



 文章探讨了联邦学习中由于数据异质性导致的维度坍缩问题,影响模型性能。研究者发现并分析了数据异质化如何加剧维度坍缩,并提出了FedDecorr,一个新的正则项,能有效缓解这一问题。FedDecorr通过约束局部模型的表征相关系数,提升全局模型的表达能力,实现在不同数据集上的性能提升,且具有计算效率高、易实现的特点。
文章探讨了联邦学习中由于数据异质性导致的维度坍缩问题,影响模型性能。研究者发现并分析了数据异质化如何加剧维度坍缩,并提出了FedDecorr,一个新的正则项,能有效缓解这一问题。FedDecorr通过约束局部模型的表征相关系数,提升全局模型的表达能力,实现在不同数据集上的性能提升,且具有计算效率高、易实现的特点。
施宇钧NUS 投稿
量子位 | 公众号 QbitAI
随着深度学习大获成功,保护用户数据隐私变得越来越重要。
联邦学习(Federated Learning)应运而生,这是一种基于隐私保护的分布式机器学习框架。
它可以让原始数据保留在本地,让多方联合共享模型训练。

但它有一个问题——数据的异质化(data heterogeneity),即不同的参与方的本地数据来自不同的分布,这将严重影响全局模型的最终性能,背后原因也十分复杂。
字节跳动、新加坡国立大学及中科院自动化所的学者们首次发现了关键影响因素。
即:数据异质化导致了表征的维度坍缩(dimensional collapse),由此大大限制了模型的表达能力,影响了最终全局模型的性能。
为了缓解这一问题,研究人员提出了一个新联邦学习正则项:FedDecorr。
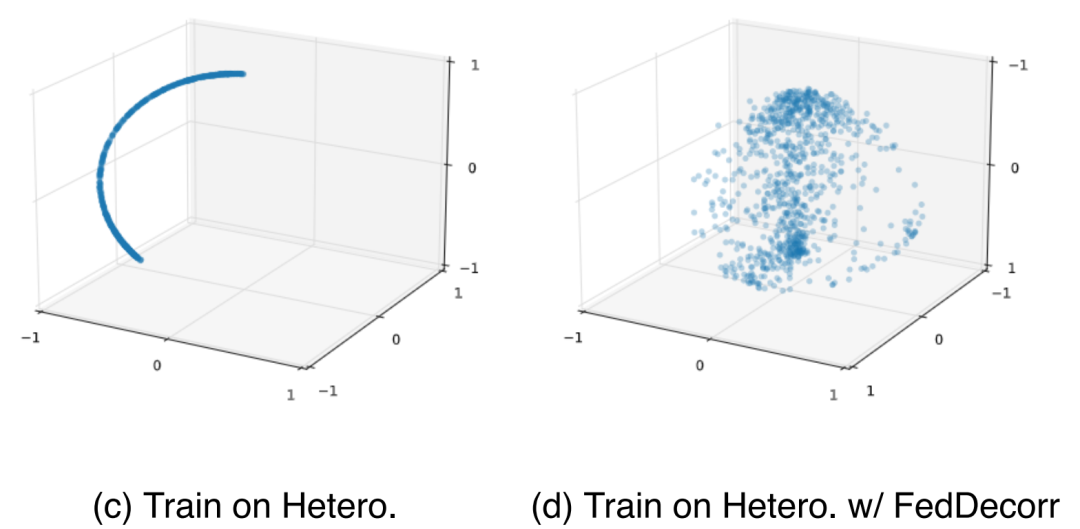
结果表明,使用该方法后,数据异质化带来的维度坍缩问题被有效缓解,显著提升模型在该场景下的性能。
同时这一方法实现简单,几乎不会带来额外计算负担,可以很容易地加入到多种联邦学习算法上。
如何影响?
