 Ada-KV优化KV缓存压缩提升推理效率
Ada-KV优化KV缓存压缩提升推理效率




中科大博士冯源 投稿
量子位 | 公众号 QbitAI
改进KV缓存压缩,大模型推理显存瓶颈迎来新突破——
中科大研究团队提出Ada-KV,通过自适应预算分配算法来优化KV缓存的驱逐过程,以提高推理效率。
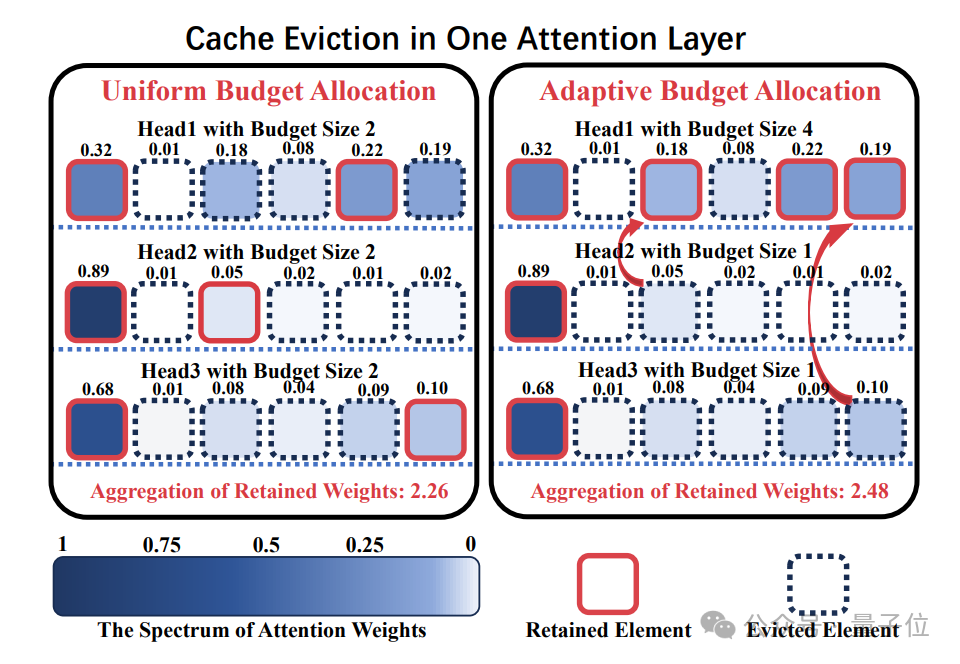
打破KV Cache压缩将所有注意力头分配相同压缩预算的常规做法,针对不同的注意力头进行适配性压缩预算分配

展开来说,由于大模型在自回归生成过程中,每生成一个新token都需要将对应的KV矩阵存储下来,这导致缓存随着生成序列长度的增加而急剧膨胀,引发内存和I/O延迟问题,尤其在长序列推理中尤为突出。
因此,KV缓存压缩成为了一项必要的优化。
不过令人头秃的是,现有压缩方法往往在各个注意力头之间平均分配预算,未能考虑其特性差异。
而中科大团队在注意到——不同注意力头关注度存在差异后,对其进行适配性压缩预算分配,通过精细化运作带来更高的压缩质量。
相关研究不仅在学术界引起讨论,更实现了工业界开源落地。
例如,Cloudflare workers AI团队进一步将其改进落地于工业部署常用的vLLM框架中,并发布技术报告,开源全部代码。

KV缓存压缩从均匀性预算分配→适配性预算分配
一开始,Ada-KV团队首先思考:
注意力头间的适配性压缩预算分配是必要的吗?
通过从经验性和理论性两个角度进行分析后,团队的回答是:yes!
