




一凡 发自 凹非寺
量子位 | 公众号 QbitAI
自动驾驶实现垂直领域的AGI,有了新路径。
不是Robotaxi,而是RoadAGI。
在英伟达GTC 2025上,元戎启行CEO周光受邀分享,提出用RoadAGI,能更快大规模商用自动驾驶,实现垂直道路场景下的AGI,RoadAGI的实施平台,是元戎最新分享的AI Spark:
不借助高精地图,一个平台赋能智能车、机器人甚至小电驴……总之,一切可动的移动体,都将具有自主移动的意识。
这是一条通过自动驾驶实现AGI的新途径。
元戎启行和CEO周光,代表AI公司、自动驾驶公司,开辟起了第二种可能性。
所以RoadAGI究竟是什么?
用RoadAGI迈向AGI
先说人人可感知的场景——
你下一次点的外卖,可能是这样的:

赛博“外卖小哥”,全程不用高精地图,自动识别店铺:

拿到商品后,一溜小跑到路口,自主识别到红绿灯:

然后一停二看三通过:

它还能进到楼里,自己过闸机、摁电梯:

然后到电梯里,再自己摁楼层:

出电梯直接给你送到公司前台:

整个过程,是不是跟咱们人一样?
你也可以让它把商品放外卖柜里:

这就是元戎启行在英伟达GTC 2025上,分享的物理AI最新进展:
RoadAGI。
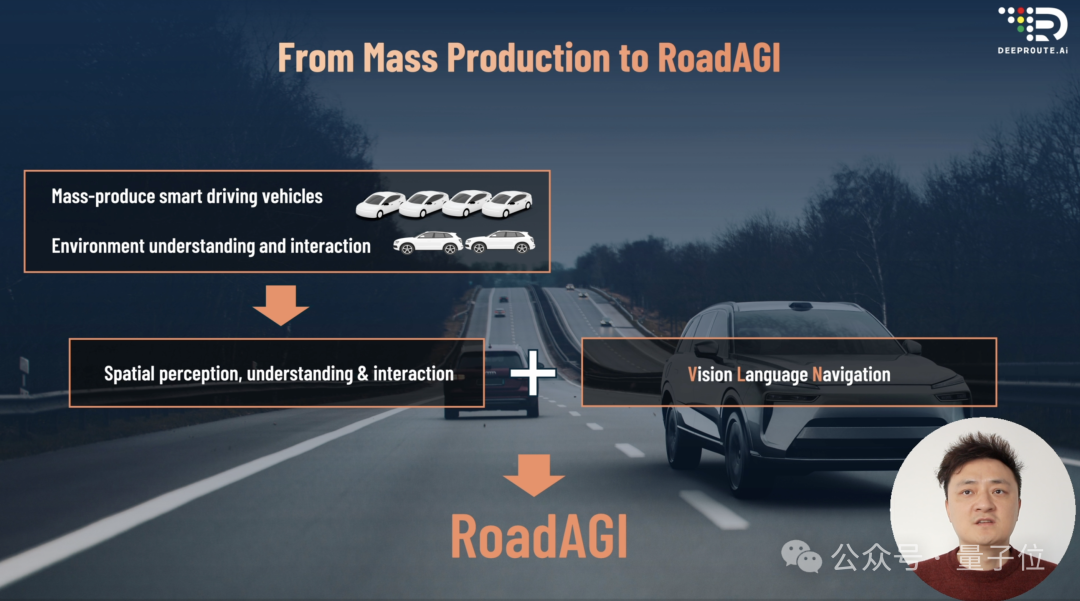
用一套AI底座,解决路上的所有移动体,实现垂直道路场景下的AGI。
前面展示的是RoadAGI落地的第一个形态Spark 1.0,看着很像无人配送车,但是据了解有本质不同。
首先,技术上,其移动不依赖高精地图,在导航的指引下,自主识别周边环境信息,就能实现“门到门”位移。
为什么不需要扫图?
因为元戎把技术底座VLA走通了。
VLA,即视觉语言动作模型,是端到端的最新成果,预计今年年中量产上车。
新范式已得到了行业头部的响应,比如理想汽车,隐隐成为行业共识。
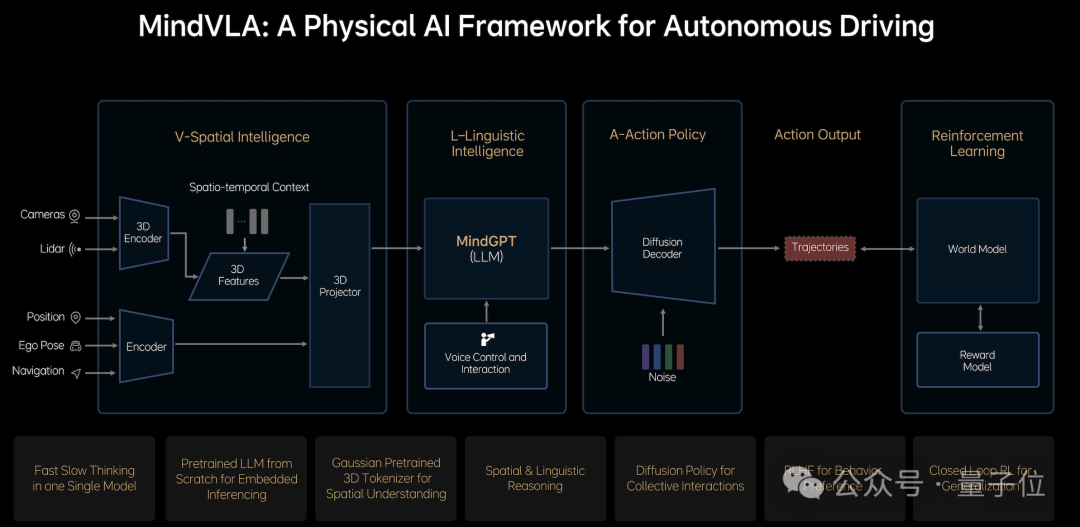
VLA用一个多模态模型,统一过去的视觉语言模型和端到端,将道路图像信息和文本指示融合处理,输出驾驶行为和文字。
这意味着,VLA打通了空间智能、语言智能和行为智能。
因此,VLA加持的移动体,改善了配送体验。
以往的无人配送,只是负责配送的一个环节,只能做到“楼到楼”。你买个东西,还要自己下楼取。
现在不一样了,直接实现“门到门”,整个配送流程闭环了。
但问题是,元戎启行作为端到端智驾的代表性公司,智能驾驶领域的竞速正在如火如荼,怎么就此时此刻开辟起第二曲线来了?
围绕最新战略,量子位进一步与周光展开了对话。
周光说,根本上是因为元戎从不将自己当作智驾公司,而是一家AI公司。
智驾只不过是实现物理AI的商业化选择,元戎已取得了不错的进展:
在国内最早摆脱高精地图依赖,率先转向端到端,去年首个量产车型上市后成为爆款,凭借单款车型获取了城区NOA市场15%的份额。
智驾爆款让元戎的数据飞轮加速转动。
经过4000万公里的智驾数据积累后,元戎的AI能力更加通用,是时候向上走,实现RoadAGI,向物理AI再迈一步了。
周光认为,RoadAGI的出现一定早于L5,不过这还不算实现物理AI,只是解决了道路场景。
而当实现物理AI,并将其与生成式AI和语言AI打通时,真正的AGI就到来了。
以下为对话实录整理,内容较长,可参考目录阅读:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 18
18

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