观察一:更严重的数据异质化会为全局模型(global model)带来更严重的维度坍缩
首先,为了更好地理解数据异质化是如何影响全局模型输出表征的,研究人员探索了随着数据异质化越来越严重,全局模型输出表征是如何而变化的。
基于模型输出的表征,估计其表征分布的协方差矩阵(covariance matrix),并且按照从大到小的顺序可视化了该协方差矩阵的特征值。结果如下图所示。α越小,异质化程度越高,α为正无穷时为同质化场景。k为特征值的index。
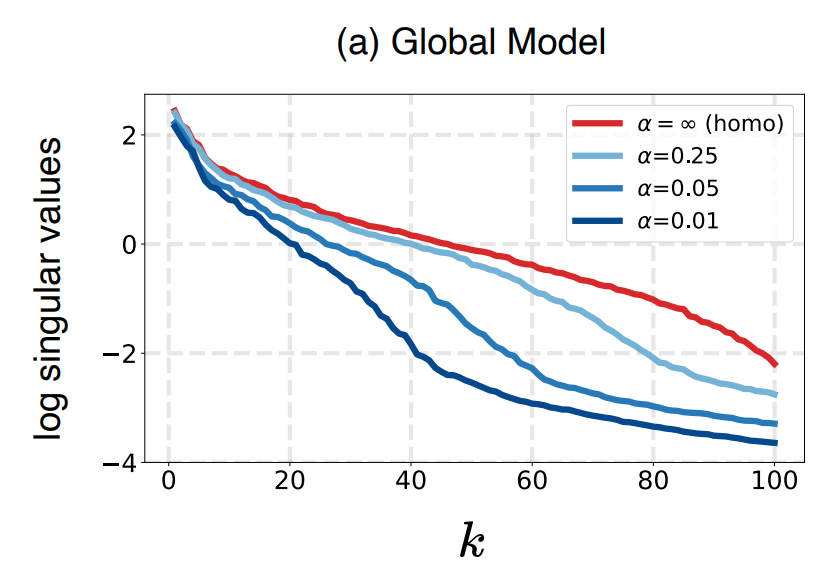
对于该曲线,如果特征值大部分相对较大,即意味着表征能够更加均匀地分布在不同的特征方向上。而如果该曲线只有前面少数特征值较大,而后面大部分特征值都很小,就意味着表征分布被压缩在少数特征方向上,即维度坍缩现象。
因此,从图中可以看到,随着数据异质化程度越来越高(α越来越小),维度坍缩的现象就越来越严重。
观察二:全局模型的维度坍缩来自联邦参与各方的局部模型的维度坍缩
由于全局模型是联邦参与各方的局部模型融合的结果,因此作者推断:全局模型的维度坍缩来源于联邦参与各方的局部模型的维度坍缩。
为了进一步验证该推断,作者使用与观察1类似的方法,针对不同程度数据异质化场景下得到的局部模型进行了可视化。结果如下图所示。
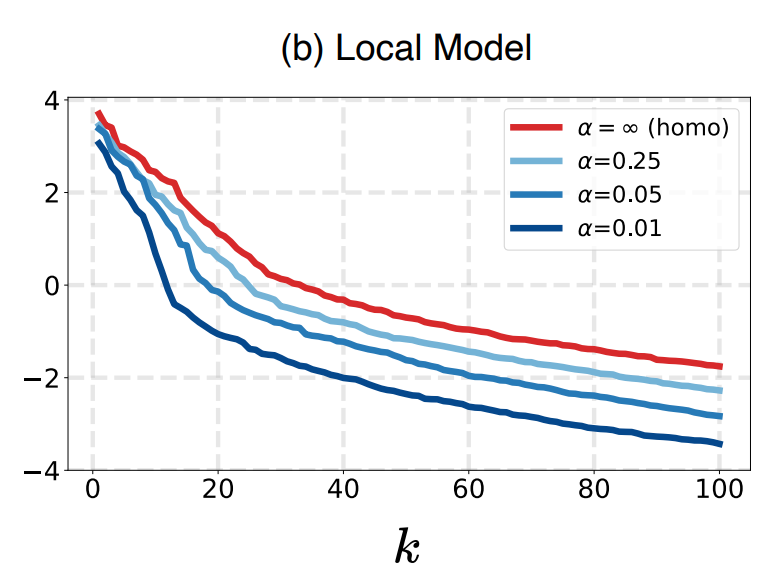
从图中可以看到,对于局部模型,随着数据异质化程度的提升,维度坍缩的现象也越来越严重。因此得出结论,全局模型的维度坍缩来源于联邦参与各方的局部模型的维度坍缩。
怎么解决?
