



闻乐 发自 凹非寺
量子位 | 公众号 QbitAI
单Transformer搞定任意视图3D重建!
这是字节Seed康炳易团队带来的最新研究成果Depth Anything 3(下称DA3),获谢赛宁盛赞。

架构足够简单,核心能力却不差。能从一张图、一组多视角照片甚至一段随手拍的视频里,精准算出物体深度、还原相机位置,不仅能拼出完整3D场景,还能脑补出没拍过的新视角图像。
而且,它在团队全新打造的视觉几何基准上横扫所有任务,相机定位精度平均提升35.7%,几何重建准确率涨了23.6%,单目深度估计还超越了自家前代DA2。

以前的3D视觉模型,想做单图深度估计?得单独训练一个模型;想搞多视角3D重建?又要换一套架构。
就连算个相机位置都得搭专属模块,不仅开发成本高,还没法充分利用大规模预训练模型的优势,数据依赖也很严重。

还有就是这些模型往往“术业有专攻”,那DA3的单一极简操作究竟是怎样的呢?
极简设计也能打
核心秘诀就两点:一是只用一个普通的视觉Transformer当基础;二是预测目标只抓深度和光线两个核心。
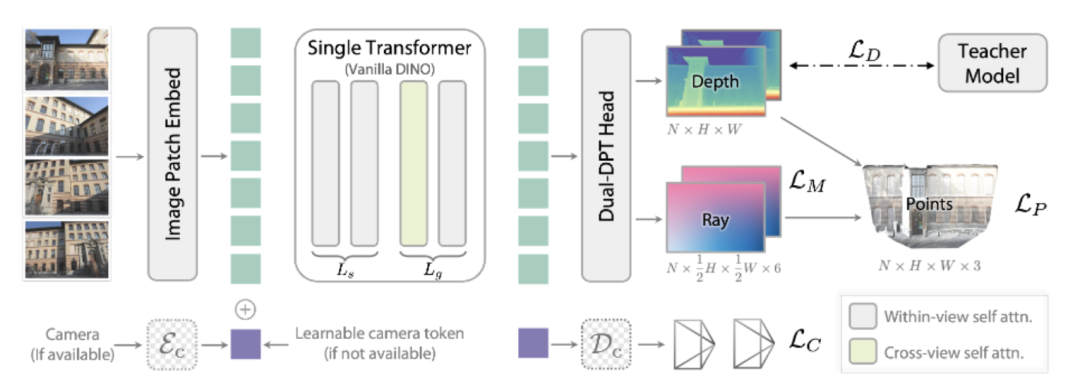
从架构图上可以看出来,DA3的任务流程可分为四大环节。
首先是输入处理,多视角图像会被送入Image Patch Embed模块转化为特征块,同时若有相机参数则通过编码器,没有则用可学习的相机token替代,最终图像特征与相机信息特征拼接融合。
中间的Single Transformer (Vanilla DINO)是模型的核心大脑。它是基于预训练的DINO视觉Transformer,通过Within-view self attn单视角自注意力、Cross-view self attn跨视角自注意力两种注意力机制,让模型能在单图、多图、视频等不同输入形式下,自动打通视角间的信息关联。
之后,Transformer输出的特征被送入Dual DPRT Head两个任务头,一方面输出深度图,另一方面输出光线参数,同时完成深度和光线两个核心预测。
此外,还会从特征中提取相机姿态信息,确保相机轨迹精准。

