与任务构建。
面对新环境无任务可做的冷启动困境,系统通过自我提问(Self-Questioning)机制,利用LLM的生成能力结合环境探索中感知的特征(如API功能或界面布局),主动合成具有挑战性且符合逻辑的候选任务来构建训练课程。
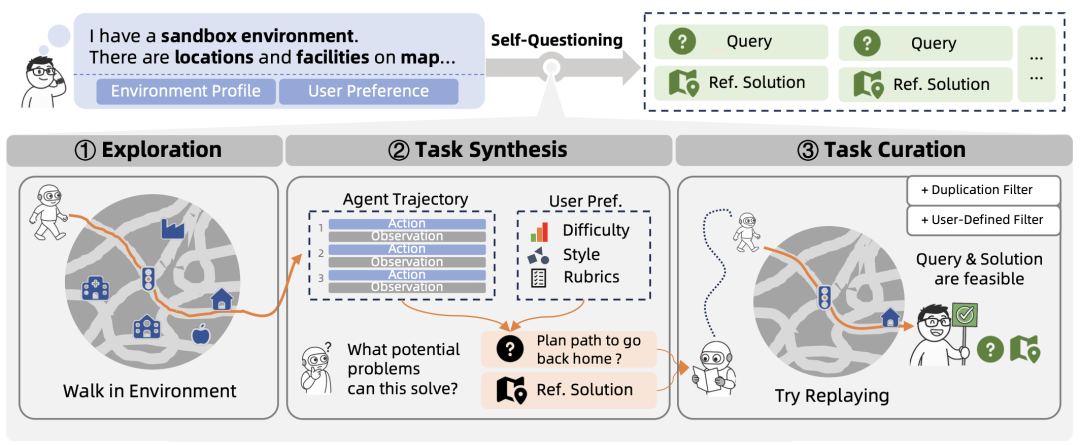
这使得系统能够自动生产出覆盖不同难度和多样性的训练集,有效打破了对外部数据的依赖,解决了强化学习中常见环境适应性差的问题。
当训练课程确立后,如何避免在复杂环境中的盲目试错,决定了进化的速度。
对此,系统引入了自我导航(Self-Navigating)机制来破解低效探索的难题。
该机制将历史探索中的成功轨迹和失败教训抽象为结构化的文本经验。
在执行新任务时,智能体不再是从零开始,而是能够通过检索相似的过往经验,利用上下文学习指导当前的决策路径。
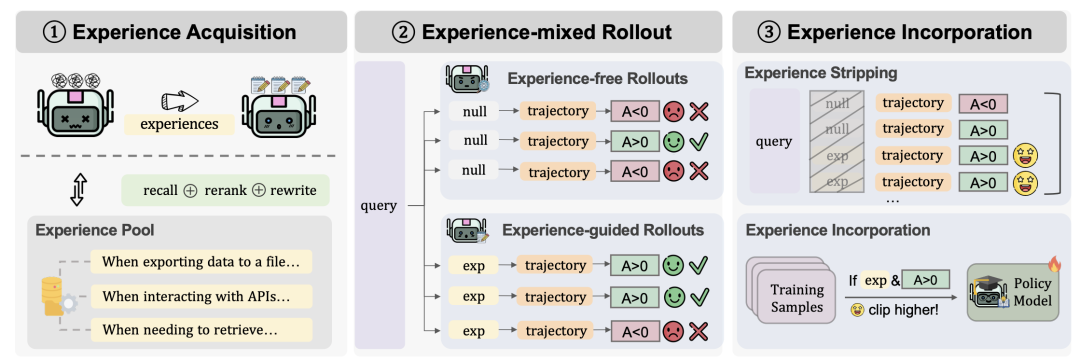
这种机制让智能体具备了“举一反三”的能力,能够避开已知的错误路径,显著提高了探索成功率。
而在执行环节之外,如何从成败中提取精准的反馈信号,同样是决定进化质量的关键。
针对长程任务中往往只有做完最后一步才知道成败的奖励稀疏痛点,AgentEvolver设计了自我归因(Self-Attributing)机制。
系统引入了基于LLM的过程奖励模型,不再粗放地依赖最终结果,而是对轨迹中的每一个动作步骤进行细粒度的因果分析和打分。

这种机制将粗粒度的结果奖励转化为细粒度的过程监督信号,极大地提升了策略优化的样本效率,确保每一次尝试都能转化为有效的学习信号。
GitHub:https://github.com/modelscope/AgentEvolver
技术报告:https://arxiv.org/abs/2511.10395
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🔊 聊AI,当然得来量子位MEET2026智能未来大会!
张亚勤、孙茂松等首波AI行业重磅嘉宾已确认出席,还有更多嘉宾即将揭晓 👉 了解详情
📍 12月10日
📍 北京金茂万丽酒店
一键报名线下参会,期待与你共论AI行业破局之道 

🌟 点亮星标 🌟
科技前沿进展每日见



















 23
23

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