受到以上两个观察的启发,由于全局模型的维度坍缩来源于本地局部模型的维度坍缩,研究人员提出在本地训练阶段来解决联邦学习中的表征维度坍缩问题。
首先,一个最直观的可用的正则项为以下形式:
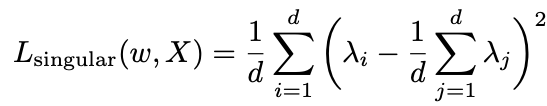
其中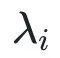 为第
为第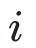 个特征值。该正则项将约束特征值之间的方差变小,从而使得较小的特征值不会偏向于0,由此缓解维度坍缩。
个特征值。该正则项将约束特征值之间的方差变小,从而使得较小的特征值不会偏向于0,由此缓解维度坍缩。
然而,直接计算特征值往往会带来数值不稳定,计算时间较长等问题。因此借助以下proposition来改进方法。
为了方便处理,需要对表征向量做z-score归一化。这将使得协方差矩阵变成相关系数矩阵(对角线元素都是1)。
基于这个背景,可以得到以下proposition:
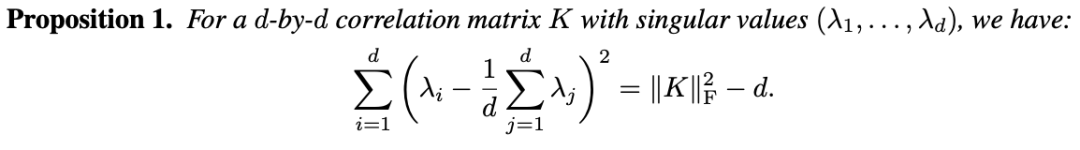
这一proposition意味着,原本较为复杂的基于特征值的正则化项,可以被转化为以下易于实现且计算方便的目标:
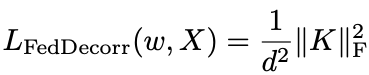