经验性分析
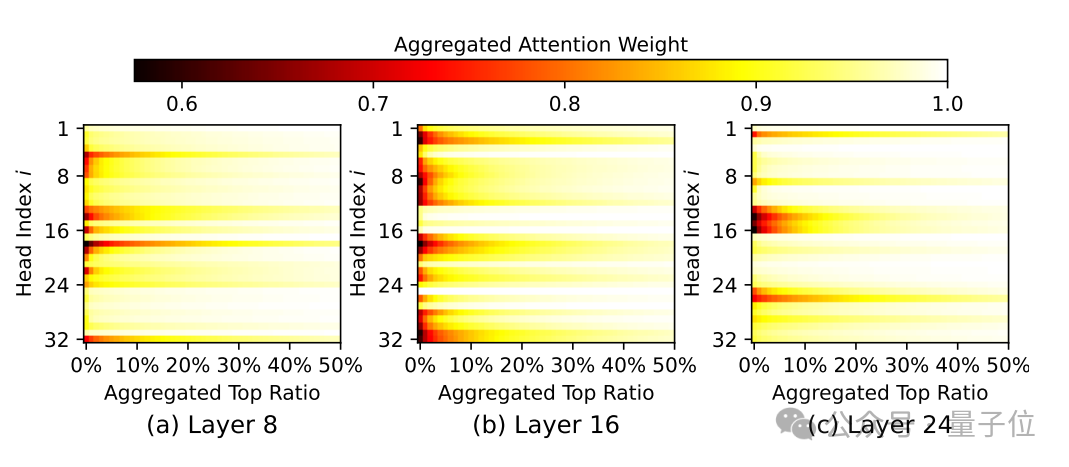
Ada-KV团队发现,在大模型中注意力头之间存在着显著不同的关注集中度差异:
大部分注意力头关注度集中在少量KV cache上,只需很少的KV cache(例如,1%)就可以几乎收集接近0.9的注意力权重;
而少数注意力头则倾向于分散注意力,往往需要接近50%的KV Cache才能够将注意力权重聚集到0.9。
考虑到如此巨大的关注度集中度的差异,注意力头间的适配性压缩预算分配对于压缩质量的提升有着巨大潜力。
理论性分析
Ada-KV研究团队进一步从压缩输出损失的角度出发,形式化了在不同分配策略下KV Cache压缩对注意力输出的损失影响:
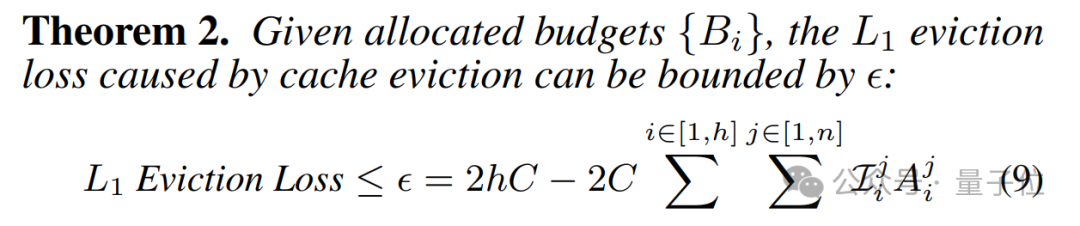
他们基于这一理论提出了一种以注意力权重为基础的自适应分配方案,并发现这种跨注意力头的预算分配策略始终能够降低损失上界。
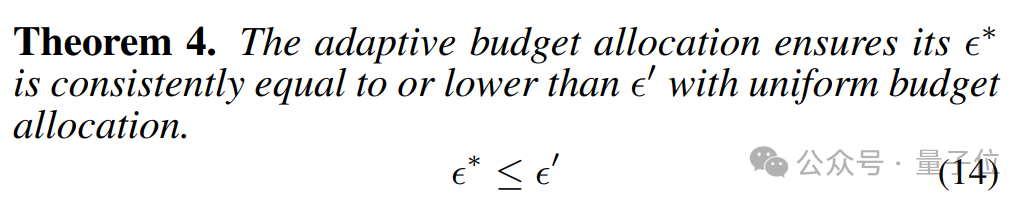
此外,这一理论上的更低损失上界在实际实验中也展现出更低的注意力输出损失:
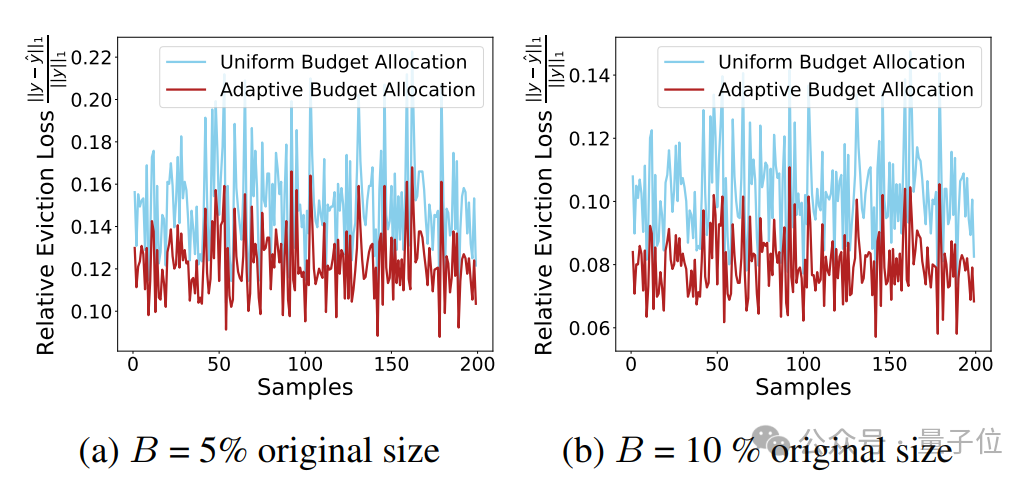
理论与实际结果一致验证了这一结论:注意力头间的适配性预算分配能够显著提升KV缓存压缩的效果。