在训练环节上,DA3采用了师生蒸馏策略。用一个性能更优的教师模型从海量数据中提炼高质量伪标签,再用这套标准答案引导学生模型(即DA3)学习。
这种方式既能充分利用多样化数据,又能降低对高精度标注数据的依赖,让模型在训练阶段就能覆盖更多场景。
字节团队还专门搭了个全新的视觉几何基准,整合了5个覆盖室内、室外、物体级的数据集,从相机定位、3D重建到新视角生成,全方位考验模型实力。
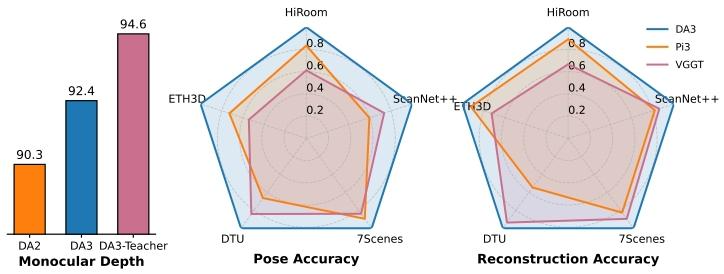
评测结果就是DA3全程能打。给一段视频,它能精准估计每帧的相机内参与外参,还原每帧相机的运动轨迹;
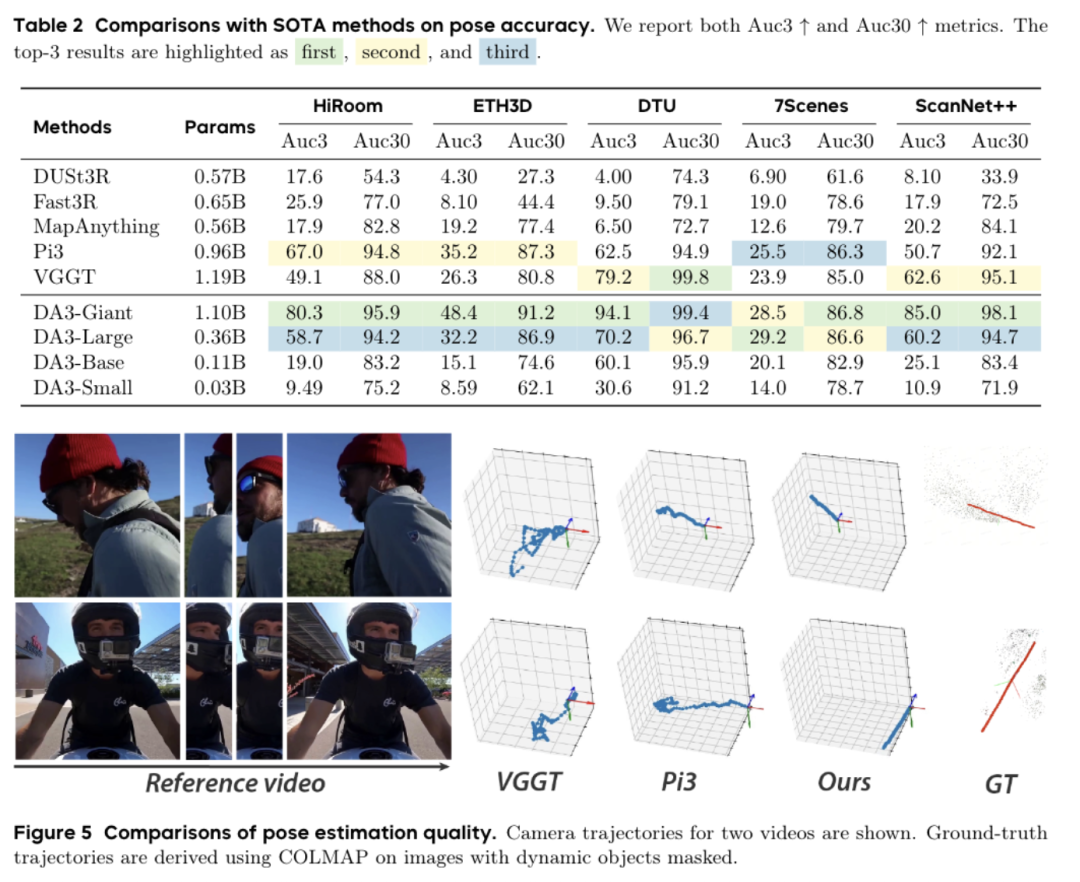
将其输出的深度图与相机位置结合,能生成密度更高、噪声更低的3D点云,比传统方法的点云质量提升明显;

甚至给几张同一场景的散图,它也能通过视角补全,生成未拍摄角度的图像,这在虚拟漫游、数字孪生等场景中潜力不小。
团队介绍
Depth Anything 3项目的带队人是字节跳动95后研究科学家康炳易。他的研究兴趣为计算机视觉、多模态模型,致力于开发能从各种观察中获取知识并与物理世界交互的智能体。

2016年,他在浙大完成本科学业,后在加州伯克利和新国立(师从冯佳时)攻读人工智能专业硕博。
读博期间,他曾在Facebook AI Research实习,与谢赛宁、马库斯等人有过合作。
康炳易领导开发Depth Anything系列,之前还被收入苹果CoreML库中。
论文地址:https://arxiv.org/abs/2511.10647
参考链接:
[1]https://x.com/bingyikang/status/1989358267668336841
[2]https://x.com/sainingxie/status/1989423686882136498
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🔊 聊AI,当然得来量子位MEET2026智能未来大会!
张亚勤、孙茂松等首波AI行业重磅嘉宾已确认出席,还有更多嘉宾即将揭晓 👉 了解详情
📍 12月10日
📍 北京金茂万丽酒店
一键报名线下参会,期待与你共论AI行业破局之道 

🌟 点亮星标 🌟
科技前沿进展每日见



















 23
23

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