该正则项即是简单的约束表征的相关系数矩阵的Frobenius norm更小。研究人员将该方法命名为FedDecorr。
因此,对于每个联邦学习参与方,本地的优化目标为:
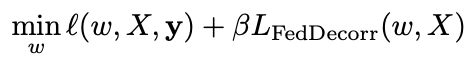
其中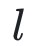 为分类的交叉熵损失函数,β为一个超参数,即FedDecorr正则项的系数。
为分类的交叉熵损失函数,β为一个超参数,即FedDecorr正则项的系数。
实验结果
首先,验证使用FedDecorr是否可以有效缓解维度坍缩。
在α=0.01/0.05这两个强数据异质化的场景下,观察使用FedDecorr对模型输出表征的影响。
结果如下图所示。
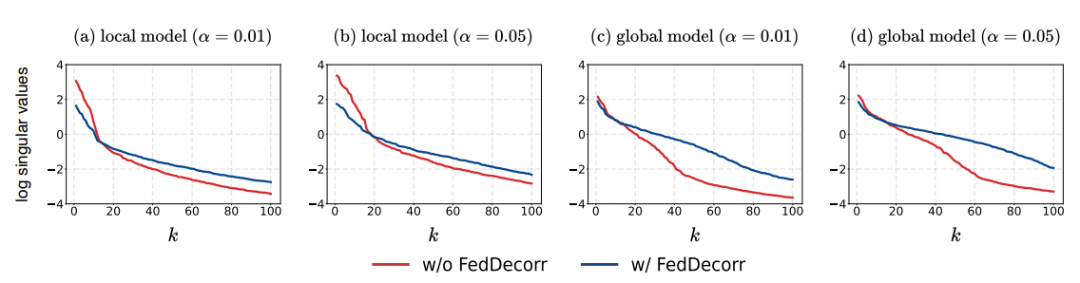
可以看到,使用FedDecorr可以有效地缓解本地局部模型的维度坍缩,从而进一步缓解全局模型的维度坍缩。
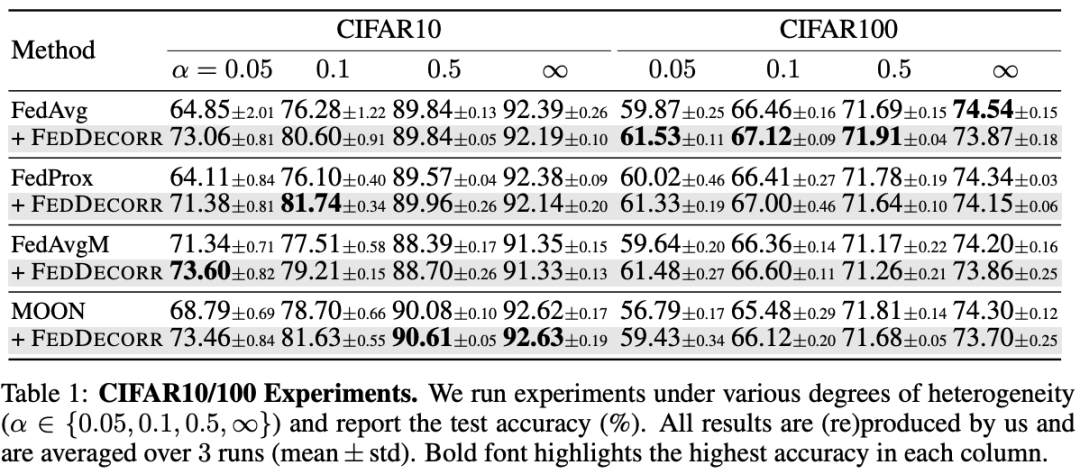
在CIFAR10/100两个数据集上验证方法。研究团队发现FedDecorr可以很方便的加入到之前提出的多个联邦学习方法,并且带来显著提升:
同时,为了展示方法的可扩展性,作者在较大规模数据集(TinyImageNet)上进行了实验,并且也观察到了显著提升:
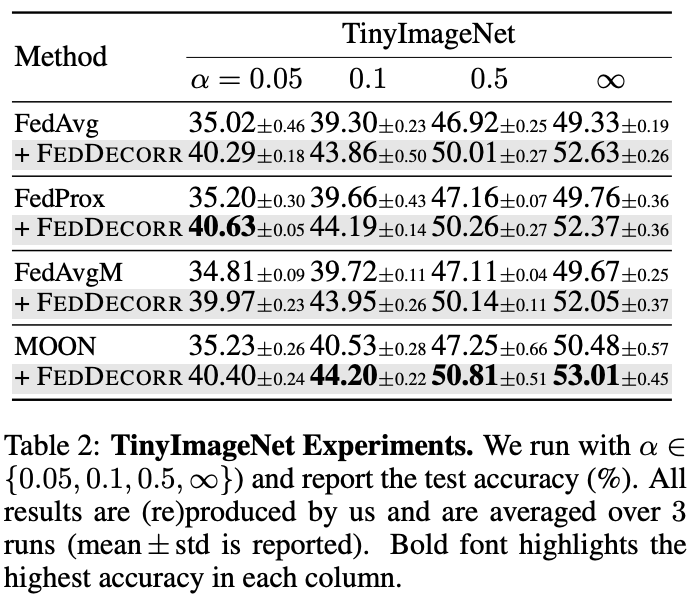
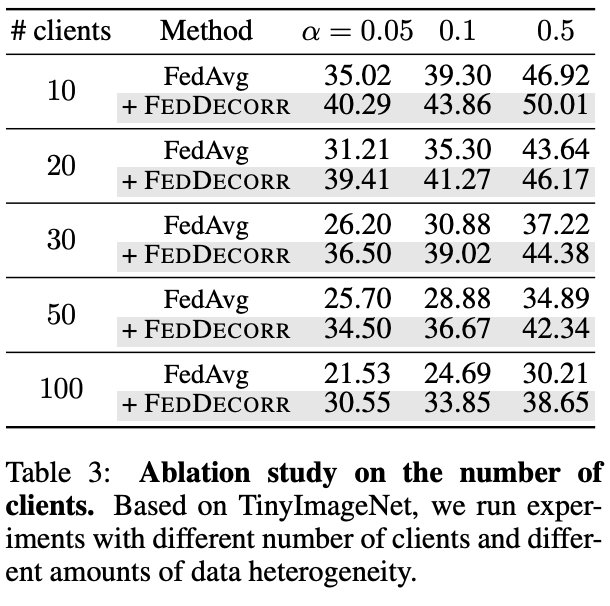
此外还基于TinyImageNet,验证了FedDecorr在更大规模联邦参与方的场景下的有效性。
结果如下表。通过实验结果展示了FedDecorr可以被用于较大规模联邦参与方的场景。
FedDecorr对正则项系数(超参数β)的鲁棒性结果如下图所示。
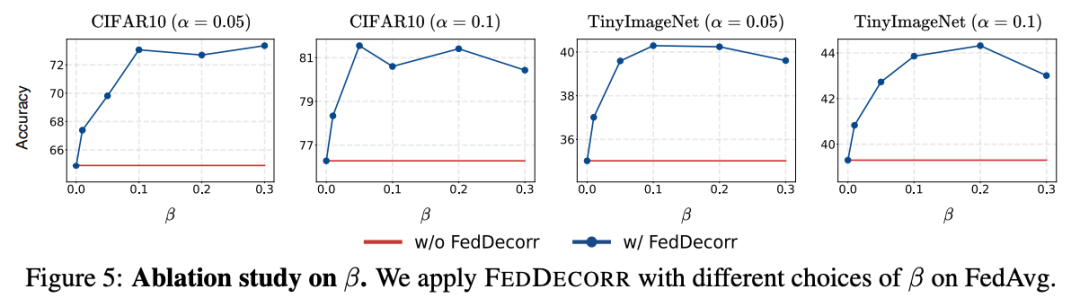
通过实验,发现FedDecorr对于其超参数β有较强的鲁棒性。
同时发现将β设为0.1是一个不错的默认值。
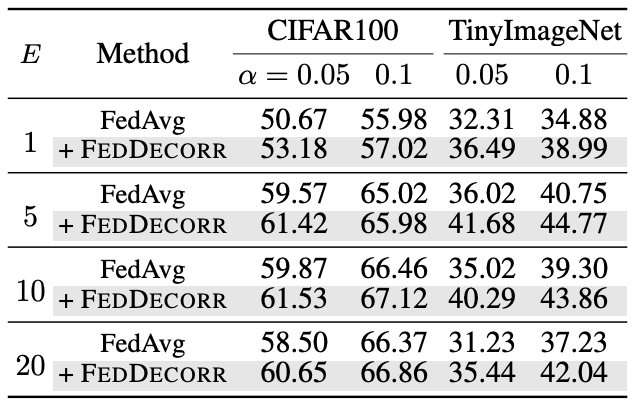
最后,研究人员验证了在联邦学习时,使用不同的local epoch下FedDecorr也可以带来普遍的提升:
论文地址:
https://arxiv.org/abs/2210.00226
代码链接:
https://github.com/bytedance/FedDecorr



















 43
43

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