通过适配性头间预算分配增强KV Cache压缩质量
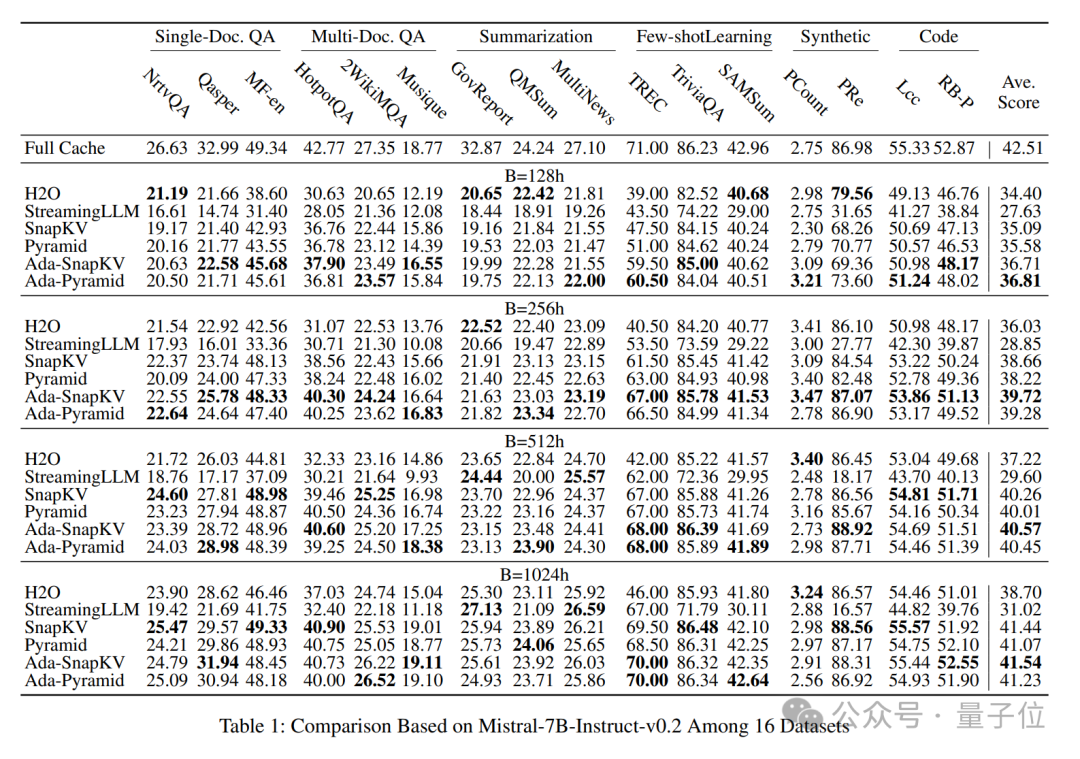
作者将Ada-KV这一适配性预算分配策略结合到现有的两个领先的Cache压缩方案:SnapKV和PyramidKV中,分别得到两种适配性压缩方案:Ada-SnapKV和Ada-Pyramid。
他们进一步在广泛使用的长序列开源大模型Mistral-7B-Instruct-32K和LWM-Text-Chat-1M和长文本任务评估基准LongBench上的16个数据集上进行了充分的评估。
实验结果显示,所有适配性预算分配增强的压缩方法(Ada-SnapKV和Ada-Pyramid)全部优于原有的均匀预算分配压缩方法(SnapKV和Pyramid)。
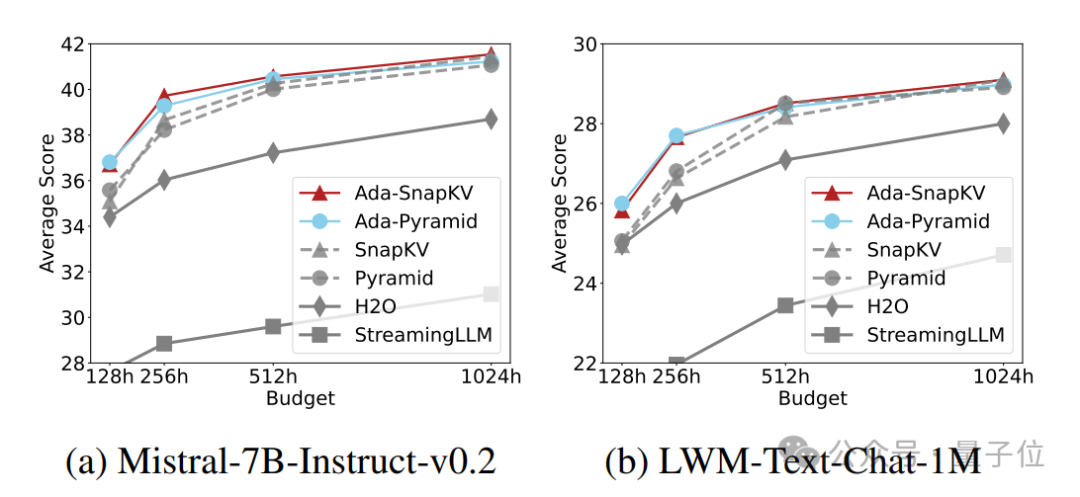
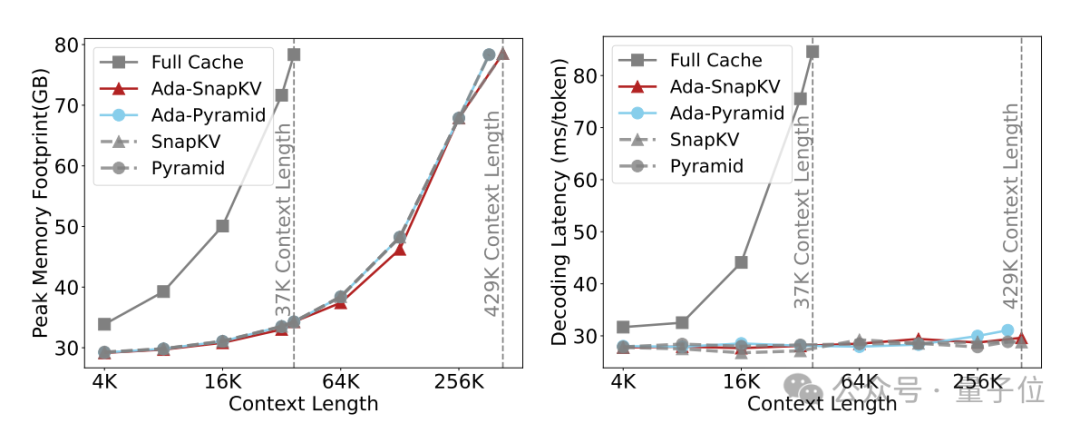
Ada-KV团队在算法实现的同时,也考虑到了执行效率的优化。
他们开发了一种展平的KV Cache管理布局,并定制了CUDA kernel,以实现高效的Cache更新管理。
结合Flash Attention技术,该方案在适应性预算分配的情况下,实现了高效推理,并在相同预算下保持了与先前Cache压缩方案一致的计算效率。
目前,代码已在GitHub上完全开源,助力推动注意力头间适应性压缩预算分配的研究。
Cloudflare推动Ada-KV于工业界部署落地
Cloudflare公司旗下的Workers AI团队针对实际并发服务场景中存在的内存碎片问题,基于Paged Attention重新实现了Ada-KV算法,并将其落地于实际部署使用的推理框架vLLM中。
他们发布了技术报告,对该方案进行了详细评估,同时开源了相关代码,助力Ada-KV在工业界的快速应用和落地。
如果你对后续进展感兴趣,欢迎持续关注~
Ada-KV Paper:
https://arxiv.org/abs/2407.11550
Ada-KV Code:
https://github.com/FFY0/AdaKV
Cloudflare Technical Report:
https://arxiv.org/abs/2410.00161
Cloudflare Code:
https://github.com/IsaacRe/vllm-kvcompress



















 23
23

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









